토큰을 출력할수록 정보가 손실된다면
- Latent Collaboration in Multi-Agent Systems, ICML 2026(Spotlight), arXiv.
- Recursive Multi-Agent Systems, preprint 2026, arXiv.
Multi-Agent System(MAS)의 동작을 떠올려봐요. Planner 에이전트가 “이 문제는 두 단계로 풀어야 해. 먼저 X를 계산하고, 그 결과를 Y에 대입해”라고 텍스트로 써서 Solver에게 넘겨요. 그런데 Planner의 내부(=hidden state)에는 “X와 Y의 관계가 비선형이고, 경계 조건은 이렇고…”라는 훨씬 풍부한 정보가 있어요. 토큰으로 변환되는 순간 그 정보는 사라지고, Solver는 짧은 텍스트를 다시 읽어 자기 hidden state로 복원해야 해요. 이 round-trip이 매 협력 단계마다 반복돼요.
LatentMAS는 이 round-trip을 없애요. 에이전트가 토큰 디코딩 없이 hidden state를 그대로 이어서 사고하고, 다른 에이전트에게는 KV cache 자체를 넘겨요. 학습 없이 ridge regression 한 번으로 분포 차이만 보정하면 끝이에요. RecursiveMAS는 여기서 한 발 더 나아가요. “다시 첫 에이전트로 돌려보내서 몇 바퀴 더 굴리면 어떨까”라는 질문에서 출발해, 가벼운 RecursiveLink 모듈만 학습해서 시스템 단위의 재귀 깊이를 만들어요.
왜 LatentMAS는 latent space를 쓸까
MAS 연구를 해 본 분이라면, 에이전트들이 자연어로 메모를 주고받는 구조가 얼마나 비효율적인지 체감했을 거예요. CoT 한 줄을 만들기 위해 모델은 마지막 hidden state $h_t \in \mathbb{R}^{d_h}$를 $W_\text{out} \in \mathbb{R}^{d_h \times |\mathcal{V}|}$로 project해 softmax 후 한 토큰을 뽑고, 그 토큰을 다시 $W_\text{in}$으로 임베딩해 다음 step의 입력으로 써요. 이 round-trip이 매 토큰마다 반복돼요. 이 구조에는 세 가지 병목이 있어요. 첫째, $d_h$차원 분포를 $\log_2 |\mathcal{V}|$비트로 압축해요. 여기서 $|\mathcal{V}|$는 vocabulary 크기에요. 둘째, 매 step $|\mathcal{V}| d_h$ FLOPs의 projection 비용이 들어요. 셋째, 자연어의 모호함을 그대로 다음 에이전트에게 넘겨요.
LatentMAS는 디코더에서 발생하는 비효율을 해결해요. 토큰을 거치지 않고 마지막 레이어 hidden state를 그대로 다음 step의 입력으로 쓰면, 같은 step 수로 훨씬 더 많은 정보를 운반할 수 있어요. 에이전트 사이의 메시지도 KV cache 자체를 옮기면 디코딩과 재인코딩이 통째로 사라져요. 논문은 이 직관을 세 원칙으로 설명해요.
- Reasoning Expressiveness: hidden state는 토큰보다 풍부한 정보를 담아요.
- Communication Fidelity: KV로 working memory를 넘겨 중복 연산이 없어요.
- Collaboration Complexity: 같은 표현력을 달성하는 데 텍스트 MAS보다 낮은 시간 복잡도를 가져요.
그리고 이 모든 게 추가 학습 없이 동작해요. Theorem 3.1은 토큰보다 latent space의 정보 표현력이 더 뛰어나다는 것을 보여줘요. Linear Representation Hypothesis를 가정하면, 길이 $m$의 latent thought 시퀀스를 텍스트로 표현하기 위해서 다음과 같은 토큰 수를 필요로 해요.
\[\Omega\!\left(\frac{d_h \, m}{\log|\mathcal{V}|}\right)\]즉 한 latent step은 텍스트의 $O(d_h / \log|\mathcal{V}|)$배 정보를 담을 수 있어요. Qwen3-4B/8B/14B의 $d_h$=2560/4096/5120과 $|\mathcal{V}|\approx 151\text{K}$로 계산하면 각각 235.7 / 377.1 / 471.4배 효율이에요. 직관적으로 보면, 한 latent step은 $d_h$개의 직교하는 개념을 동시에 활성화해 $d_h$비트 규모의 정보를 운반하지만, 토큰 하나는 $\log_2|\mathcal{V}|$비트뿐이에요.
