SVD를 이용한 이미지 압축
Eigen-decomposition
$n \times n$ 정방행렬 $A$에 $n$개의 선형독립인 고유벡터 $v_1, v_2, \dots, v_n$과 대응되는 고윳값 $\lambda_1, \lambda_2, \dots, \lambda_n$이 존재한다고 가정해요. 고유벡터를 열로 모은 행렬을 $P$, 고윳값을 대각에 놓은 행렬을 $D$라고 하면,
\[P = \begin{bmatrix} | & | & & | \\ v_1 & v_2 & \cdots & v_n \\ | & | & & | \end{bmatrix}, \quad D = \begin{bmatrix} \lambda_1 & 0 & \cdots & 0 \\ 0 & \lambda_2 & \cdots & 0 \\ \vdots & & \ddots & \vdots \\ 0 & 0 & \cdots & \lambda_n \end{bmatrix}\]이때 $Av_i = \lambda_i v_i$를 한꺼번에 행렬 형태로 쓰면
\[AP = PD\]가 돼요. $P$가 invertible하다면 양변에 $P^{-1}$을 곱해서
\[A = PDP^{-1}\]를 얻어요. 이게 바로 고윳값 분해(Eigen-decomposition)예요.
직관적으로 한 번 더 풀어볼게요. $A$의 각 고유벡터에 $A$를 곱하면 그 방향은 그대로이고 길이만 $\lambda_i$배로 늘어나요.
\[A v_1 = \lambda_1 v_1, \quad A v_2 = \lambda_2 v_2, \quad \dots\]이를 한 줄로 합치면
\[A [v_1\ v_2\ \cdots\ v_n] = [\lambda_1 v_1\ \lambda_2 v_2\ \cdots\ \lambda_n v_n] = [v_1\ v_2\ \cdots\ v_n] \begin{bmatrix} \lambda_1 & & \\ & \ddots & \\ & & \lambda_n \end{bmatrix}\]즉 $AP = PD$이고, 양변에 $P^{-1}$를 곱하면 $A = PDP^{-1}$이 돼요.
Eigen-decomposition을 이용한 압축
이미지를 행렬 $A$로 표현하고, $A$가 정방 + 대칭이라고 가정해 봐요. 그러면
\[A = \sum_{i=1}^{n} \lambda_i v_i v_i^T\]로 쓸 수 있고, 고윳값의 절댓값을 큰 순서대로 정렬하면 앞쪽 항일수록 행렬을 더 잘 설명해요. 큰 $\lambda_i$는 그 방향으로 데이터를 크게 늘려서 분산(variance)을 많이 만들어내는 방향이고, 작은 $\lambda_i$는 거의 기여하지 않는 방향이에요.
따라서 작은 고윳값들을 잘라내고(truncate) 큰 고윳값 $k$개만 남기면
\[A \approx \tilde A = \sum_{i=1}^{k} \lambda_i v_i v_i^T\]이렇게 근사된 $\tilde A$는 원래 행렬의 핵심 정보를 보존하면서 저장량을 줄여요. 원래는 $n \times n$ 개의 숫자가 필요했는데, $\tilde A$를 표현하려면 $k$개의 고윳값과 $k$개의 길이-$n$ 고유벡터, 총 $k(n+1)$개의 숫자만 있으면 돼요. $k \ll n$이면 압축률이 굉장히 커요.
“중요한” 정보란 무엇일까요? 고윳값은 그 방향으로의 스케일링 정도예요. 큰 고윳값을 가진 고유벡터 방향에서는 데이터가 넓게 퍼져 있어서 분산이 크고, 그만큼 정보를 많이 담아요. 반대로 작은 고윳값에 대응하는 방향은 데이터가 거의 변하지 않는 “잡음에 가까운” 축이라 버려도 큰 손실이 없어요. PCA가 정확히 이 원리로 동작해요.
