그래프로 보는 멀티모달 추천 시스템
추천 시스템의 데이터는 user와 item의 상호작용 기록이에요. 상호작용은 sparse하고, 새로 들어온 item은 기록이 전혀 없어요(cold start). 이를 보완하려면 item의 image나 text 같은 modality 정보를 활용해야 해요. 이때 multimodal recommendation을 쓸 수 있어요.
이 글에서는 5개 논문을 따라가며 modality가 추천에서 맡는 역할이 어떻게 바뀌어 왔는지 살펴봐요. 처음에는 점수에 더하는 정적인 side-feature였다가, graph를 정제하는 도구가 되고, self-supervised 학습의 정렬 대상이 되었다가, 마지막에는 생성 모델의 입력으로 통합돼요. 다섯 모델 모두 user 집합 $\mathcal{U}$, item 집합 $\mathcal{I}$, 클릭이나 시청 같은 implicit feedback을 공통 재료로 써요.
- VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback, AAAI 2016, arxiv.
- Neural Graph Collaborative Filtering, SIGIR 2019, arxiv.
- LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation, SIGIR 2020, arxiv.
- GRCN: Graph-Refined Convolutional Network for Multimedia Recommendation, ACM MM 2020, arxiv.
- Bootstrap Latent Representations for Multi-modal Recommendation, WWW 2023, arxiv.
- 수십억 개 연결이 존재하는 당근 그래프에서 GNN 학습하기, 2024 당근 테크 밋업, youtube.
Visual feature를 반영하자
VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback (AAAI 2016)
Matrix Factorization 기반 추천은 user $u$가 item $i$를 선호하는 정도를 다음 점수로 예측해요.
\[\hat{x}_{ui} = \alpha + \beta_u + \beta_i + \gamma_u^\top \gamma_i\]$\gamma_u, \gamma_i$는 학습되는 latent embedding이고, $\beta$는 bias 항, $\alpha$는 전체 평균이에요. 이 embedding은 상호작용 기록에서만 학습돼요. 그래서 기록이 적은 item은 $\gamma_i$가 부정확하고, 기록이 없는 새 item은 학습 자체가 불가능해요. 패션처럼 새 상품이 계속 들어오는 도메인에서 이 cold start 문제는 치명적이에요.
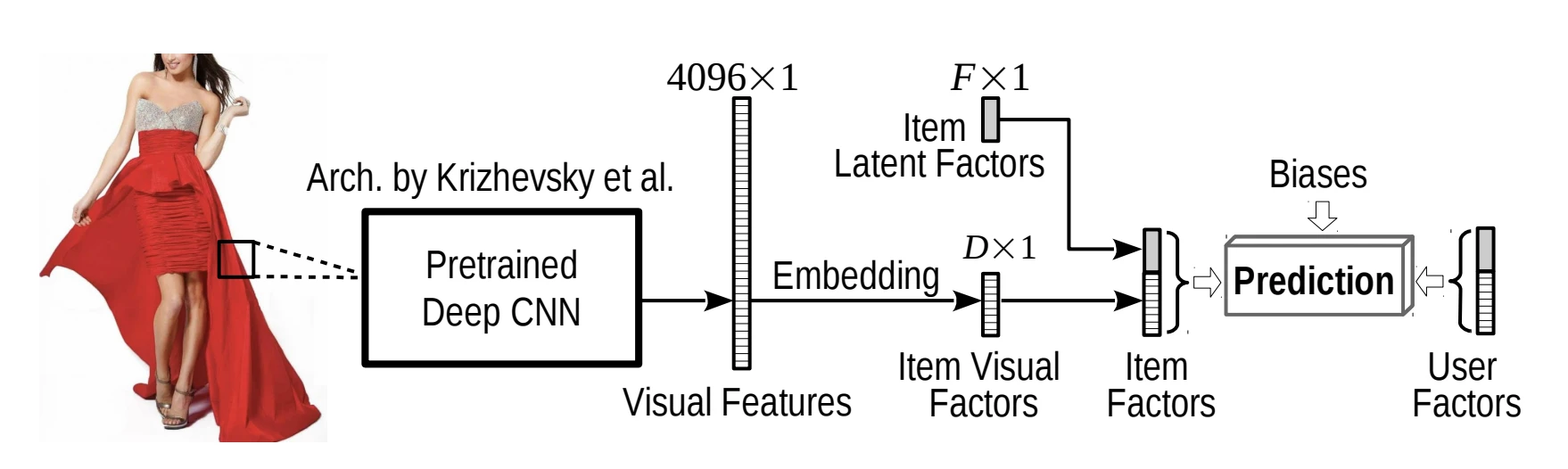
VBPR(Visual Bayesian Personalized Ranking)은 선호도를 두 종류로 나눠요. 하나는 기존 latent 차원 $\gamma_u^\top \gamma_i$이고, 다른 하나는 겉모습으로 설명되는 visual 차원이에요.