LatentMAS는 어떻게 동작할까
LatentMAS의 한 사이클은 두 단계로 나뉘어요. 에이전트 내부의 latent thought 생성, 그리고 에이전트 사이의 KV working memory 전송이에요.
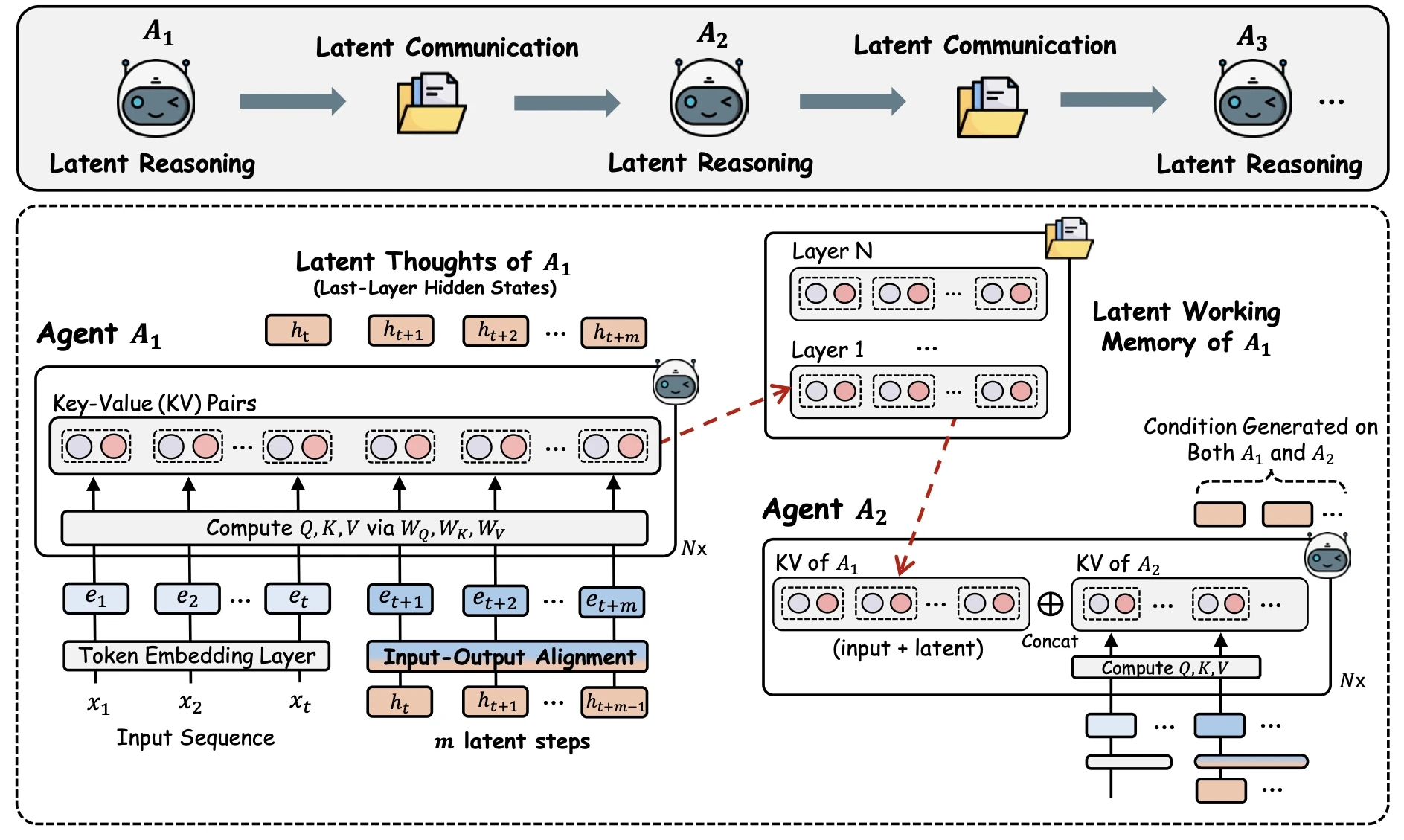
Latent thought 생성. 각 에이전트 $A_i$는 질문 $q$와 역할 prompt를 합친 입력 임베딩 $E=[e_1, \dots, e_t]$를 transformer에 통과시켜 마지막 레이어 표현 $h_t$를 얻어요. 토큰 디코딩 대신 $h_t$를 다음 step의 입력 임베딩으로 직접 주입해 $m$번 반복하면, $H = [h_{t+1}, \dots, h_{t+m}]$이라는 latent thought 시퀀스가 만들어져요.
