Graph Neural Network 알아보기
GNN(Graph Neural Network)의 대표 모델인 GCN, GraphSAGE, GAT 세 논문을 따라가며, 그래프 위에서 노드 표현을 학습하는 방법이 어떻게 발전했는지 살펴봐요.
- Semi-Supervised Classification with Graph Convolutional Networks, ICLR 2017, arXiv.
- Inductive Representation Learning on Large Graphs, NeurIPS 2017, arXiv.
- Graph Attention Networks, ICLR 2018, arXiv.
- Sign and Basis Invariant Networks for Learning on Graphs, ICLR 2023, arXiv.
- CS224W: Machine Learning with Graphs, 2024, standford.
Graph 데이터는 무엇이 다를까
Graph는 $G = (V, E)$로 적어요. $V$는 node(정점), $E$는 edge(간선)예요. 누가 누구와 연결됐는지는 adjacency matrix $A$에 담아요. Node $i$와 $j$가 연결되면 $A_{ij} = 1$이에요. Node마다 가진 feature 벡터를 모으면 $X$가 되고, 각 node의 연결 개수를 대각선에 담은 matrix를 degree matrix $D$라고 해요.
이 글에서 소개할 그래프 모델은 모두 같은 아이디어에서 출발해요. “내 주변의 정보를 모아서 나를 표현한다.” Neighbor의 feature를 끌어모아 node 표현을 만들고, 이 표현으로 node의 종류(label)를 맞혀요. 세 논문은 “neighbor 정보를 어떻게 모으느냐”를 다르게 풀어요.
Graph를 matrix로 어떻게 표현할까
논문 수식에 나오는 $A$, $D$, $L$이 실제로 어떤 숫자인지 예시로 보면 감이 잡혀요. Node 4개에 edge가 A-B, A-C, A-D, B-D로 연결된 graph를 생각해 볼게요 (아래 그림 참고). 각 node는 feature 벡터 $[f_1, f_2, \dots, f_n]$을 가져요. 예를 들어, SNS 상에 유저를 각각의 node라고 생각하면 feature는 [나이, 성별…]이 돼요.
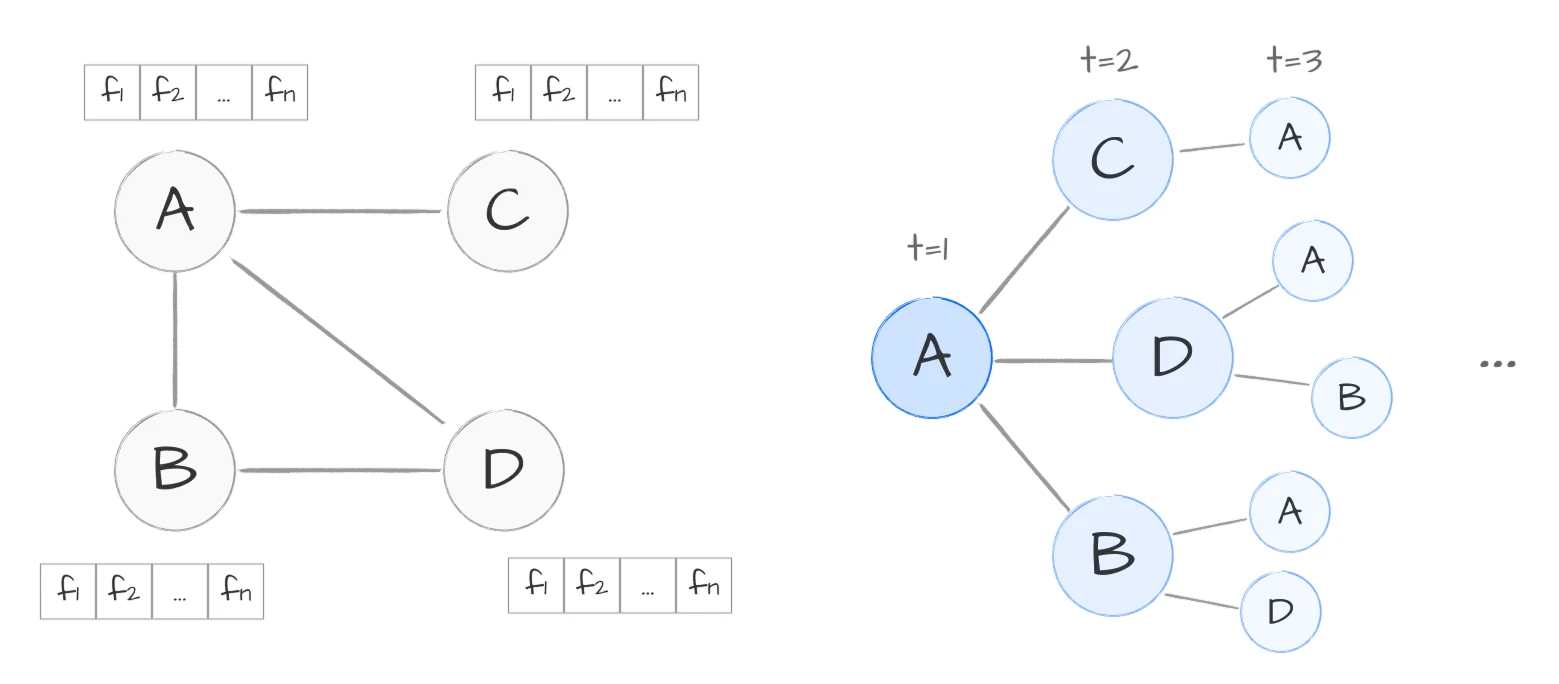
Adjacency matrix $A$는 누가 누구와 연결됐는지 담아요. Node $i$와 $j$가 연결되면 $A_{ij} = 1$, 아니면 $0$이에요. 무방향 graph라 대칭이고, 자기 자신과의 연결은 없어서 대각선은 $0$이에요. 행 순서와 열 순서는 node A, B, C, D예요.
\[A = \begin{bmatrix} 0 & 1 & 1 & 1 \\ 1 & 0 & 0 & 1 \\ 1 & 0 & 0 & 0 \\ 1 & 1 & 0 & 0 \end{bmatrix}\]첫 번째 행 $[0, 1, 1, 1]$은 node A가 node B, C, D와 연결됐다는 뜻이에요. 그림과 맞춰 보면 A번 node에서 선이 세 개 뻗어 있죠.