\[\hat{x}_{ui} = \alpha + \beta_u + \beta_i + \gamma_u^\top \gamma_i + \theta_u^\top \theta_i + \beta_v^\top f_i\]$f_i$는 pretrained CNN으로 미리 추출한 item image의 4096차원 feature예요. 이 feature는 학습 중 고정하고, projection matrix $\mathbf{E}$로 저차원 visual space에 투영해 $\theta_i = \mathbf{E} f_i$를 만들어요. $\theta_u$는 user가 어떤 겉모습을 선호하는지를 담은 visual 취향 벡터이고, $\theta_u^\top \theta_i$가 user 취향과 item 외형의 일치도를 점수에 더해요. 마지막 $\beta_v^\top f_i$는 특정 외형이 전반적으로 인기 있는 정도를 담은 visual bias예요.
여기서 학습 대상이 $\mathbf{E}$라는 점이 중요해요. 4096차원을 그대로 쓰면 파라미터가 폭발하지만, $\mathbf{E}$로 차원을 줄여 user 취향과 비교할 수 있는 작은 공간으로 옮겨요.
전체 프로세스를 행렬로 보면 흐름이 한눈에 들어와요. 출발점은 interaction matrix $R \in {0,1}^{|\mathcal{U}| \times |\mathcal{I}|}$예요. $R_{ui} = 1$이면 user $u$가 item $i$를 클릭한 기록이 있다는 뜻이에요. 동시에 모든 item의 visual feature를 행으로 쌓아 feature matrix $F \in \mathbb{R}^{|\mathcal{I}| \times 4096}$을 만들어요. 이 $F$는 pretrained CNN 출력을 그대로 가져온 것이라 학습 중 고정돼요. 모델이 학습하는 파라미터는 user latent factor matrix $\Gamma_U \in \mathbb{R}^{|\mathcal{U}| \times K}$, item latent factor matrix $\Gamma_I \in \mathbb{R}^{|\mathcal{I}| \times K}$, user visual preference matrix $\Theta_U \in \mathbb{R}^{|\mathcal{U}| \times D}$, 그리고 projection matrix $\mathbf{E} \in \mathbb{R}^{D \times 4096}$이에요. 전체 점수 행렬은 다음과 같이 써요.
\[\hat{X} = \Gamma_U \Gamma_I^\top + \Theta_U (\mathbf{E} F^\top) + \mathbf{1}(\beta_v^\top F^\top)\]Bias 항은 생략했어요. 첫째 항 $\Gamma_U \Gamma_I^\top$이 기존 MF(Matrix Factorization)의 collaborative score이고, 둘째 항 $\Theta_U (\mathbf{E} F^\top)$이 VBPR이 추가한 visual score예요. $\mathbf{E} F^\top$은 모든 item의 visual feature를 $D$차원으로 투영한 행렬이고, $\Theta_U$와 곱하면 모든 user-item 쌍의 visual 일치도가 한 번에 나와요. 학습 때는 $R$에서 $R_{ui}=1$인 positive item $i$와 $R_{uj}=0$인 negative item $j$를 뽑아 triplet을 만들고, $\hat{X}_ {ui} - \hat{X}_ {uj}$가 커지도록 BPR(Bayesian Personalized Ranking) loss로 학습해요.
\[L_{BPR} = \sum_{(u,i,j)} -\ln \sigma(\hat{x}_{ui} - \hat{x}_{uj}) + \lambda \lVert \Theta \rVert^2\]$\sigma$는 sigmoid예요. 점수의 절댓값이 아니라 두 item의 점수 차이만 학습하므로, 명시적인 평가 없이 클릭 여부만으로 순위를 학습할 수 있어요. $\lambda \lVert \Theta \rVert^2$는 regularization term이에요.
핵심은 $f_i$가 상호작용과 무관하게 image만으로 얻어진다는 점이에요. 덕분에 기록이 없는 item도 visual 항으로 선호도를 추정할 수 있어 cold start가 완화돼요. 다만 modality는 점수에 더해지는 정적인 side-feature에 머물러요. user와 item의 관계도 직접 연결된 상호작용까지만 보고, 그 너머의 연결은 반영하지 못해요.