하지만 $h_t$는 출력 분포에 위치해 입력 임베딩 분포와 통계적으로 어긋나요. 그대로 다음 step의 입력으로 넣으면 레이어에서 Out-of-Distribution activation이 발생해요. LatentMAS는 이걸 선형 보정 한 번으로 풀어요. 입력 임베딩 레이어 $W_\text{in}$은 토큰을 $d_h$차원 벡터로 바꾸고, 출력 레이어 $W_\text{out}$은 $d_h$차원 hidden state를 다시 토큰 확률로 바꿔요. 이 둘은 역방향 관계에 있으니, 이상적으로는 $W_\text{out}$의 역변환을 거친 뒤 $W_\text{in}$을 적용하면 출력 분포를 입력 분포로 되돌릴 수 있어요. 즉 $W_a \approx W_\text{out}^{-1} W_\text{in}$이에요.
문제는 $W_\text{out}$이 정방 행렬이 아니라 정확한 역행렬이 존재하지 않는다는 거예요. 그래서 LatentMAS는 $W_\text{out} W_a$가 $W_\text{in}$에 최대한 가까워지도록 하는 $W_a$를 ridge regression으로 구해요. 닫힌 해(closed-form solution)가 있어서 모델당 한 번만 계산하면 모든 latent step에서 재사용할 수 있어요. 학습 루프 없이 행렬 연산 한 번으로 끝나요. 이게 LatentMAS가 학습 없이 동작할 수 있는 핵심 트릭이에요. 논문 부록의 Theorem A.1은 이 $W_a$가 token 임베딩 분포와 aligned 임베딩 분포 사이의 Wasserstein 거리 상한을 최소화한다는 걸 보여줘요.
KV working memory 전송. 토큰 출력이 없는데 다음 에이전트는 어떻게 이전 에이전트의 결론을 알 수 있을까요. LatentMAS의 답은 layer-wise KV cache 자체를 working memory로 넘기는 거예요. 에이전트 $A_1$이 $m$ step 생성을 마치면 모든 $L$개 레이어의 KV cache를
\[\mathcal{M}_{A_1} = \big\{ (K^{(l)}_{A_1, \text{cache}},\, V^{(l)}_{A_1, \text{cache}}) \,\big|\, l=1, \dots, L \big\}\]로 묶어요. 다음 에이전트 $A_2$는 자기 KV 앞에 $\mathcal{M}_{A_1}$을 layer-wise로 prepend한 뒤 자기만의 latent 생성을 시작해요. 마지막 에이전트만 텍스트로 디코딩해서 최종 답을 내요. 넘긴 경우와 $A_1$의 입력을 그대로 $A_2$에 다시 넣은 경우, 두 출력은 동치예요. 같은 모델이 같은 입력으로 만든 KV를 cache에서 읽든 다시 계산하든 결과가 같으니까요. 즉 LatentMAS의 KV 전송은 압축 손실 없는 shortcut이에요.
복잡도 비교. Theorem 3.4에 따르면, 에이전트 하나 기준 LatentMAS의 시간 복잡도는
\[O\!\big( (d_h^2 m + d_h m^2 + d_h t m) L \big)\]같은 표현력을 내려는 텍스트 MAS는
\[O\!\left( \left( \frac{d_h^3 m}{\log|\mathcal{V}|} + \frac{d_h^3 m^2}{\log^2|\mathcal{V}|} + \frac{d_h^2 t m}{\log|\mathcal{V}|} \right) L + \frac{d_h^2 |\mathcal{V}| m}{\log|\mathcal{V}|} \right)\]여기서 마지막 항 $d_h^2 |\mathcal{V}| m / \log|\mathcal{V}|$가 매번 등장하는 어휘 projection 비용이에요. LatentMAS는 이 항이 필요하지 않아져요.