Degree matrix $D$는 각 node의 연결 개수(degree)를 대각선에 담은 diagonal matrix예요. $D_{ii} = \sum_j A_{ij}$, 즉 $A$의 각 행을 더한 값이에요. Node A은 neighbor가 3개, node B와 D는 2개, node C은 1개예요.
\[D = \begin{bmatrix} 3 & 0 & 0 & 0 \\ 0 & 2 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 2 \end{bmatrix}\]Laplacian $L = D - A$는 degree에서 연결을 뺀 matrix예요. 대각선은 degree, 연결된 자리는 $-1$이 돼요.
\[L = D - A = \begin{bmatrix} 3 & -1 & -1 & -1 \\ -1 & 2 & 0 & -1 \\ -1 & 0 & 1 & 0 \\ -1 & -1 & 0 & 2 \end{bmatrix}\]Laplacian는 각 행의 합이 항상 0이라는 성질이 있어요. “내 degree = 내 neighbor 수”이기 때문이에요. GCN이 사용하는 matrix가 Symmetric Normalized Laplacian을 다듬은 $\hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2}$예요. $\tilde{A} = A + I$는 자기 자신을 연결해 1을 기록하는 과정이에요. $\tilde{D}^{-1/2}$는 degree로 나누는 과정으로, neighbor 수만큼 정규화하는 부분이에요. 결국 각 성분이 $1/\sqrt{\tilde{d}_i \tilde{d}_j}$로 나누어진 꼴이 돼요. 자세한 내용은 GCN에서 살펴볼게요.
세 모델을 같은 구조로 해석할 수 있어요
세 모델은 겉보기엔 달라도 큰 틀은 비슷해요. 크게 두 가지 과정을 주목해야 해요.
Aggregate는 neighbor node들의 이전 표현을 하나의 벡터로 모으는 함수예요. Neighbor에는 순서가 없으니 입력 순서가 바뀌어도 결과가 같은 대칭(permutation invariant) 함수여야 해요. Combine은 그렇게 모은 neighbor 정보와 자기 자신의 이전 표현을 합쳐 새 표현을 만드는 함수예요. Node 분류는 이 두 함수를 여러 층 반복하면 돼요.
\[a_v^k = \text{AGGREGATE}^k\left( \{ h_u^{k-1} : u \in \mathcal{N}(v) \} \right)\] \[h_v^k = \text{COMBINE}^k\left( h_v^{k-1}, a_v^k \right)\]세 모델은 이 함수들을 어떻게 설계했는지에서 갈려요. 각 모델을 설명한 뒤 이 구조로 다시 정리해 볼게요.
GCN은 neighbor feature를 정규화해서 모은다
Semi-Supervised Classification with Graph Convolutional Networks (Kipf & Welling, 2017)
GCN(Graph Convolutional Network)의 핵심은 단순해요. 각 node가 자기 neighbor들의 feature를 정규화해서 모아 새 표현을 만드는 것이에요. 이 연산을 한 층(layer)으로 보고 여러 번 쌓으면, node는 점점 더 먼 neighbor의 정보까지 흡수해요.
스펙트럼 합성곱에서 출발해요
이 아이디어는 graph 위의 합성곱(spectral convolution)에서 나왔어요. 신호를 frequency domain으로 바꿔 필터를 곱하는 발상인데, graph에서는 normalized Laplacian $L = I - D^{-1/2} A D^{-1/2}$를 eigen-decomposition해서 graph 위의 Fourier transform을 정의해요. 신호 $x$와 필터 $g_\theta$의 합성곱은 이렇게 적어요.
\[g_\theta \star x = U g_\theta U^\top x\]$U$는 $L$의 eigenvector matrix예요. 문제는 이 곱이 node 수 $N$에 대해 $O(N^2)$이고, eigen-decomposition 자체도 큰 graph에서는 부담이라는 점이에요. 그래서 필터를 Chebyshev polynomial로 근사해요. Chebyshev polynomial은 점화식으로 차수를 하나씩 올려 만드는 다항식인데, 여기서는 “필터를 Laplacian의 다항식으로 표현하는 도구”라고만 봐도 충분해요. 이렇게 하면 두 가지 이득이 있어요. 합성곱 결과 $g_\theta \star x$를 eigen-decomposition 없이 신호 $x$에 $L$을 반복해서 곱하는 것만으로 계산할 수 있고, Laplacian의 $K$차 다항식이라 중심 node에서 최대 $K$ 스텝 이내 neighbor에만 의존해요 (K-localized).
GCN은 여기서 $K = 1$로 두고 가장 큰 eigenvalue를 $\lambda_{max} \approx 2$로 근사해, 한 단계 neighbor만 보는 가장 단순한 필터로 줄여요. 파라미터를 하나로 묶으면 다음 형태가 돼요.
\[g_\theta \star x \approx \theta \left( I + D^{-1/2} A D^{-1/2} \right) x\]그런데 $I + D^{-1/2} A D^{-1/2}$는 eigenvalue가 $[0, 2]$ 범위라, 층을 깊게 쌓으면 값이 폭주하거나 사라지는 불안정성이 생겨요. 이를 막으려고 자기 연결을 더한 matrix에 다시 정규화를 적용해요.
\[\hat{A} = \tilde{D}^{-1/2} \tilde{A} \tilde{D}^{-1/2}, \quad \tilde{A} = A + I, \quad \tilde{D}_{ii} = \sum_j \tilde{A}_{ij}\]자기 연결을 더하는 것($\tilde{A} = A + I$)은 neighbor만 보다가 자기 feature를 빼먹지 않으려는 것이고, degree로 나누는 건 neighbor가 많은 node의 값이 지나치게 커지는 걸 막으려는 거예요. 논문은 이 과정을 renormalization trick이라 불러요.
위에서 복잡하게 수식을 주절주절 설명했는데, 결론은 아래 내용을 이해하면 충분해요.
층을 쌓아 표현을 학습해요
한 층의 연산은 세 matrix의 곱 $Z = \hat{A} X \Theta$예요. $X$는 모든 node의 feature를 쌓은 입력이고, $\Theta$는 feature를 변환하는 학습 weight예요(입력 $C$차원을 출력 $F$차원으로 바꿔요). 곱하는 순서로 읽으면 역할이 보여요. 먼저 $X \Theta$가 각 node의 feature를 새 차원으로 변환하고, 거기에 $\hat{A}$를 곱하면 각 node가 자기 neighbor의 변환된 feature를 가중합해요. 즉 $\Theta$는 feature 변환, $\hat{A}$는 neighbor 섞기를 맡아요.
$\hat{A}$는 $N \times N$ matrix지만 연결된 node 자리만 값이 있고 나머지는 0이에요(sparse matrix). 그래서 0인 칸을 건너뛰고 계산하면 비용이 node 수의 제곱이 아니라 edge 수 $|E|$에 비례해요. 실제 graph는 edge가 node 수에 거의 선형이라 큰 graph에서도 효율적이에요.