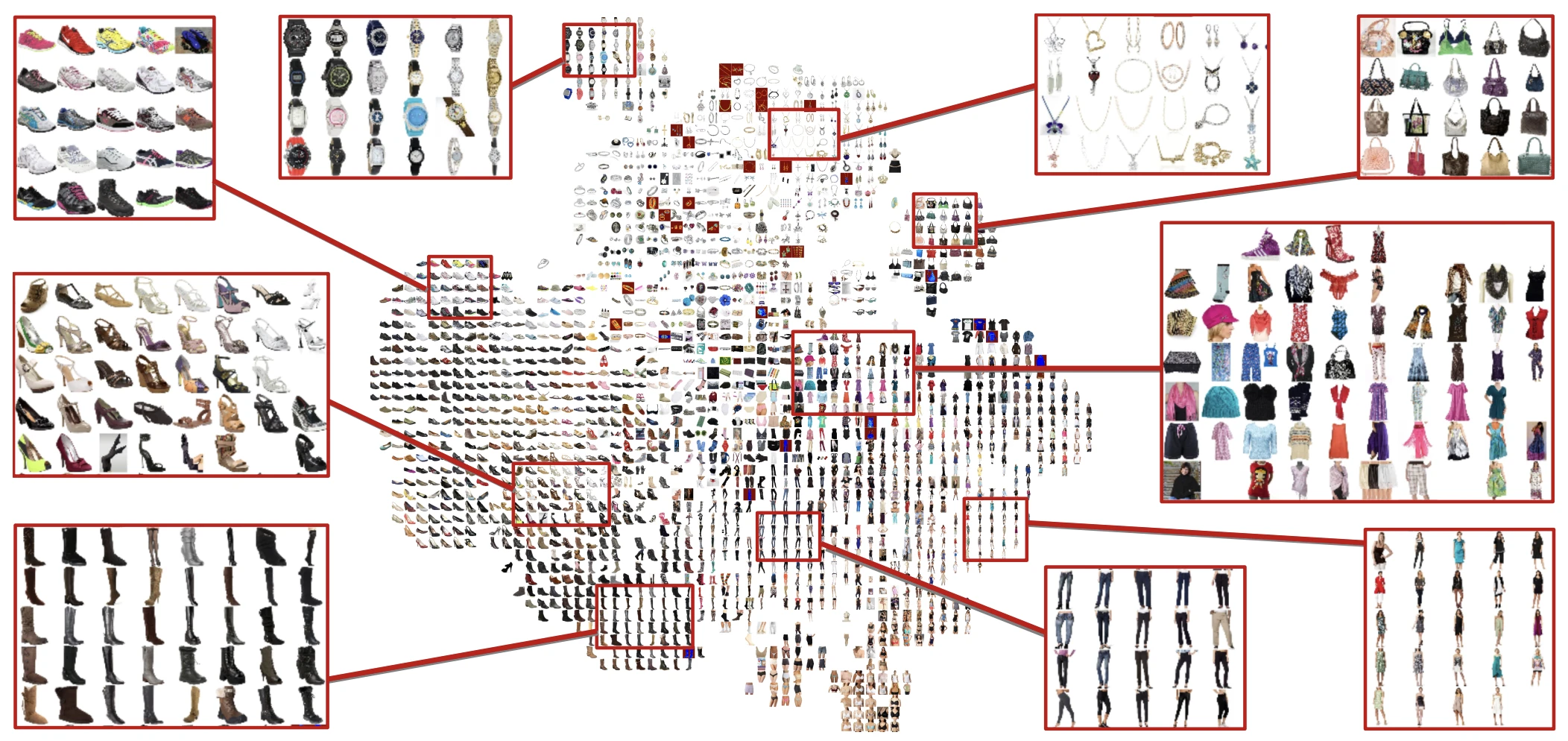
Amazon Women로 학습한 모델의 test set을 t-SNE로 시각화 해보니 같은 카테고리의 item끼리 임베딩된 것을 확인할 수 있어요.
NGCF는 상호작용을 graph로 전파하자
Neural Graph Collaborative Filtering (SIGIR 2019)
VBPR의 embedding은 user, item마다 독립적으로 학습돼요. User $u$가 좋아한 item을 또 좋아한 다른 user, 그 user가 본 또 다른 item 같은 high-order connectivity은 점수에 직접 반영되지 않아요. 이런 연결은 “비슷한 취향의 user가 좋아한 item”이라는 collaborative signal을 담고 있어서, 잘 활용하면 sparse한 기록을 보완할 수 있어요.
NGCF(Neural Graph Collaborative Filtering)는 user-item 상호작용을 bipartite graph로 보고, embedding을 이웃으로 전파해 이 신호를 명시적으로 주입해요.