LatentMAS 실험 결과
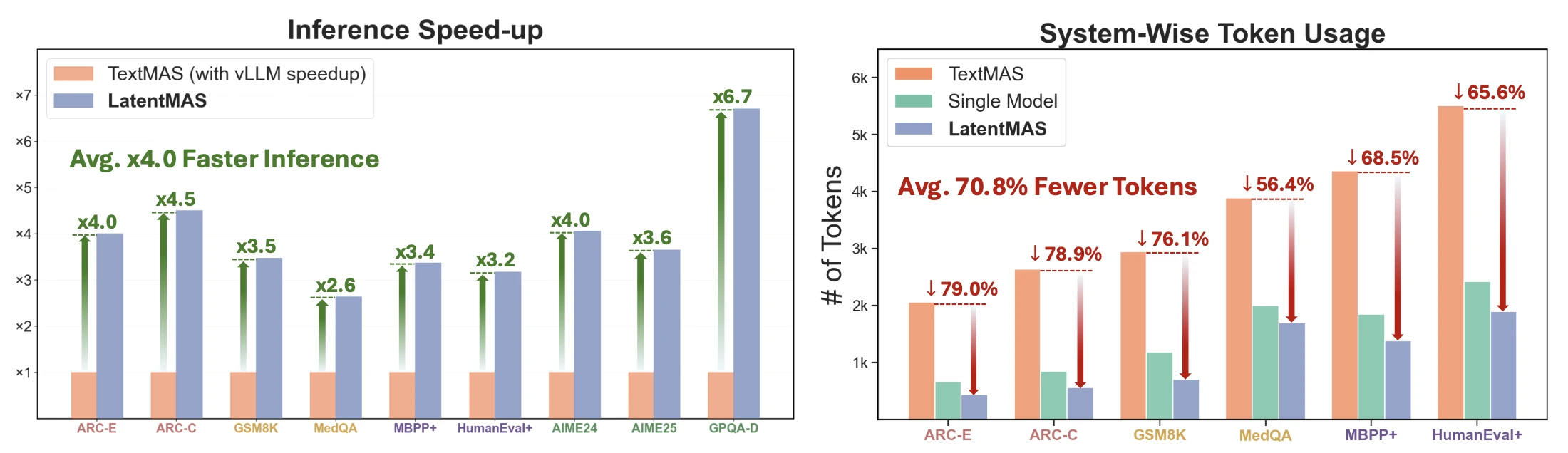
Sequential MAS(planner→critic→refiner→solver)와 Hierarchical MAS(math/code/science 전문가 → summarizer) 두 설정을 Qwen3-4B/8B/14B에 적용했어요. 9개 벤치마크에서 단일 모델·TextMAS 대비 정확도 +14.6%p까지, 평균 end-to-end inference 4× 가속, 평균 출력 토큰 70.8% 감소를 확인했어요. 학습 한 번 없이 이 모든 결과가 나온다는 점이 인상적이에요.
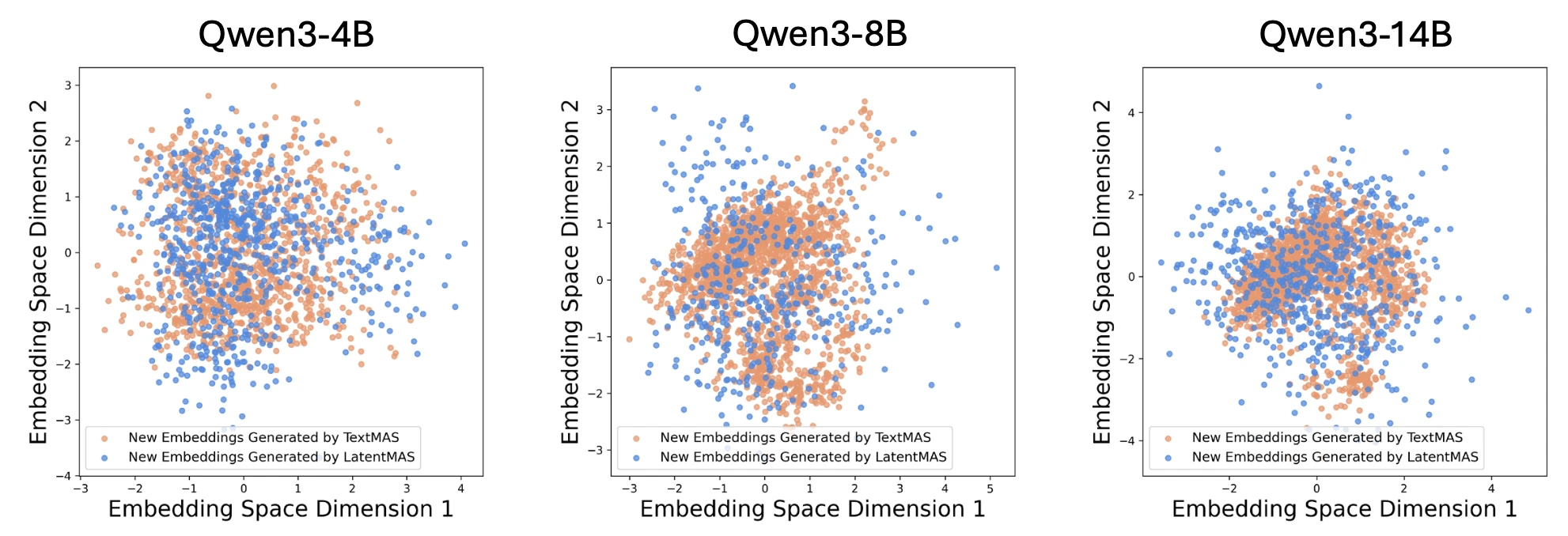
심층 분석에서는 latent thought의 의미적 일관성도 확인했어요. MedQA 300문제에 대해 LatentMAS의 last-layer 임베딩 분포와 TextMAS가 토큰 단위로 만든 임베딩 분포를 PCA로 시각화하면, 두 분포가 거의 같은 영역을 차지해요. latent thought가 텍스트 응답과 유사한 의미를 인코딩하면서도 더 넓은 영역을 커버해요. 더 다양한 표현 capacity를 가진다는 뜻이에요. latent step 수 ablation에서는 $m \approx 40\text{–}80$에서 정확도가 saturate해요. 텍스트 CoT가 4096 토큰 budget을 다 쓰는 것과 비교하면, latent의 step 효율이 얼마나 높은지 직관적으로 와닿아요.