여기에 비선형 $\sigma$를 더해 이전 층의 출력을 다음 층 입력으로 넣으며 쌓으면, GCN의 전파 규칙이 완성돼요.
\[H^{(l+1)} = \sigma\left( \hat{A} H^{(l)} W^{(l)} \right)\]$H^{(l)}$은 $l$번째 층에서 각 node의 표현이고 첫 입력은 $H^{(0)} = X$예요. 기호만 바뀌었을 뿐 $\hat{A} H^{(l)} W^{(l)}$는 앞의 $\hat{A} X \Theta$와 같은 구조이고, $\sigma$는 ReLU 같은 활성화 함수예요. 2 layer인 node 분류 모델은 이렇게 써요.
\[Z = \text{softmax}\left( \hat{A} \, \text{ReLU}\left( \hat{A} X W^{(0)} \right) W^{(1)} \right)\]마지막 softmax로 각 node가 속한 label의 확률을 출력하고 cross-entropy로 학습해요. Label이 일부 node에만 있어도 graph 구조를 따라 정보가 퍼지면서 label 없는 node까지 함께 학습돼요. 이런 방식을 준지도 학습(semi-supervised)이라고 해요.
GCN은 간단하고 효율적이지만 한계가 있어요. 학습에 정규화된 adjacency matrix, 즉 graph 전체가 필요해서 학습에 없던 새 node가 들어오면 바로 쓰기 어려워요. 이런 방식을 transductive라고 불러요.
Aggregate, Combine으로 보면
GCN은 Aggregate와 Combine이 하나로 합쳐진 형태예요. $\hat{A} H^{(l)}$ 한 번에 neighbor와 자기 자신($\tilde{A} = A + I$로 더해진 self-loop)을 함께 degree 정규화 weight $1/\sqrt{d_i d_j}$로 더하기 때문이에요. Node 하나로 풀어 쓰면 아래와 같아요.
\[h_i^{(l+1)} = \sigma\left( \sum_{j \in \mathcal{N}(i) \cup \{i\}} \frac{1}{\sqrt{d_i d_j}} W^{(l)} h_j^{(l)} \right)\]- Aggregate: degree로 정규화한 neighbor feature의 가중합이에요. Weight가 degree로 고정돼서 학습되지 않아요.
- Combine: 자기 자신을 별도로 다루지 않고 self-loop로 Aggregate에 함께 넣어요. 즉 Combine이 Aggregate에 흡수된 형태예요.
GraphSAGE는 처음 보는 node도 처리할 수 있다
Inductive Representation Learning on Large Graphs (Hamilton et al., 2017)
GCN은 graph 전체를 놓고 학습해서, 새 node가 등장하면 다시 학습해야 해요. 하지만 Reddit 게시물이나 새 단백질 데이터처럼 현실에서는 보지 못한 node가 계속 생겨요. GraphSAGE는 SAmple and aggreGatE라는 이름처럼 새로운 데이터를 다룰 수 있어요.
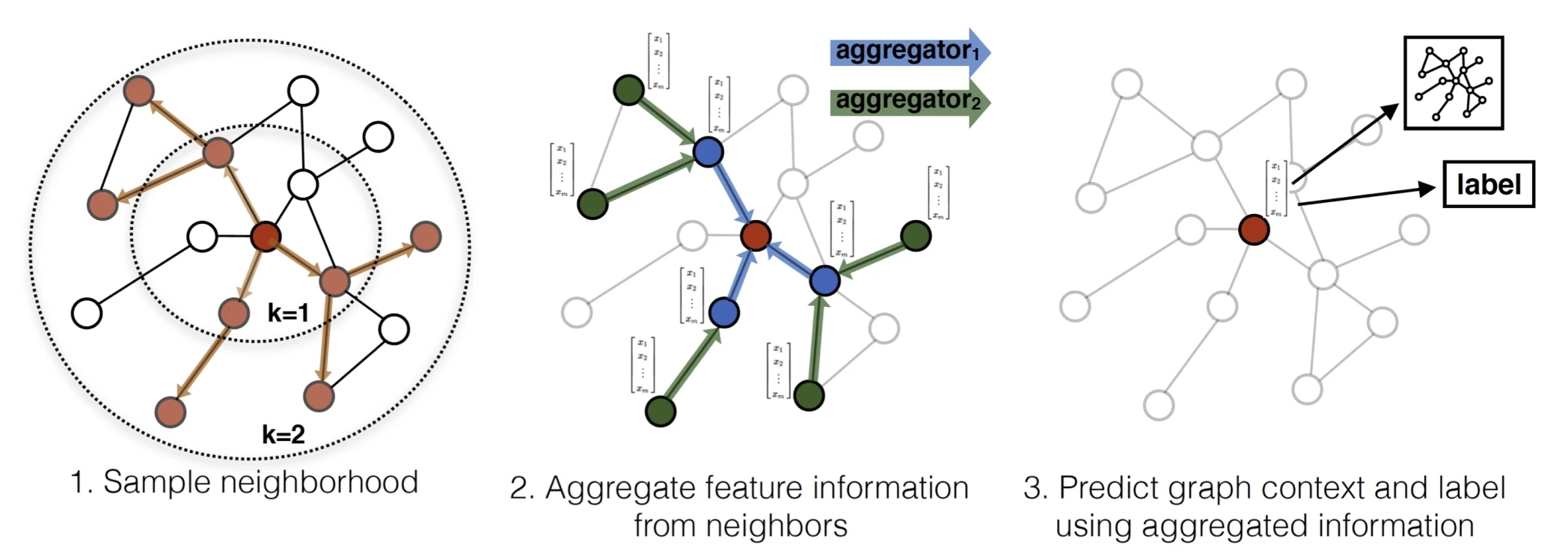
Node마다 표현을 따로 외우는 대신, neighbor의 feature를 모으는 “방법(함수)”을 학습해요. 방법만 익혀 두면 학습 때 없던 node라도 그 neighbor를 같은 방법으로 모아 표현을 바로 만들 수 있어요. 이렇게 새 node에도 일반화하는 방식을 inductive라고 해요.
샘플링하고 집계해요
한 층에서 node $v$의 표현은 세 단계로 만들어져요. 시작은 입력 feature $h_v^0 = x_v$예요. 매 단계 $k$마다 먼저 neighbor들의 이전 표현을 하나로 모으고(AGGREGATE), self representation과 이어 붙여(CONCAT) weight와 활성화 함수를 통과시킨 뒤, 벡터 크기를 1로 정규화해요.
\[h_{\mathcal{N}(v)}^k = \text{AGGREGATE}_k\left( \{ h_u^{k-1}, \forall u \in \mathcal{N}(v) \} \right)\] \[h_v^k = \sigma\left( W^k \cdot \text{CONCAT}\left( h_v^{k-1}, h_{\mathcal{N}(v)}^k \right) \right)\] \[h_v^k = h_v^k / \| h_v^k \|_2\]$k$는 몇 단계 neighbor까지 볼지를 뜻하고, 반복할수록 더 먼 neighbor 정보가 모여요. 최종 표현은 $z_v = h_v^K$예요. Self representation을 이어 붙이는 concat은 skip connection 역할을 해서, combine 과정에서도 자신의 정보를 잃지 않게 해줘요.