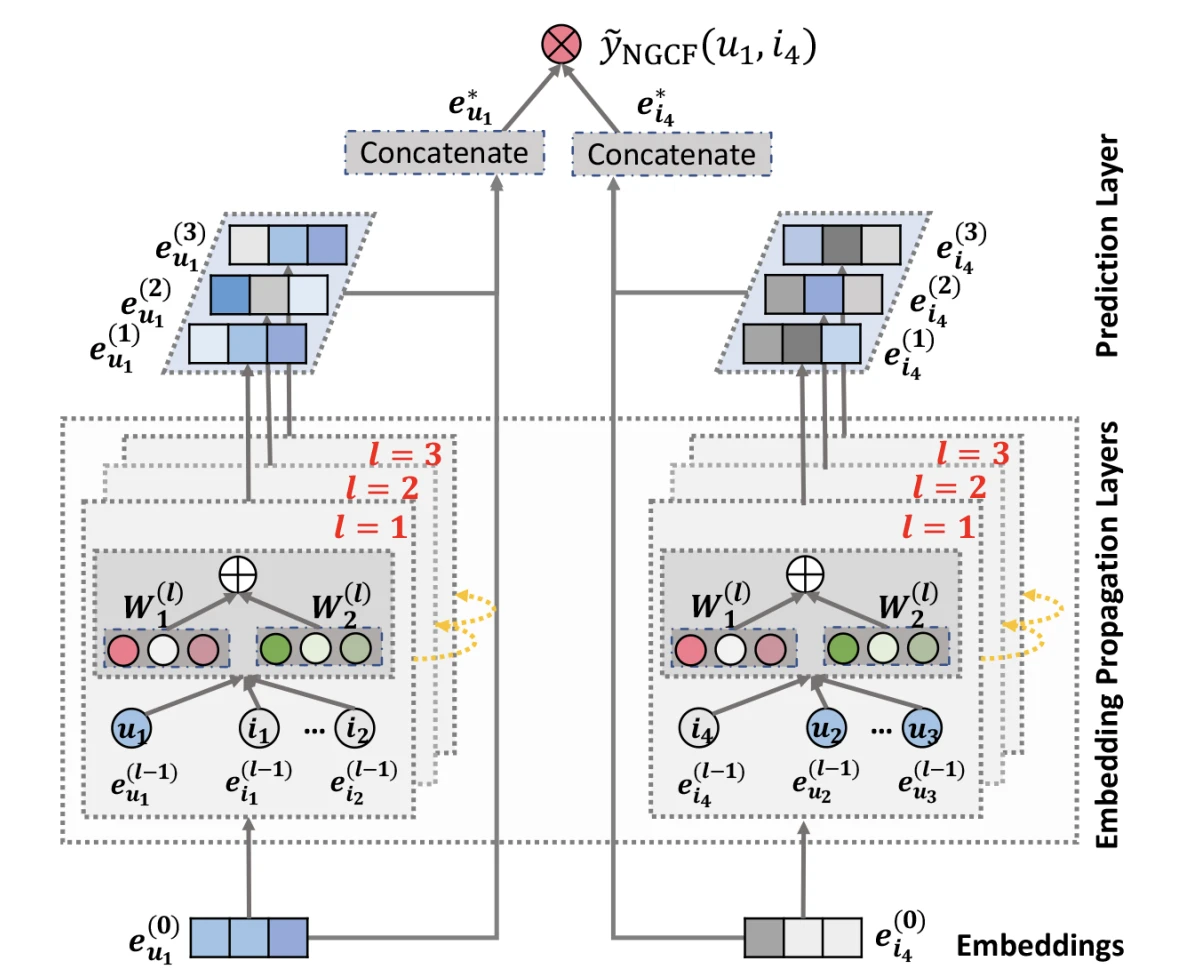
Item $i$에서 user $u$로 전달되는 message는 다음과 같아요.
\[m_{u \leftarrow i} = \frac{1}{\sqrt{\lvert \mathcal{N}_u \rvert \lvert \mathcal{N}_i \rvert}} \left( W_1 e_i + W_2 (e_i \odot e_u) \right)\]$\lvert \mathcal{N} \lvert$은 이웃 집합의 개수이고, $\frac{1}{\sqrt{\lvert \mathcal{N}_ u \rvert \lvert \mathcal{N}_ i \rvert}}$는 인기 많은 노드의 신호가 과도하게 커지지 않도록 하는 정규화 계수예요. 주목할 항은 $e_i \odot e_u$예요. 일반적인 GCN은 이웃 feature를 그대로 더하지만, NGCF는 두 노드의 element-wise 곱을 함께 전달해요. 취향이 맞는(임베딩이 비슷한) user-item 쌍일수록 이 항이 커져 더 강한 신호를 주고받아요. 자기 자신 message $m_{u \leftarrow u} = W_1 e_u$까지 더해 한 layer를 갱신해요.
\[e_u^{(l+1)} = \text{LeakyReLU}\!\left( m_{u \leftarrow u} + \sum_{i \in \mathcal{N}_u} m_{u \leftarrow i} \right)\]한 layer는 1-hop 이웃을, $L$개 layer를 쌓으면 $L$-hop 떨어진 노드까지 신호가 도달해요. 각 layer는 서로 다른 거리의 연결을 담으므로, 마지막에는 모든 layer의 출력을 concat해 최종 표현을 만들고 내적으로 선호도를 예측해요.
\[e_u^{*} = e_u^{(0)} \,\Vert\, \cdots \,\Vert\, e_u^{(L)}, \qquad \hat{y}_{ui} = e_u^{*\top} e_i^{*}\]학습은 VBPR과 같은 BPR loss를 써요.