모델이 아니라 시스템 단위로 반복해보자
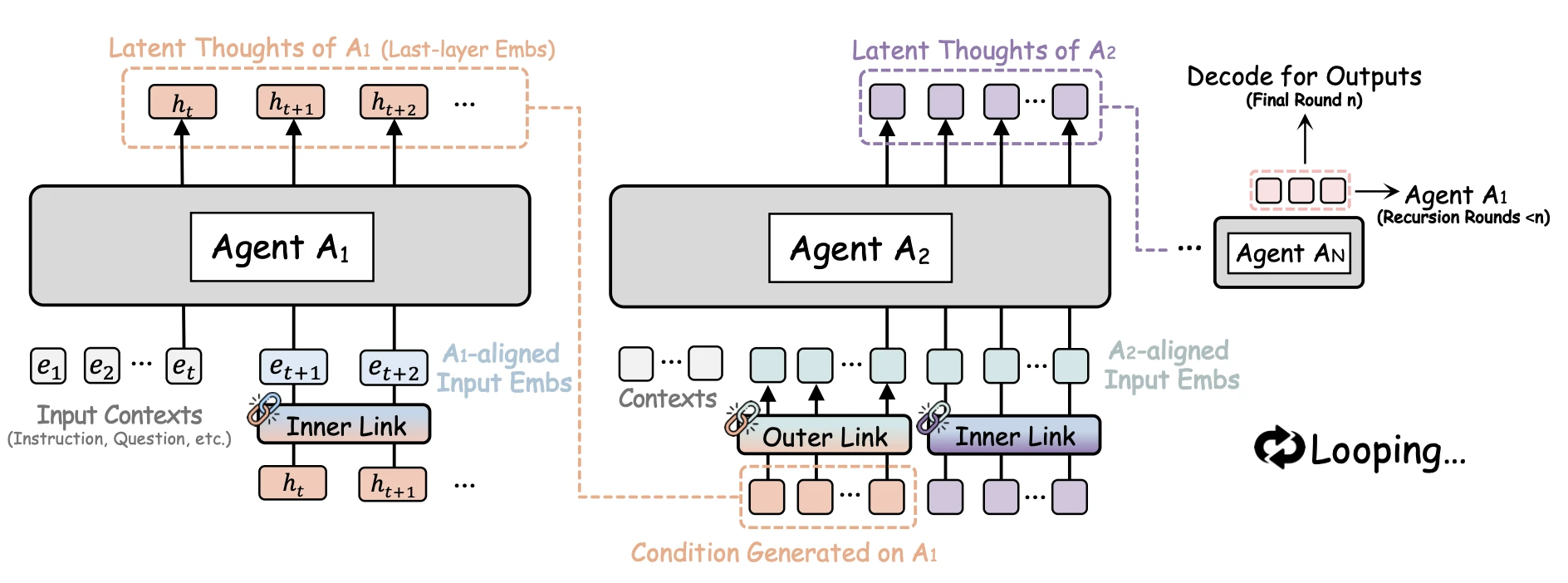
RecursiveMAS는 “latent를 다시 첫 에이전트로 돌려보내서 몇 바퀴 더 굴리자”는 아이디어예요. 핵심은 각 에이전트를 Recursive Language Model(RLM)의 한 layer로 취급하는 거예요. RLM이 같은 transformer block을 $n$번 반복했듯, MAS도 $A_1 \to A_2 \to \dots \to A_N \to A_1 \to \dots$의 루프로 닫고, 그 잠재 흐름을 system-level의 hidden stream으로 보는 거예요. 문제는 두 가지 분포 어긋남이에요.