이게 차원 축소(dimensionality reduction)와 PCA의 본질이에요. 공분산 행렬 $\Sigma$는 대칭이므로 항상 $\Sigma = Q\Lambda Q^T$로 분해되고, 큰 고윳값에 대응하는 고유벡터(=주성분, principal component)만 남겨서 데이터를 더 낮은 차원에 투영해요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import numpy as np
from PIL import Image
# 흑백 이미지 불러오기
img = np.array(Image.open("photo.jpg").convert("L"), dtype=np.float64)
# 대칭 행렬을 만들기 위해 A^T A 사용 (예시용)
A = img.T @ img # 항상 대칭 + positive semidefinite
eigvals, eigvecs = np.linalg.eigh(A) # 대칭행렬용 (실수 보장, 직교벡터)
# 큰 고윳값부터 정렬
idx = np.argsort(-eigvals)
eigvals, eigvecs = eigvals[idx], eigvecs[:, idx]
# 상위 k개만 사용하여 근사
k = 50
A_approx = (eigvecs[:, :k] * eigvals[:k]) @ eigvecs[:, :k].T
Eigendecomposition의 한계와 SVD의 필요성
여기까지 잘 따라왔다면 한 가지 의문이 들 거예요. 이미지는 보통 정사각형이 아닌데? 그리고 RGB 컬러 채널, 직사각형 사진, 사용자-아이템 행렬처럼 우리가 다루는 데이터는 거의 다 $m \times n$ 직사각 행렬이에요. 고윳값 분해는 여기서 막혀요. 한계를 하나씩 살펴볼게요.
한계 1: 정방행렬에만 정의된다
$A = PDP^{-1}$의 양변이 같으려면 $A$가 $n \times n$ 정방행렬이어야 해요. 직사각 행렬에는 그냥 정의 자체가 안 돼요.
한계 2: 정방이어도 항상 분해되지 않는다 (Defective matrix)
정방행렬이라고 다 되는 것도 아니에요. 선형독립인 고유벡터가 $n$개여야 $P^{-1}$이 존재해요. 대표적인 반례가 shear 행렬
\[A = \begin{bmatrix} 1 & 1 \\ 0 & 1 \end{bmatrix}\]이에요. 고윳값은 $\lambda = 1$ 하나뿐이고, 고유벡터는 $[1, 0]^T$ 한 방향만 나와서 $\mathbb{R}^2$의 기저를 이루지 못해요. 이런 행렬을 defective matrix라고 불러요. 고윳값 분해가 불가능해요. 일반적으로 어떤 고윳값의 기하적 중복도가 대수적 중복도보다 작으면 그 행렬은 defective이고, 대각화가 안 돼요.
한계 3: 고유벡터가 직교한다는 보장이 없다
일반 정방행렬의 고유벡터는 서로 직교하지 않을 수 있어서 $P^{-1}$ 계산이 수치적으로 불안정해요. 대칭행렬은 직교성이 보장되지만, 그건 매우 좁은 부분집합이에요.
한계 4: 고윳값이 음수이거나 복소수일 수 있다
일반 행렬의 고윳값은 음수일 수도, 복소수일 수도 있어요. “중요도”를 양수 스케일로 해석하고 싶은 압축/근사 관점에서는 불편한 성질이에요.
그래서 SVD
특이값 분해(Singular Value Decomposition, SVD)가 이 모든 한계를 깨끗하게 해결해요. 임의의 $m \times n$ 행렬 $A$에 대해 항상
\[A = U \Sigma V^T\]로 분해할 수 있어요. 여기서
- $U$는 $m \times m$ 직교행렬 (left singular vector들이 열로 들어 있음)
- $V$는 $n \times n$ 직교행렬 (right singular vector들이 열로 들어 있음)
- $\Sigma$는 $m \times n$ 행렬로, 주대각에만 0 이상의 특이값(singular value) $\sigma_1 \ge \sigma_2 \ge \cdots \ge 0$이 큰 순서로 정렬돼 있음
핵심 비교를 표로 정리하면 이래요.