NGCF 자체는 multi-modality를 쓰지 않아요. 하지만 상호작용 구조를 graph로 모델링하는 이 backbone이 이후 multimodal 모델의 토대가 돼요. 참고로 후속 연구인 LightGCN은 $W_1, W_2$와 비선형성을 모두 제거하고 이웃의 가중합만 남겨도 성능이 더 좋다는 것을 보였어요.
\[e_u^{(l+1)} = \sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{|\mathcal{N}_u||\mathcal{N}_i|}}\, e_i^{(l)}\]이어지는 GRCN과 BM3는 이 단순화된 propagation 위에서 동작해요.
GRCN은 modality로 graph를 정제하자
Graph-Refined Convolutional Network for Multimedia Recommendation (ACM MM 2020)
암묵적 피드백(implicit feedback)에는 noise가 섞여 있어요. 실수로 클릭하거나 친구가 공유해서 잠깐 본 micro-video도 상호작용으로 기록되는데, 이런 false-positive edge가 graph에 남으면 문제가 돼요. GCN은 이웃의 신호를 모아 표현을 만드는데, false-positive 이웃의 신호까지 섞여 들어와 user 취향이 오염돼요. Layer를 쌓을수록 이 noise가 multi-hop으로 퍼져 더 나빠져요.
GRCN(Graph-Refined Convolutional Network)은 modality content로 어떤 edge가 false-positive인지 판단해 그 영향을 줄여요. “false-positive item의 content는 user 취향과 멀 것”이라는 가정을 활용해요. 모델은 graph refining, graph convolutional, prediction 세 layer로 이뤄져요.
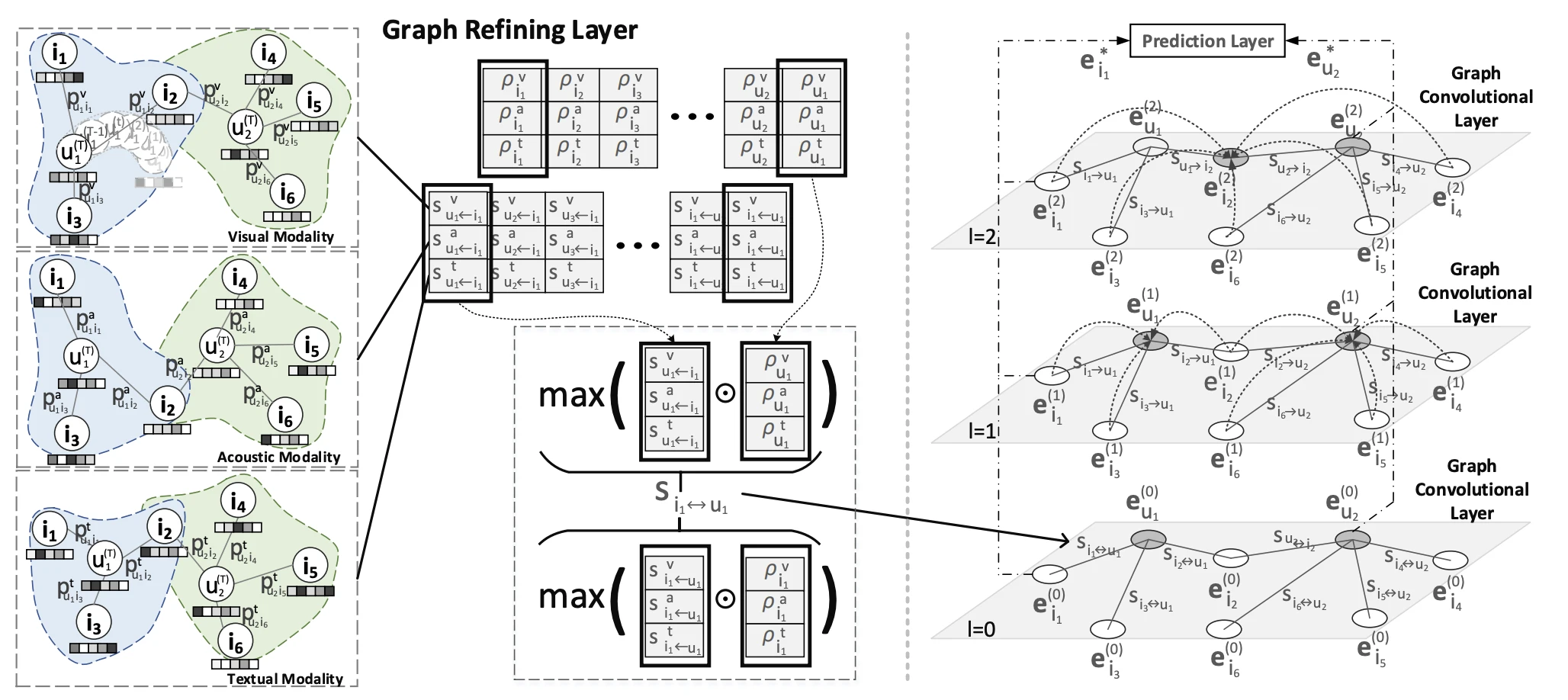
Prototypical network로 취향을 추정하자
Edge의 진위를 판단하려면 먼저 user의 취향이 뭔지 알아야 해요. GRCN은 user가 연결된 item들의 content를 보고 취향을 추정하는데, 단순 평균을 내면 false-positive item의 content도 섞여요. 그래서 prototypical network를 써서, 취향에 맞는 item은 크게, 안 맞는 item은 작게 반영하면서 취향 벡터를 반복적으로 다듬어요.