Neighbor가 아주 많은 node는 계산이 부담돼요. 그래서 GraphSAGE는 매 단계 neighbor를 고정된 수 $S_k$만큼 무작위로 뽑아서(sample) 써요. 그러면 배치당 계산량이 $O(\prod_{k=1}^{K} S_k)$로 일정해져요. 실험에서는 $K = 2$, $S_1 \cdot S_2 \le 500$ 정도면 충분했어요.
집계 함수는 순서에 무관해야 해요
Neighbor에는 순서가 없으니, 모으는 함수는 입력 순서가 바뀌어도 결과가 같은 대칭(permutation invariant) 함수여야 해요. 논문은 세 가지를 제안해요.
Mean은 neighbor 벡터의 평균을 내요. 자신과 neighbor를 함께 평균 내고 concat를 생략하면 GCN과 거의 같은 형태가 되는데, 이를 GraphSAGE-GCN라 불러요.
\[h_v^k = \sigma\left( W \cdot \text{MEAN}\left( \{ h_v^{k-1} \} \cup \{ h_u^{k-1}, \forall u \in \mathcal{N}(v) \} \right) \right)\]LSTM은 표현력이 크지만 순서를 타서 본래 대칭이 아니에요. 그래서 neighbor를 무작위로 섞어 넣어 대칭에 가깝게 만들어요.
Pooling은 각 neighbor를 작은 신경망에 통과시킨 뒤 원소별 최댓값을 골라요. 대칭이면서 학습 가능해요.
\[\text{AGGREGATE}_k^{pool} = \max\left( \{ \sigma(W_{pool} h_{u_i}^k + b), \forall u_i \in \mathcal{N}(v) \} \right)\]이 방식은 label 없어도 학습할 수 있어요.
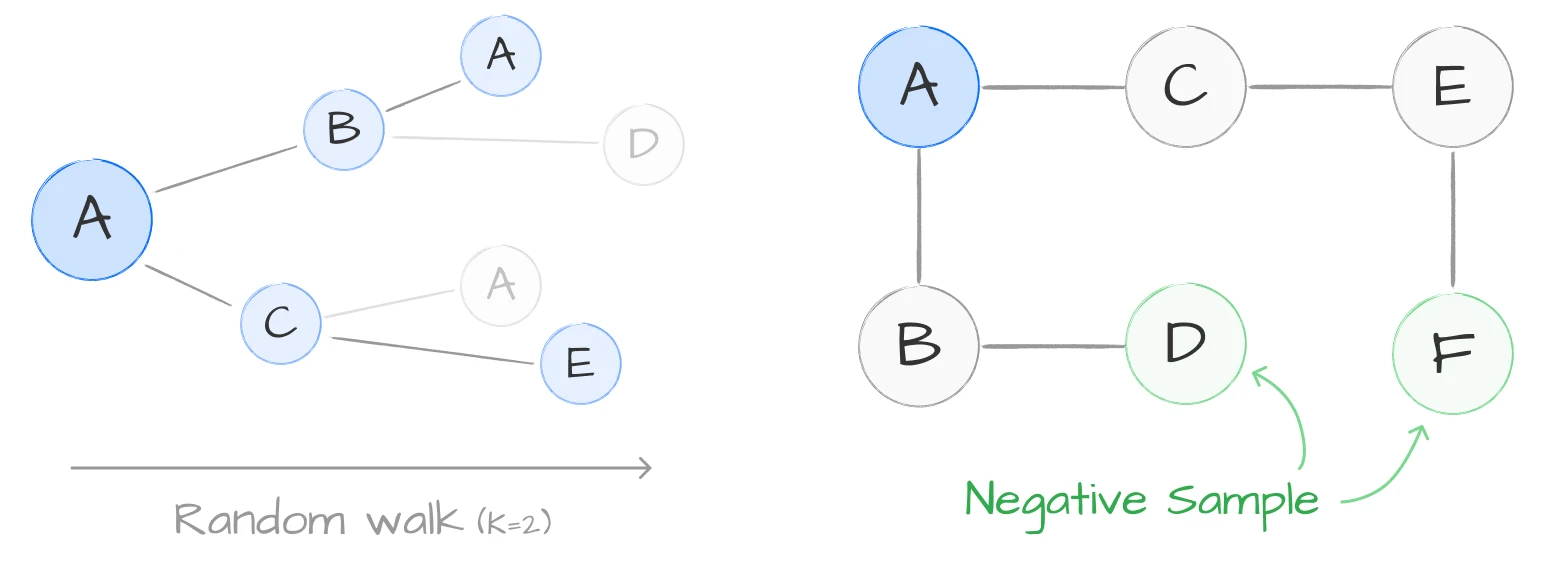
Random walk에서 가까이 나타난 node는 표현이 비슷해지고, 그렇지 않은 node는 멀어지도록 유도하는 손실을 써요.
\[J_G(z_u) = -\log\left( \sigma(z_u^\top z_v) \right) - Q \cdot \mathbb{E}_{v_n \sim P_n(v)} \log\left( \sigma(-z_u^\top z_{v_n}) \right)\]$v$는 $u$ 근처에 함께 나타난 node, $\sigma$는 sigmoid, $P_n$은 negative sampling 분포, $Q$는 negative sample 개수예요. 앞 항은 가까운 쌍을, 뒤 항은 무관한 쌍을 다뤄요. 실험에서는 pooling으로 충분히 좋은 성능을 보였고, 학습 때 보지 못한 node와 graph도 잘 처리했어요.
Aggregate, Combine으로 보면
GraphSAGE는 Aggregate와 Combine을 명확히 분리한 점이 feature예요.
- Aggregate: mean, LSTM, pooling 중 하나를 골라 neighbor를 모아요. GCN처럼 weight를 고정하지 않고, pooling이나 LSTM은 집계 자체에 학습 파라미터를 둬요. 고정 수만큼 neighbor를 샘플링한 뒤 적용하는 것도 차이예요.
- Combine: 모은 neighbor 표현 $h_{\mathcal{N}(v)}^k$와 자기 이전 표현 $h_v^{k-1}$을 concat한 뒤 $W^k$와 비선형을 통과시켜요. GCN이 self-loop로 합쳐 버린 것과 달리, self representation을 따로 이어 붙여 구분해요. 이 concat가 skip connection 역할을 해요.