- Dense-to-Shallow Transition: 한 에이전트 안에서 last-layer hidden을 다시 input embedding으로 쓸 때의 분포 차이예요.
- Cross-Model Transition: 다른 모델 패밀리, 다른 $d_h$를 가진 에이전트끼리 latent를 넘길 때의 차이예요. 이종 모델을 함께 쓰려면 단순한 ridge regression으로는 부족해요.
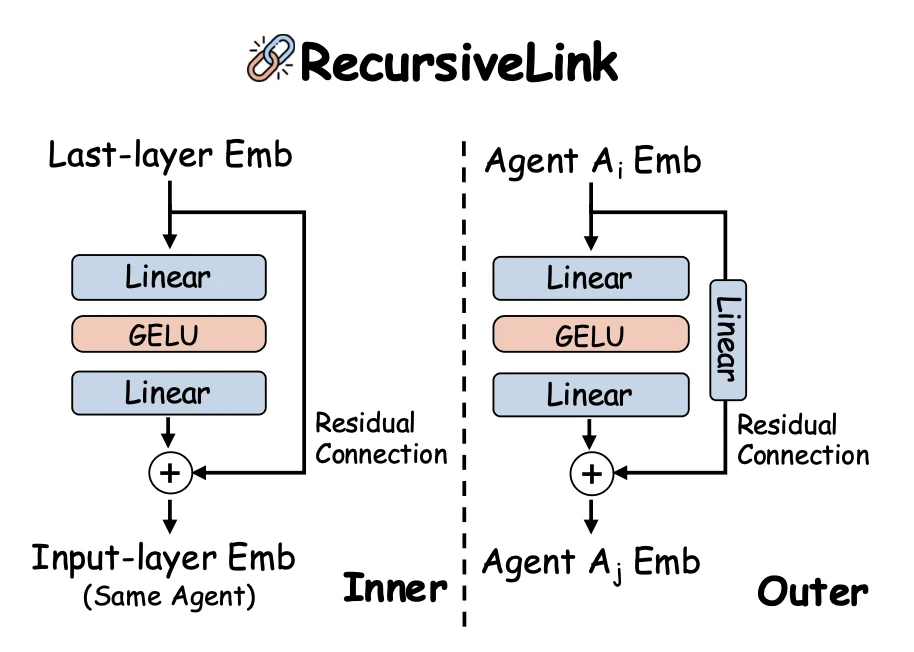
RecursiveLink라는 2-layer residual 모듈로 문제를 해결해요. 단일 에이전트 내부에서 쓰는 inner link는
\[\mathcal{R}_\text{in}(h) = h + W_2 \, \sigma(W_1 h)\]이종 에이전트 사이의 outer link는
\[\mathcal{R}_\text{out}(h) = W_3 h + W_2 \, \sigma(W_1 h)\]여기서 $\sigma$는 GELU예요. Residual branch가 원래 latent 의미를 거의 보존하고, non-linear branch가 분포 차이만 학습하면 되니 학습이 안정적이에요. Ablation study 결과, residual 1-layer가 plain 2-layer보다 좋은 성능을 보이고, residual 2-layer가 가장 좋은 성능을 보였어요.
각 에이전트 $A_i$는 $\mathcal{R}_ \text{in}$을 써서 $m$ step의 latent thought $H_{A_i} = [h_t, \dots, h_{t+m}]$을 만들고, 이걸 $\mathcal{R}_ \text{out}$에 통과시켜 다음 에이전트 $A_{i+1}$의 입력 임베딩 공간으로 옮겨요. 마지막 에이전트 $A_N$의 latent thoughts는 다시 $A_1$로 돌아가 새 라운드를 시작하고, 마지막 라운드에서만 텍스트로 디코딩해요.
Inner-Outer Loop Training
RecursiveLink만 학습 가능하고, Base LLM은 모두 freeze해요. 학습은 두 단계로 진행돼요.