출발은 item content를 비교 가능한 공간으로 옮기는 거예요. Modality $m$의 raw feature $i_m$(예: image라면 2048차원 CNN feature)을 학습 가능한 $W_m$으로 저차원 metric space에 투영해요.
\[\bar{i}_m = \text{LeakyReLU}(W_m i_m + b_m)\]$\bar{i}_m$은 “이 item이 취향 공간에서 어디에 놓이는가”를 나타내는 벡터예요. 이 공간에서 user 취향 벡터 $u$를 구하는 게 목표예요.
User 취향 벡터는 학습 가능한 초기 벡터 $u^{(0)}$에서 시작해요. 아직 아무 item 정보도 반영되지 않은 상태예요. 여기서 아래 두 식을 $T$번 반복해요.
\[p_{u,i} = \frac{\exp(\bar{i}^\top u^{(t-1)})}{\sum_{j \in \mathcal{N}(u)} \exp(\bar{j}^\top u^{(t-1)})}, \qquad u^{(t)} = u^{(t-1)} + \sum_{i \in \mathcal{N}(u)} p_{u,i}\, \bar{i}\]왼쪽 식부터 볼게요. $p_{u,i}$는 현재 취향 벡터 $u^{(t-1)}$과 이웃 item $\bar{i}$의 내적을 softmax로 정규화한 값이에요. $\mathcal{N}(u)$는 $u$에 연결된 item 집합이고, softmax 덕분에 모든 이웃에 대한 $p_{u,i}$의 합이 1이 돼요. 지금 취향 벡터와 방향이 비슷한 item일수록 $p_{u,i}$가 커요.
오른쪽 식은 이 가중치로 이웃 item들의 가중합을 구해 취향 벡터에 더하는 거예요. $p_{u,i}$가 큰 item, 즉 현재 취향과 가까운 item의 content가 $u^{(t)}$를 더 세게 끌어당겨요. 처음엔 $u^{(0)}$이 random에 가까워서 $p_{u,i}$가 거의 균등하지만, 갱신이 반복되면서 취향 벡터가 특정 item 군집 방향으로 수렴하고, 그 군집과 동떨어진 false-positive item은 $p_{u,i}$가 점점 낮아져 거의 기여하지 못해요. $T$번 반복한 $\bar{u} = u^{(T)}$가 modality $m$에서의 user 취향 prototype이에요.
Affinity score로 edge를 soft pruning하자
Edge $(u, i)$의 신뢰도는 user 취향 prototype과 item content의 유사도로 매겨요. 이웃 안에서 softmax로 정규화해요.
\[\bar{s}^m_{u \leftarrow i} = \frac{\exp(\bar{u}_m^\top \bar{i}_m)}{\sum_{j \in \mathcal{N}(u)} \exp(\bar{u}_m^\top \bar{j}_m)}\]여러 modality의 score는 user별 modality 선호도를 담은 base vector $\rho_u$로 가중한 뒤 max로 합쳐요.
\[s_{u \leftarrow i} = \max\left( \rho_u^v\, \bar{s}^v_{u \leftarrow i},\; \rho_u^a\, \bar{s}^a_{u \leftarrow i},\; \rho_u^t\, \bar{s}^t_{u \leftarrow i} \right)\]이 $s_{u \leftarrow i}$가 정제된 graph의 edge weight가 돼요. Affinity가 낮은 edge는 weight가 작아 신호가 거의 전달되지 않는데, 논문은 이를 soft pruning이라고 불러요. ReLU로 edge를 아예 끊는 hard pruning과 비교하면, soft 방식이 noise는 줄이면서 true-positive의 신호는 살려 더 좋은 결과를 보였어요. Modality를 합칠 때도 mean보다 max가 좋았는데, user가 특정 modality에서만 강하게 반응하는 경우를 max가 더 잘 잡기 때문이에요.
정제된 graph 위에서 전파한다
정제된 weight로 ID embedding을 LightGCN처럼 전파하고 layer를 합쳐요.
\[e_u^{(l)} = \sum_{i \in \mathcal{N}(u)} s_{u \leftarrow i}\, e_i^{(l-1)}, \qquad e_u = \sum_{l=0}^{L} e_u^{(l)}\]예측은 collaborative embedding과 modality 취향을 concat해 내적해요.
\[e_u^{*} = e_u \,\Vert\, \bar{u}_v \,\Vert\, \bar{u}_a \,\Vert\, \bar{u}_t, \qquad \hat{y}_{ui} = e_u^{*\top} e_i^{*}\]학습은 BPR loss를 써요.