GAT는 neighbor마다 중요도를 다르게 준다
Graph Attention Networks (Veličković et al., 2018)
GCN은 neighbor를 degree에 따라 정해진 비율로 섞고, GraphSAGE의 평균 집계도 neighbor를 똑같이 다뤄요. 하지만 neighbor이라고 다 똑같이 중요하진 않아요. GAT(Graph Attention Network)는 attention을 써서, 어떤 neighbor를 더 비중 있게 볼지 모델이 직접 학습하게 해요.
Attention으로 neighbor의 중요도를 계산해요
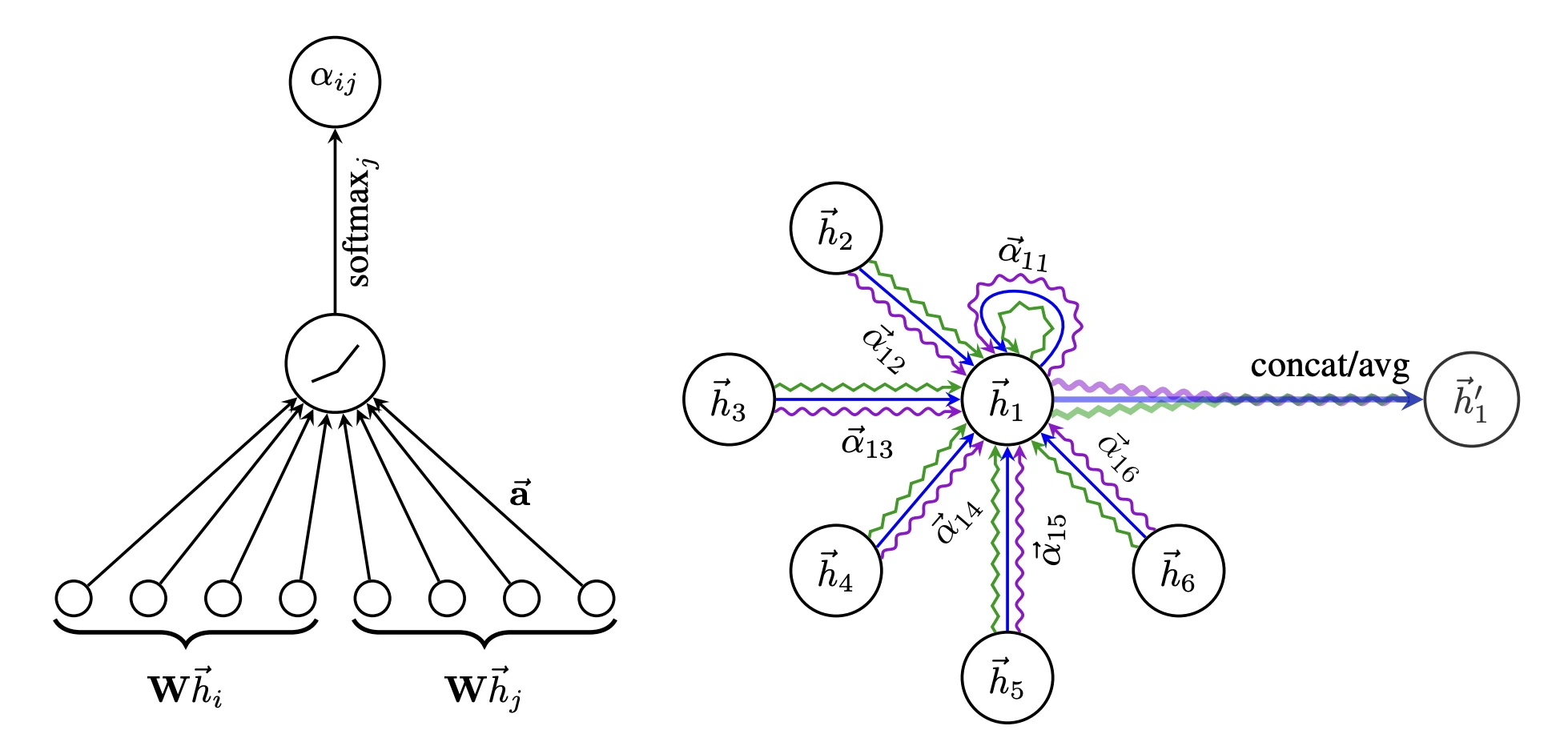
먼저 모든 node에 공유 weight $W$를 곱해 feature를 변환해요. 그다음 node $i$와 neighbor $j$ 사이의 중요도 점수 $e_{ij}$를 계산해요. 두 node의 변환된 feature를 이어 붙여, weight 벡터 $\vec{a}$와 LeakyReLU를 적용하는 작은 신경망이에요.
\[e_{ij} = \text{LeakyReLU}\left( \vec{a}^\top [W\vec{h}_i \, \| \, W\vec{h}_j] \right)\]원래는 모든 node 쌍에 점수를 매길 수 있지만, 그러면 graph 구조가 사라져요. GAT는 node $i$의 1차 neighbor $j \in \mathcal{N}_ i$(자기 자신 포함)에 대해서만 점수를 계산하는 masked attention을 써요. 그리고 neighbor 전체에 softmax를 적용해, 합이 1이 되는 weight $\alpha_{ij}$로 정규화해요.
\[\alpha_{ij} = \frac{\exp\left( \text{LeakyReLU}\left( \vec{a}^\top [W\vec{h}_i \, \| \, W\vec{h}_j] \right) \right)}{\sum_{k \in \mathcal{N}_i} \exp\left( \text{LeakyReLU}\left( \vec{a}^\top [W\vec{h}_i \, \| \, W\vec{h}_k] \right) \right)}\]$\alpha_{ij}$가 클수록 node $i$가 neighbor $j$를 더 중요하게 본다는 뜻이에요. 이 weight로 neighbor feature를 가중합하면 새 표현이 나와요. 모든 neighbor를 똑같이 더하던 GCN과 달리, 중요한 neighbor에 더 큰 $\alpha$가 곱해져요.
\[\vec{h}_i' = \sigma\left( \sum_{j \in \mathcal{N}_i} \alpha_{ij} W \vec{h}_j \right)\]멀티헤드로 학습을 안정화해요
Attention 하나만 쓰면 학습이 흔들릴 수 있어요. 그래서 독립적인 attention을 $K$개 두는 멀티헤드를 써요. 여러 시선으로 neighbor를 본 뒤, 중간 층에서는 결과를 이어 붙여 node당 $KF’$개의 feature를 만들어요.
\[\vec{h}_i' = \mathbin\Vert_{k=1}^{K} \sigma\left( \sum_{j \in \mathcal{N}_i} \alpha_{ij}^k W^k \vec{h}_j \right)\]마지막 예측 층에서는 이어 붙이는 대신 헤드들을 평균 내요.
\[\vec{h}_i' = \sigma\left( \frac{1}{K} \sum_{k=1}^{K} \sum_{j \in \mathcal{N}_i} \alpha_{ij}^k W^k \vec{h}_j \right)\]GAT는 eigen-decomposition 같은 무거운 연산이 없고, attention score를 edge마다 병렬로 계산할 수 있어요. Attention 함수가 모든 edge에 공유되므로 graph 구조를 미리 알 필요가 없고, 그래서 학습 때 보지 못한 graph에도 적용돼요. 실험에서 모든 neighbor에 같은 weight를 주는 모델(Const-GAT)보다 더 좋아서, neighbor마다 중요도를 다르게 주는 것이 도움이 된다는 점을 직접 보여줬어요.