| 항목 | Eigendecomposition | SVD |
|---|---|---|
| 적용 가능 행렬 | $n \times n$ 정방행렬, 그것도 대각화 가능할 때만 | 임의의 $m \times n$ 행렬, 항상 존재 |
| 분해 형태 | $A = PDP^{-1}$ | $A = U\Sigma V^T$ |
| 좌/우 기저 | 같은 기저 $P$ 하나만 사용 | 입력 기저 $V$와 출력 기저 $U$를 따로 사용 |
| 직교성 보장 | 대칭일 때만 보장 | $U$, $V$ 모두 항상 직교 |
| 분해값 부호 | 음수, 복소수 가능 | 특이값은 항상 실수, 비음수 |
두 분해의 연결고리
SVD는 고윳값 분해와 끊어진 관계가 아니에요. $A = U\Sigma V^T$로부터
\[A A^T = U \Sigma V^T V \Sigma^T U^T = U(\Sigma \Sigma^T) U^T\] \[A^T A = V (\Sigma^T \Sigma) V^T\]여기서 $AA^T$와 $A^TA$는 둘 다 대칭(+ positive semidefinite) 행렬이므로 고윳값 분해가 항상 존재해요. 즉,
- $U$는 $AA^T$의 고유벡터
- $V$는 $A^TA$의 고유벡터
- $\sigma_i^2$는 $AA^T$(또는 $A^TA$)의 고윳값
이라서 SVD는 정사각이 아닌 행렬에 고윳값 분해의 사고를 일반화한 것이라고 볼 수 있어요. “정방행렬 + 대칭”이라는 두 조건이 갖춰지면 SVD는 본질적으로 같은 일을 해요.
이미지 분해
이미지 가로 길이가 $w$, 세로 길이가 $h$일 때, 2차원 이미지는 $h\times w$ 행렬로 표현할 수 있어요. 이미지 행렬을 $M$라고 할 때, 다음과 같이 분해할 수 있어요.
\[M=U\Sigma V^T\] \[U=[u_1, u_2 ... u_h]\] \[V=[v_1, v_2 ... v_w]\] \[\Sigma=diag(\sigma_1, \sigma_2, ... \sigma_n)\]SVD에는 흥미로운 특징이 있는데 singular value가 큰 값부터 내림차순으로 나열되어 있다는 점이에요. $\sigma$ 중 $\sigma_1$이 가장 큰 값을 가져요. 즉, 첫 번째 값부터 순서대로 중요한 정보를 담고 있어요.
이미지 행렬 $M$은 $\sum_{n=1} \sigma_n u_n v_n^T$으로 표현할 수 있어요. 그런데 만약 정보를 전부 사용하지 않고 중요한 정보 몇 가지만 사용하면 어떨까요?
가로 500, 세로 600의 600 x 500 행렬에 대해 실험했어요.

당연히 벡터를 많이 사용할수록 이미지가 선명해져요.