여기서 modality의 역할이 달라져요. VBPR에서 modality는 점수에 더해지는 feature였지만, GRCN에서는 graph 구조 자체의 품질을 판단하고 개선하는 도구가 돼요.
BM3는 negative sample 없이 self-supervised로 학습한다
Bootstrap Latent Representations for Multi-modal Recommendation (WWW 2023)
GRCN 계열 graph 모델은 두 가지 비용이 커요. 하나는 user-user, item-item 같은 auxiliary graph 위에서의 무거운 GCN 연산이에요. 다른 하나는 BPR loss를 위한 negative sampling이에요. User마다 보지 않은 item을 무작위로 뽑아 negative로 쓰는데, 이건 연산량을 늘릴 뿐 아니라 “안 봤다”가 “싫다”는 아니므로 잘못된 supervision을 더하기도 해요.
BM3는 둘 다 없애요. 핵심은 representation에 dropout만 적용해 contrastive view를 만드는 거예요.
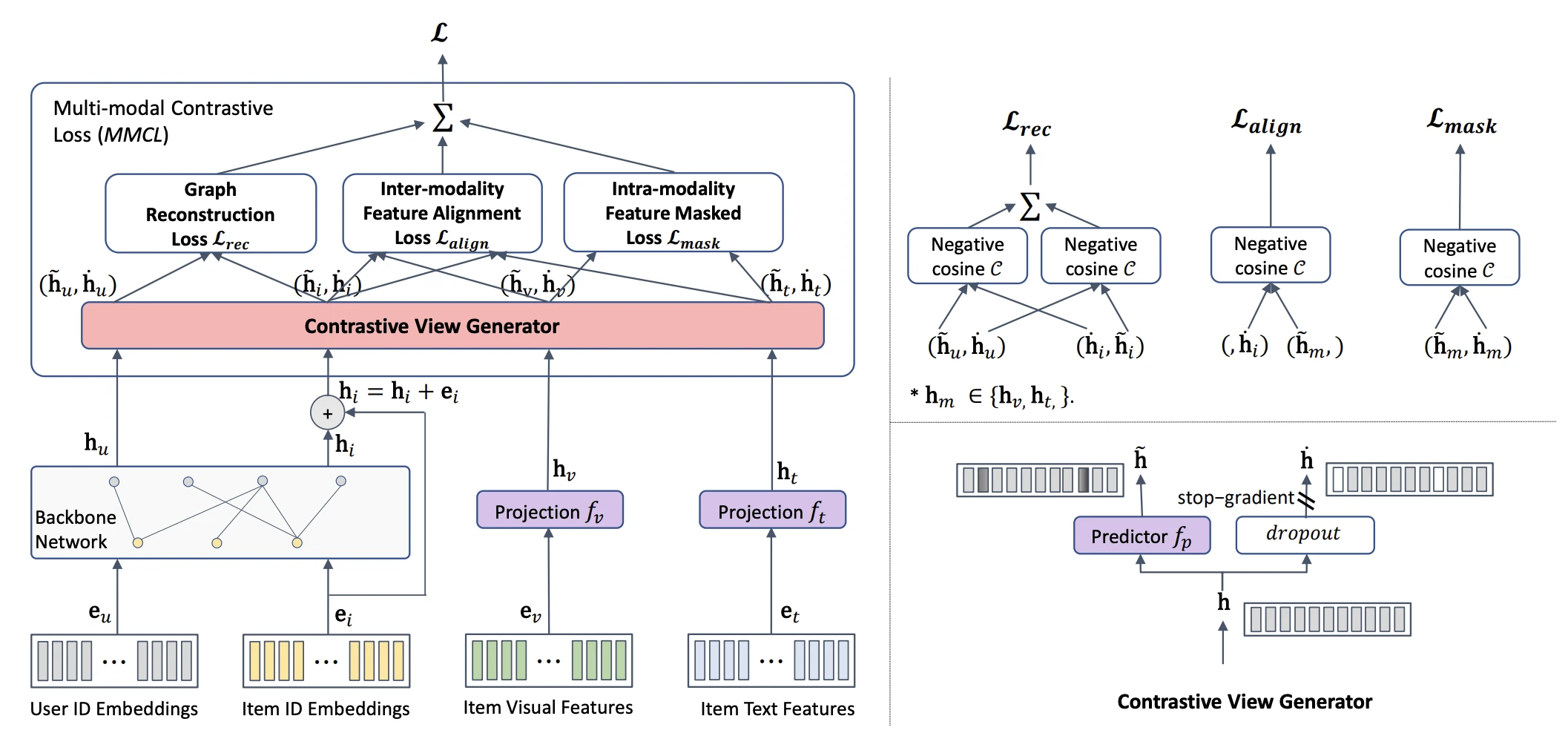
Dropout으로 꼼수 부리기
BM3가 다루는 표현은 두 종류예요. 하나는 ID embedding을 user-item bipartite graph 위에서 LightGCN처럼 전파해 얻는 collaborative 표현이고, 다른 하나는 item의 modality feature(image, text)를 MLP로 투영한 modality 표현이에요. 여기서 fusion이란 이 둘을 합치는 거예요. 가장 단순하게는 ID 기반 collaborative 표현과 각 modality 표현을 element-wise로 더해 하나의 통합 표현 $h_i$를 만들어요.