GAT는 positional encoding를 쓰지 않아요
Transformer를 안다면 positional encoding가 떠오를 수 있어요. Transformer는 입력을 집합처럼 다뤄 순서 정보가 사라지니, 위치를 따로 더해줘야 해요. GAT는 이게 필요 없어요. Graph의 neighbor에는 원래 순서가 없어서, 순서에 무관한(permutation invariant) 게 오히려 올바른 성질이에요. 그래서 GAT는 위치를 주입하지 않고, 대신 masked attention으로 1차 neighbor에만 attention을 계산해 graph 구조를 반영해요.
다만 graph에서도 위치 정보를 쓰는 방법은 있어요. Laplacian eigenvector를 positional encoding으로 쓰는 방식이에요. Laplacian $L = \Sigma \Lambda \Sigma^\top$을 eigen-decomposition하면, 작은 eigenvalue의 eigenvector는 graph의 전역 구조를, 큰 eigenvalue의 eigenvector는 지역적 대칭을 담아요. 이 eigenvector matrix $\Sigma$의 각 행을 node의 위치 표현으로 더해주는 거예요.
한 가지 걸림돌은 eigenvector의 부호가 임의라는 점이에요. $v$가 eigenvector면 $-v$도 eigenvector라, 계산 알고리즘마다 부호가 무작위로 나와 예측이 흔들려요. 그래서 부호 뒤집기에 영향받지 않는(sign invariant) 신경망을 설계해요. $g(x) + g(-x)$ 형태로 만들면 $x$와 $-x$가 같은 값을 내는데, 이를 활용한 게 SignNet예요. 이런 방법은 GAT 이후의 graph Transformer 계열에서 쓰여요. 원본 GAT에는 없으니 이런 방향이 있다는 정도만 알아두면 돼요.
Aggregate, Combine으로 보면
GAT는 Aggregate 단계에 학습되는 attention weight를 넣은 점이 핵심이에요.
- Aggregate: neighbor feature를 attention score $\alpha_{ij}$로 가중합해요. GCN은 weight가 degree로 고정됐지만, 여기서는 두 node feature로 score를 계산해 node마다 다르게 학습돼요.
- Combine: 자기 자신도 neighbor 집합 $\mathcal{N}_i$에 포함시켜(self-loop) Aggregate 안에서 함께 가중합해요. 이 점은 GCN과 비슷하게 Combine이 Aggregate에 흡수된 형태예요. 멀티헤드 결과를 중간 층은 concat, 마지막 층은 평균으로 합쳐요.
중간 정리
세 논문은 “neighbor 정보를 어떻게 모을까”라는 같은 질문에 차례로 답해요.
GCN은 스펙트럼 합성곱을 한 단계 neighbor만 보는 형태로 단순화해, neighbor feature를 정규화해서 모으는 효율적인 기본기를 세웠어요. 다만 학습에 graph 전체가 필요한 transductive 방식이에요.
GraphSAGE는 표현 대신 “모으는 방법”을 학습하고 neighbor를 샘플링해, 보지 못한 node와 graph에도 쓰는 inductive 방식으로 넓혔어요. 평균·LSTM·pooling 등 다양한 aggregation을 적용할 수 있어요.
GAT는 neighbor를 똑같이 다루던 방식을 넘어, attention으로 neighbor마다 중요도를 학습해 표현력을 높였어요. 구조를 미리 알 필요가 없어 inductive에도 자연스러워요.
Aggregate와 Combine 관점으로 보면 차이가 한눈에 들어와요. Aggregate는 GCN이 degree로 고정한 가중합, GraphSAGE가 mean·LSTM·pooling 중 선택, GAT가 학습되는 attention 가중합으로 점점 유연해져요. Combine은 GCN과 GAT가 self-loop로 Aggregate에 흡수한 반면, GraphSAGE는 self representation을 concat하는 방식을 사용해요.
정리하면 GCN은 효율적인 기본기, GraphSAGE는 일반화, GAT는 neighbor weight의 유연함을 더한 흐름이에요. 이후의 graph 신경망 연구 대부분이 이 세 갈래 위에서 출발해요.
Layer를 쌓는다고 성능이 좋아지지 않아요
세 모델 모두 층을 쌓아 더 먼 neighbor까지 본다고 했어요. 그러면 층을 아주 많이 쌓으면 좋을까요. 그렇지 않아요. Graph에서는 층을 늘리면 over-smoothing 문제가 생겨요.
층을 하나 쌓을 때마다 node가 보는 범위, 즉 receptive field가 한 단계씩 넓어져요. $K$층이면 $K$-hop neighbor까지 정보가 들어와요. 그런데 graph는 보통 좁아서, 몇 단계만 가도 거의 모든 node가 서로의 receptive field에 들어와요. 서로 다른 두 node가 결국 거의 같은 neighbor 집합을 모으게 되는 거예요. 그러면 모든 node 표현이 비슷해져 구별이 사라져요. 이게 over-smoothing이에요. 다른 분야 신경망과 달리, GNN은 층을 더 쌓는다고 항상 좋아지지 않아요. 층 수는 필요한 receptive field 반경보다 조금 많은 정도가 적당하고, 지나치게 깊게 쌓지 않는 게 좋아요.
표현력이 부족하다면 층을 더 쌓는 대신 다른 방법을 써요. 하나의 층 안에서 표현력을 키우는 거예요. Aggregate나 Combine을 단순한 선형 변환 대신 깊은 신경망으로 만들면 돼요. 다른 하나는 메시지를 주고받지 않는 층을 더하는 거예요. GNN이 GNN 층만으로 이뤄질 필요는 없어요. 각 node에 따로 적용하는 MLP 층을 GNN 층 앞뒤에 전처리·후처리로 두면 도움이 돼요. 깊게 쌓아야 한다면 skip connection을 더하는 방법도 있어요. 초기 층이 오히려 node를 더 잘 구별하는 경우가 있어서, 입력을 뒤쪽 층으로 바로 잇는 지름길을 만들어 초기 표현이 묻히지 않게 해요. Skip connection은 모델을 섞는 효과를 내요. 얕은 GNN과 깊은 GNN이 섞인 형태가 되는 거예요. Skip connection이 $N$개면 정보가 흐를 수 있는 경로가 $2^N$가지 생겨, 여러 깊이의 모델을 동시에 쓰는 셈이에요. GraphSAGE의 concat이나 GAT가 self representation을 함께 넣는 것도 같은 이유에요.