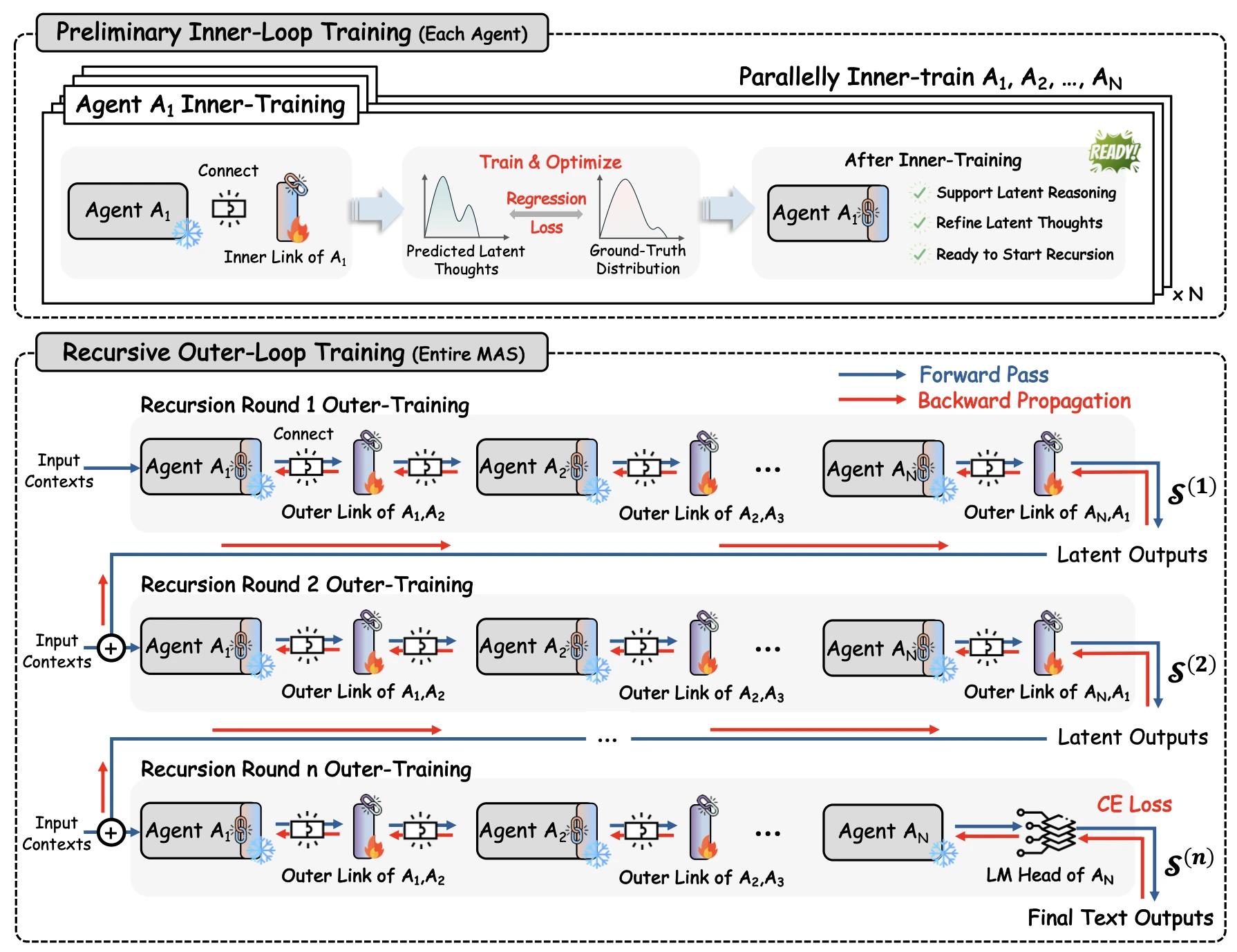
Inner loop는 각 에이전트의 inner link만 따로 학습하는 model-level warm start예요. Ground-truth 정답 $y$를 해당 에이전트의 입력 임베딩 레이어로 보낸 분포를 타겟으로, latent thought $H$를 cosine 유사도 기준으로 조정해요.
\[\mathcal{L}_\text{in} = 1 - \cos\!\big( \mathcal{R}_\text{in}(H), \, \text{E}_{\theta_i}(y) \big)\]이 단계는 디코딩과 재인코딩 없이 latent thought가 입력 임베딩 분포에 머물게 만들어, 각 에이전트의 latent 생성을 안정화해요.