Online 표현 $h$를 얻었으면, 같은 표현에 dropout을 적용해 target view $\tilde{h}$를 만들어요. Dropout은 벡터의 일부 차원을 무작위로 0으로 만드는 연산이라, $h$와 $\tilde{h}$는 같은 의미를 담되 약간 다른 벡터가 돼요. 같은 입력에서 나온 두 view는 의미가 같아야 하므로, 둘을 가깝게 당기는 것이 학습 신호가 돼요. 이 발상은 BYOL(Bootstrap Your Own Latent)에서 왔어요. BYOL이 momentum으로 천천히 갱신되는 별도 target network를 두는 것과 달리, BM3는 dropout 한 번으로 target view를 얻어 구조를 크게 단순화했어요. Negative가 없어도 표현이 한 점으로 붕괴하지 않는 이유는 아래 reconstruction이 표현을 실제 상호작용 구조에 묶어두기 때문이에요.
세 가지 목적을 함께 최적화
학습은 세 loss를 더해 진행해요. 첫째는 user-item 상호작용을 복원하는 reconstruction loss예요. 연결된 user와 item의 두 view를 서로 가깝게 당겨 graph 구조를 표현에 새겨요.
\[L_{rec} = \sum_{(u,i)} \big(1 - \cos(h_u, \tilde{h}_i)\big) + \big(1 - \cos(\tilde{h}_u, h_i)\big)\]$(u, i)$는 실제 상호작용이 있는 쌍이에요. User의 online view $h_u$를 item의 target view $\tilde{h}_i$에, 그리고 반대로 $\tilde{h}_u$를 $h_i$에 맞춰요. 두 방향을 모두 정렬하는 이유는 대칭성을 주기 위해서예요. 이 loss가 없으면 표현이 상호작용과 무관하게 학습돼 추천이 안 되고, 동시에 이 loss가 표현을 graph 구조에 묶어두기 때문에 negative 없이도 모든 표현이 한 점으로 붕괴하는 것을 막아요.
둘째는 inter-modality 정렬이에요. 같은 item의 각 modality 표현 $\tilde{h}_i^m$을 fusion된 표현 $h_i$에 맞춰, image와 text가 같은 item을 일관되게 가리키게 해요.
\[L_{inter} = \sum_i \sum_m \big(1 - \cos(h_i, \tilde{h}_i^m)\big)\]예를 들어 어떤 영화의 포스터(image)와 줄거리(text)는 같은 영화를 설명하니까, 두 modality의 표현이 fusion 표현과 방향이 같아야 해요. $m$은 modality를 순회하는 인덱스라서, image와 text 각각에 대해 이 정렬이 적용돼요.
셋째는 intra-modality 정렬이에요. 같은 modality에서 만든 두 view를 맞춰, 각 modality 표현이 dropout에 흔들리지 않게 안정화해요.
\[L_{intra} = \sum_i \sum_m \big(1 - \cos(h_i^m, \tilde{h}_i^m)\big)\]$h_i^m$과 $\tilde{h}_i^m$은 같은 modality feature에서 나온 online view와 target view예요. Dropout으로 차원 일부가 꺼져도 의미가 흔들리지 않는 robust한 표현을 만드는 역할이에요.
세 loss를 더해 한 번에 학습해요. $L_{rec}$가 graph 구조를, $L_{inter}$가 modality 간 일관성을, $L_{intra}$가 각 modality의 안정성을 담당해서, 세 관점이 서로 보완해요. Negative sampling과 auxiliary graph가 사라져, 같은 데이터에서 학습 시간이 2~9배 줄었어요.
Modality의 역할이 또 바뀌어요. 이제 modality는 self-supervised 학습에서 서로 맞춰야 할 정렬 대상이에요. 좋은 표현은 정답 label이 아니라 modality 간, view 간 일관성에서 나온다고 보는 관점이에요.
흐름을 돌아보며
네 모델을 나란히 놓으면 modality가 맡는 역할이 점점 깊어지는 것이 보여요. VBPR에서 modality는 MF 점수에 더해지는 정적인 side-feature였어요. NGCF와 LightGCN은 modality를 쓰지 않지만, 상호작용을 graph로 풀어 high-order connectivity를 표현에 심는 backbone을 마련했어요. GRCN은 이 backbone 위에서 modality를 이용해 graph를 다듬어요. False-positive edge를 솎아내는 기준이 돼 graph 구조 자체의 품질을 높여요. BM3는 한 발 더 나아가 modality를 self-supervised 학습의 정렬 대상으로 삼았어요. Negative sampling도, auxiliary graph도 없이 modality 간 일관성만으로 표현을 학습해요.