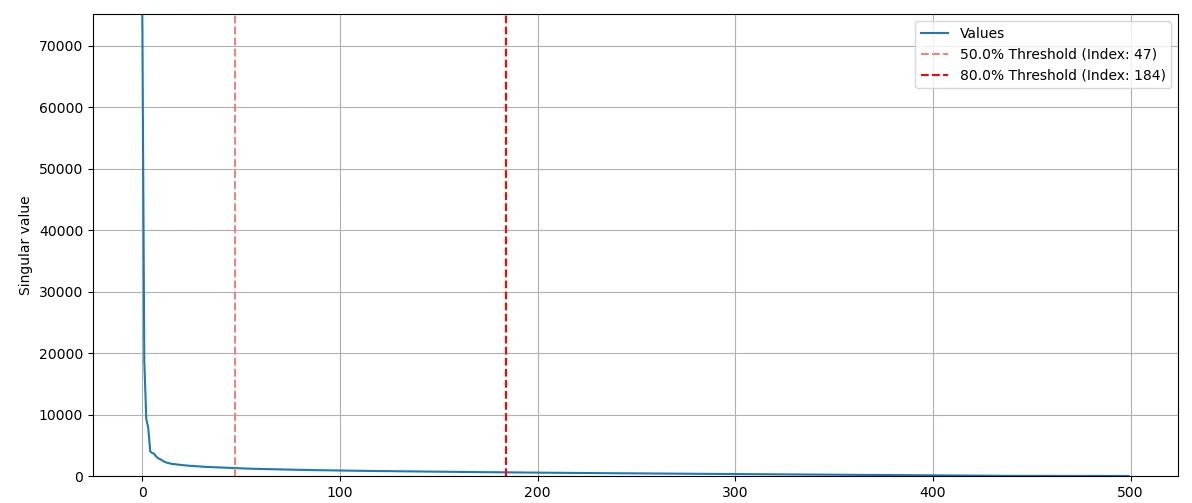
singular value를 시각화해보면 n = 184에서 이미 singular value 총합의 80%를 넘어가요. 184 쌍의 singular vector만으로도 이미지 80%를 복원할 수 있죠.

만약 600 x 500 행렬을 모두 사용하면 총 300,000개의 정보가 필요해요. 하지만, n = 200이라면 총 220,200개의 정보만 있으면 돼요.
SVD는 np.linalg.svd를 통해 계산해요. full_matrices 옵션은 불필요한 벡터를 저장할지 결정해줘요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
"""이미지 분해 및 재구성"""
import numpy as np
from PIL import Image
import os
image_path = "object4.jpg"
output_dir = "svd_images"
image = Image.open(image_path).convert("L")
image = np.array(image, dtype=np.float64)
# Singular Vector Decomposition (SVD)
# Image: (600, 500), S: (500,), Vt: (500, 500)
# U: (600, 500) when full_matrices=False
# U: (600, 600) when full_matrices=True
U, S, Vt = np.linalg.svd(image, full_matrices=False)
# 이미지 재구성
for n in range(1, len(S) + 1):
singular_values = np.zeros((U.shape[1], Vt.shape[0]))
np.fill_diagonal(singular_values, S[:n])
reconstructed = np.dot(
U[:, :n],
np.dot(singular_values[:n, :n], Vt[:n, :]),
)
output_image = np.clip(reconstructed, 0, 255).astype(np.uint8)
# 단계별 이미지 저장
if n % 10 == 0:
output_path = os.path.join(output_dir, f"{n}.png")
Image.fromarray(output_image).save(output_path)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
"""Singular value 시각화"""
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
image = Image.open("object4.jpg").convert("L")
image = np.array(image, dtype=np.float64)
U, S, Vt = np.linalg.svd(image, full_matrices=False)
cumulative_sum = np.cumsum(S)
total_sum = np.sum(S)
threshold_percentage_1 = 0.5
threshold_percentage_2 = 0.8
threshold_1 = total_sum * threshold_percentage_1
threshold_2 = total_sum * threshold_percentage_2
threshold_index_1 = np.argmax(cumulative_sum >= threshold_1)
threshold_index_2 = np.argmax(cumulative_sum >= threshold_2)
plt.figure(figsize=(14, 6))
plt.plot(range(len(S)), S, label="Values")
plt.axvline(
x=threshold_index_1,
color="lightcoral",
linestyle="--",
label=f"{threshold_percentage_1 * 100}% Threshold (Index: {threshold_index_1})",
)
plt.axvline(
x=threshold_index_2,
color="red",
linestyle="--",
label=f"{threshold_percentage_2 * 100}% Threshold (Index: {threshold_index_2})",
)
plt.xlabel("Index")
plt.ylabel("Singular value")
plt.ylim(0, S[0] + 1)
plt.legend()
plt.grid(True)
plt.show()
참고자료