GNN 직접 만들어보자
마지막으로 GAT를 Cora 데이터셋에 학습하는 예제를 살펴볼게요. Cora는 논문 인용 graph로, node는 논문, edge는 인용 관계, feature는 bag-of-words, label는 논문 주제예요. 전체 코드는 Github(sungjin-code/deep-learning-codes/gnn-example)에 있고, 여기서는 핵심만 요약할게요.
데이터는 어떻게 나눌까
학습에는 데이터를 train/validation/test로 나눠요. 그런데 graph는 이미지와 달리 node가 서로 독립이 아니에요. 메시지 전달 때문에, validation이나 test node도 train node의 예측에 영향을 줘요. Node 하나를 떼어내도 그 neighbor가 여전히 정보를 흘려보내거든요. 그래서 graph 데이터를 나누는 방식은 두 가지예요.
- Transductive: graph 전체를 모든 split이 함께 봐요. 단 label는 train split만 보여요. Node 분류에서 가장 흔한 방식이에요.
- Inductive: split 사이의 edge를 끊어 여러 개의 분리된 graph로 만들어요. 그러면 서로 다른 조각의 node가 진짜로 독립이에요. Graph 분류에는 이 방식만 쓸 수 있어요.
Cora 예제는 transductive 방식이에요. 하나의 graph 위에서 어떤 node를 학습/검증/평가에 쓸지 마스크로 구분해요. Graph 구조와 모든 node의 feature는 항상 다 보이고, 손실 계산에 쓰는 label만 마스크로 가려요.
1
2
3
4
5
6
7
8
9
10
11
12
import dgl
from dgl.data import CoraGraphDataset
dataset = CoraGraphDataset()
graph = dataset[0]
graph = dgl.add_self_loop(dgl.remove_self_loop(graph))
features = graph.ndata["feat"] # node feature (bag-of-words)
labels = graph.ndata["label"] # node label (논문 주제)
train_mask = graph.ndata["train_mask"].bool()
val_mask = graph.ndata["val_mask"].bool()
test_mask = graph.ndata["test_mask"].bool()
마스크는 어떤 node를 쓸지 고르는 boolean 배열이에요. 모델은 항상 graph 전체로 예측을 내지만, 손실과 평가는 해당 split의 node에만 적용해요.
GAT 모델을 정의해요
DGL의 GATConv로 GAT 층을 쌓아요. 첫 층은 멀티헤드 attention을 쓰고 결과를 concat해, 출력 차원이 hidden_size * num_heads가 돼요. 마지막 층은 헤드를 하나 두고 평균을 내서 클래스 수만큼 logit을 내요. 글에서 설명한 “중간 층은 concat, 마지막 층은 평균”이 그대로 코드에 나타나요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn import GATConv
class GAT(nn.Module):
def __init__(self, in_size, hidden_size, out_size, num_heads, dropout):
super().__init__()
self.gat1 = GATConv(in_size, hidden_size, num_heads,
feat_drop=dropout, attn_drop=dropout, activation=F.elu)
self.gat2 = GATConv(hidden_size * num_heads, out_size, 1,
feat_drop=dropout, attn_drop=dropout, activation=None)
def forward(self, graph, features):
hidden = self.gat1(graph, features).flatten(1) # 멀티헤드 concat
logits = self.gat2(graph, hidden)
return logits.mean(1) # 마지막 층 평균
feat_drop과 attn_drop은 feature와 attention 계수에 적용하는 dropout예요. Cora는 train split이 작아서, dropout와 weight decay로 과적합을 줄이는 게 중요해요.
학습 루프를 돌려요
학습은 일반적인 분류 모델과 비슷해요. 다른 점은 graph 전체로 예측을 낸 뒤 train 마스크에 해당하는 node에만 손실을 계산한다는 거예요.
1
2
3
4
5
6
7
8
9
10
11
12
13
import torch
model = GAT(features.shape[1], hidden_size=8, out_size=num_classes,
num_heads=8, dropout=0.6)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)
for epoch in range(epochs):
model.train()
logits = model(graph, features) # 전체 node 예측
loss = F.cross_entropy(logits[train_mask], labels[train_mask]) # train만 손실
optimizer.zero_grad()
loss.backward()
optimizer.step()
검증과 평가도 같은 logit에서 마스크만 바꿔요. Transductive 방식이라 같은 graph, 같은 예측에서 어떤 node를 볼지만 바꾸는 점이 핵심이에요.
Graph 구조는 성능에 얼마나 기여할까
Graph 구조가 실제로 도움이 되는지 보려면, 같은 node feature를 쓰되 graph를 안 쓰는 모델과 비교하면 돼요. Baseline으로 node feature만 입력받는 Transformer를 두고, GAT와 같은 Cora split에서 학습했어요. 둘의 차이는 neighbor 정보를 참고하느냐에요. Test split 결과는 아래와 같아요.
| Metric | w/ graph | w/o graph |
|---|---|---|
| Accuracy | 0.828 | 0.569 |
| Macro F1 | 0.818 | 0.557 |
| Weighted F1 | 0.829 | 0.573 |
| MCC | 0.792 | 0.486 |
| ROC-AUC | 0.972 | 0.857 |
Graph 구조를 쓴 GAT가 모든 지표에서 크게 앞서요. Test accuracy는 0.828 대 0.569로 26%p 차이예요. 두 모델이 같은 node feature를 봤으니, 이 격차는 neighbor 정보를 모은 데서 왔다고 볼 수 있어요.