Outer loop는 system-level 학습이에요. 시스템을 $n$ 라운드 펼치고, 마지막 텍스트 예측에 cross-entropy를 걸어 모든 outer link에 공유 credit을 분배해요.
\[\mathcal{L}_\text{out} = \text{CE}\!\big( \mathcal{S}^{(n)}( \mathcal{S}^{(n-1)}(\dots \mathcal{S}^{(1)}(x))), \, y \big)\]Gradient가 전체 재귀 trace를 따라 backprop되므로, 각 outer link는 최종 정답에 맞춰 업데이트돼요. 학습 가능한 파라미터는 약 13.12M(전체의 0.31%)뿐이고, peak GPU memory 15.29GB로 LoRA(21.67GB)·Full-SFT(41.40GB)보다도 작아요. 비용 $4.27에 평균 정확도 74.%로 다른 두 방법을 모두 앞서요.
왜 latent로 재귀해야 할까
Proposition 3.1 (Runtime Complexity)에 따라 같은 협력 구조의 텍스트 재귀 MAS의 복잡도는
\[\Theta\!\big( N (m |\mathcal{V}| d_h + (t+m) d_h^2 + (t+m)^2 d_h) \big)\]인데, RecursiveMAS는
\[\Theta\!\big( N (m d_h^2 + (t+m) d_h^2 + (t+m)^2 d_h) \big).\]$d_h \ll |\mathcal{V}|$이므로 $m |\mathcal{V}| d_h$가 $m d_h^2$로 바뀌는 게 유리해요. 매 라운드마다 어휘 projection을 반복하지 않으면 계산 복잡도가 낮아진다는 걸 뜻해요.
Theorem 4.1 (Gradient Stability). 텍스트로 재귀 MAS를 학습하면, 매 라운드마다 hidden state → softmax → 토큰 → 임베딩의 과정을 거쳐요. 모델이 잘 학습될수록 softmax 출력이 한 토큰에 몰리는데(즉 confident해지는데), 이렇게 되면 softmax의 gradient가 거의 0에 수렴해요. 재귀 라운드가 깊어질수록 이 near-zero gradient가 곱해지니까 학습 신호가 빠르게 사라져요.
반면 RecursiveLink는 $\mathcal{R}(h) = h + W_2 \sigma(W_1 h)$ 형태라 identity($h$)가 그대로 남아 있어요. ResNet의 skip connection과 같은 원리예요. 정리하면, 텍스트 재귀는 “모델이 잘할수록 학습이 안 되는” 구조적 모순이 있고, RecursiveLink는 residual 구조로 이를 회피해요.
RecursiveMAS 실험 결과
| 패턴 | 구성 | 대표 결과 |
|---|---|---|
| Sequential | Planner / Critic / Solver | r=3에서 +7.2pt, 2.4× 가속, -75.6% 토큰 |
| Mixture | Math/Code/Science 전문가 + Summarizer | 가장 강한 단일 전문가 대비 +6.2% |
| Distillation | Expert + Learner | learner +8.0%, expert 대비 1.5× 가속 |
| Deliberation | Reflector + Tool-Caller (Python/Search) | tool agent +4.8% |
raw 정확도에서 RecursiveMAS는 MATH500 88.0, AIME2025 86.7, AIME2026 86.7로 LoopLM(84.6/66.7/63.3), TextGrad(84.9/73.3/76.7), Recursive-TextMAS(85.8/73.3/73.3)를 모두 앞서요. 특히 텍스트 재귀 baseline 대비 격차가 라운드 깊이에 따라 벌어지는(r=1: +3.4, r=2: +6.0, r=3: +7.2) 점이 핵심이에요. case study에서는 r=1에서 6이라는 오답을 내던 모델이 r=3에서 7로 자기 교정하는 사례도 확인할 수 있어요.
저자들이 말하는 training & inference recursion의 상호보완성도 흥미로워요. 학습 라운드가 깊을수록 inference 라운드를 늘릴 때 더 멀리 갈 수 있는 frontier가 형성돼요. LoopLM의 단일 모델 재귀 스케일링 법칙을 시스템 단위로 확장한 결과예요. latent thought 길이 $m$ ablation에서는 $m \approx 80$에서 saturate하고, 그 이상은 오히려 redundant해진다는 결과가 나와요.
LSTM과 ResNet이 그랬듯
Agent 논문을 보다보면 self-refinement가 성능을 떨어뜨린다는 실험 결과를 종종 봤어요. 왜 그런 현상이 발생하는지 명확한 설명이 없었는데, LatentMAS와 RecursiveMAS를 통해 답을 알게 되었어요. RNN에서 시퀀스가 길어지면 gradient vanishing이 발생하듯, 확률에 따라 토큰을 결정하는 순간 정보가 한 지점으로 수렴하며 손실되는 것이었어요. 이후 LSTM이나 ResNet이 그랬던 것처럼 residual connection을 만들어 정보를 유지한다는 아이디어가 신선했어요.