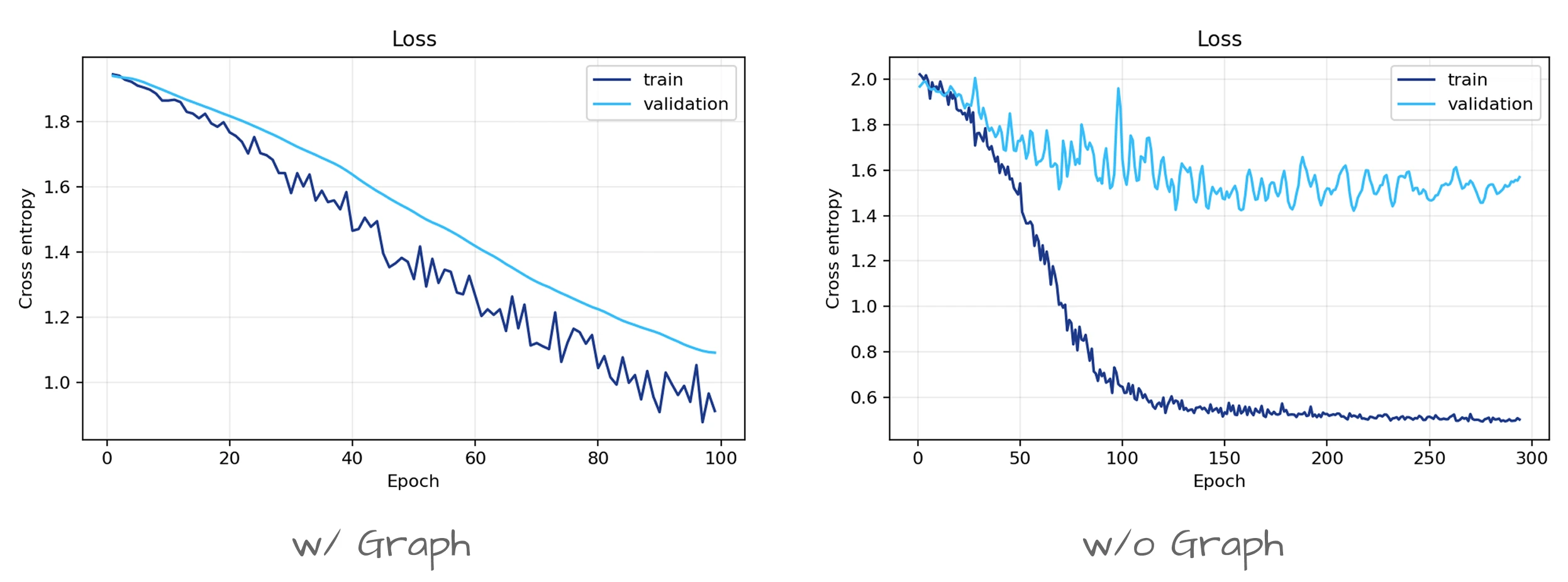
Train 결과를 함께 보면 차이가 더 분명해요. Graph 구조를 사용하지 않은 Transformer는 train accuracy가 1.0인데 test는 0.569로 크게 떨어져요. Node feature만으로 학습 데이터를 외웠을 뿐, 새 node에는 일반화하지 못한 거예요. GAT는 train 0.993, test 0.828로 격차가 작아요. Neighbor 정보가 일종의 정규화처럼 작용해, 인용 관계로 연결된 논문은 주제가 비슷하다는 구조적 단서를 모델이 활용한 결과예요.
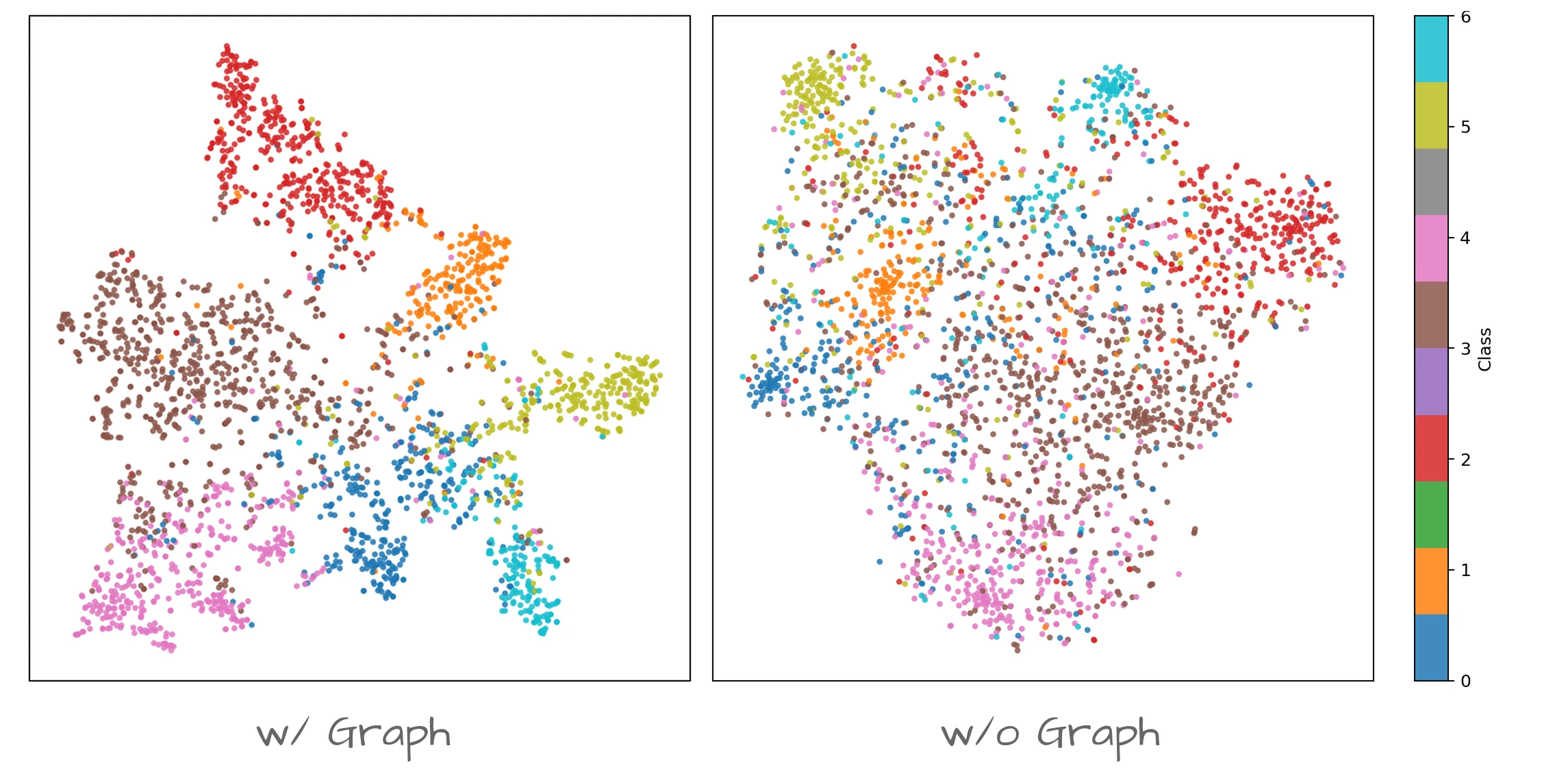
Embedding 공간을 t-SNE로 시각화한 결과를 봐도 Graph를 사용한 쪽이 정보를 더 잘 구조화했음을 볼 수 있어요.