Language Model은 잠을 자야 할까
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces, 2024, arXiv.
- Linear Transformers Are Secretly Fast Weight Programmers, ICML 2021, arXiv.
- Do Language Models Need Sleep? Offline Recurrence for Improved Online Inference, 2026, arXiv.
Transformer의 attention은 모든 과거 token을 KV cache에 저장하고, 필요할 때마다 query-key 유사도로 꺼내 써요. 강력하지만 context가 길어질수록 attention compute는 제곱으로, cache memory는 선형으로 늘어나요. 그래서 과거를 고정 크기 메모리에 압축하는 모델이 오래 연구됐어요.
이 글은 세 논문을 차례로 읽어요. Mamba는 고정 크기 state로 attention에 맞먹는 성능을 냈고, Fast Weight Programmers는 그 state가 사실 “fast weight memory”임을 보였고, Do Language Models Need Sleep? 는 그 memory에 과거를 써넣는 데 더 많은 compute가 필요하다고 주장해요. 세 논문을 관통하는 질문은 하나예요. 고정 크기 weight에 과거를 어떻게 잘 써넣을까요.
Attention은 왜 길어질수록 비싸질까
Attention 식에서 $K_t = [k_1, \dots, k_t]^\top$, $V_t = [v_1, \dots, v_t]^\top$ 가 KV cache예요.
\[o_t = V_t^\top\, \mathrm{softmax}\!\left(\frac{K_t q_t}{\sqrt{d}}\right)\]장점은 분명해요. 과거 어떤 token이든 손실 없이 정확히 가리킬 수 있어요. 단점도 분명해요. $t$번째 token을 만들 때 $t$개의 key와 곱셈을 하니 길이 $T$ 전체로는 $O(T^2)$ 연산이고, cache는 token마다 $k_t, v_t$를 쌓으니 $O(T)$ 메모리예요. context가 길어지면 둘 다 감당하기 어려워요.
대표적인 해결책으로 “과거를 통째로 들고 있지 말고, 크기가 변하지 않는 상태 하나에 요약”하는 방법이 있어요. 그러면 token 하나를 처리하는 비용이 $t$와 무관해지고, 전체가 $O(T)$로 떨어져요. SSM과 linear attention도 비슷한 결이에요. 다만 요약은 본질적으로 손실 압축이라, “무엇을 남기고 무엇을 버릴지”를 잘 정하는 게 관건이 돼요. 세 논문은 이 질문을 서로 다른 각도에서 답해요.
SSM은 어떻게 과거를 상태 하나에 담을까
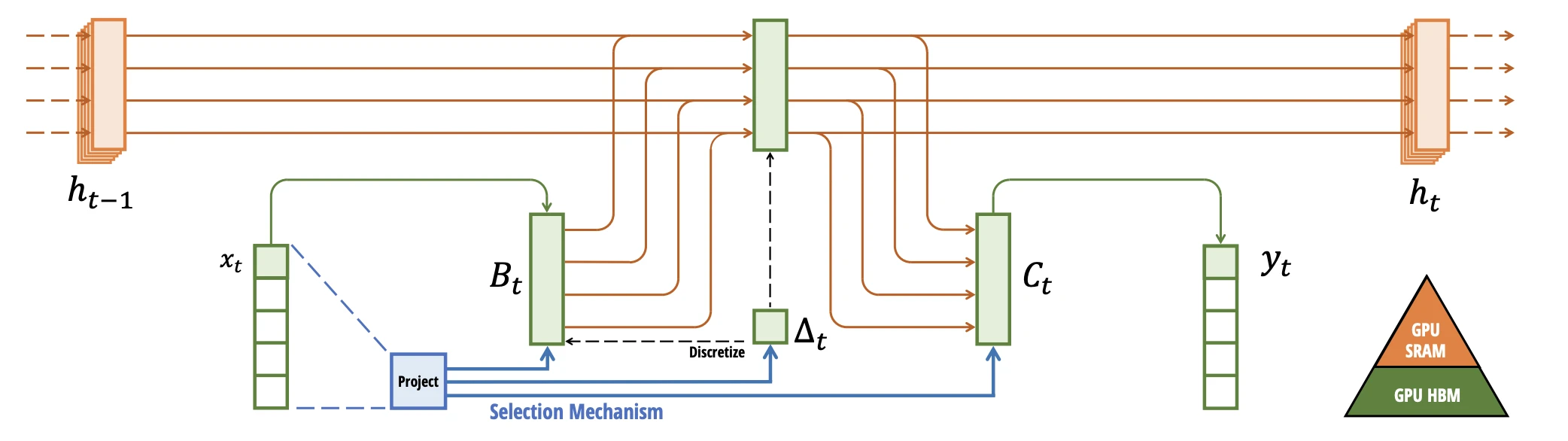
State Space Model(SSM)은 제어공학과 신호처리에서 온 선형 시스템이에요. 입력 신호 $x(t)$를 latent state $h(t)$에 모으고, 그 state에서 출력 $y(t)$를 뽑아요.
\[h'(t) = A\,h(t) + B\,x(t),\qquad y(t) = C\,h(t)\]$A$는 state가 시간에 따라 어떻게 변하는지를, $B$는 입력이 state에 얼마나 들어오는지를, $C$는 state에서 출력을 어떻게 읽을지를 정해요. 그런데 위 식은 연속 시간 $t$에 대한 미분방정식이에요. Token은 띄엄띄엄 들어오니, 이 식을 한 token 간격($\Delta$)만큼 풀어 이산 recurrence로 바꿔요.
\[h_t = \bar{A}\,h_{t-1} + \bar{B}\,x_t,\qquad y_t = C\,h_t\]$\bar{A}, \bar{B}$는 연속식의 $A, B$를 $\Delta$ 간격에 맞게 변환한 값이에요. 변환 공식($\bar{A} = \exp(\Delta A)$)의 유도는 넘어가도 돼요. 지금 중요한 건 결과의 형태예요. 매 step마다 이전 state $h_{t-1}$에 $\bar{A}$를 곱해 과거를 흘려보내고, 새 입력 $x_t$를 $\bar{B}$로 더해 섞어요.
핵심은 $h_t$가 과거 전체를 요약한 고정 크기 벡터라는 점이에요. KV cache처럼 길이에 따라 커지지 않아요. RNN과 식 모양이 같지만, 선형이라는 점 덕에 학습 때는 convolution으로 펼쳐 병렬화할 수 있어요.
이산화를 더 깊이 보고 싶다면, Mamba의 부록(S4 Variants and Derivatives)을 참고해주세요.
단순한 RNN은 왜 긴 의존성에 약했을까
같은 recurrence를 쓰는 평범한 RNN은 long-range dependency에서 고생했어요. $h_t$를 $T$번 거슬러 올라가면 $\bar{A}$가 $T$번 곱해지는데, $\bar{A}$의 eigenvalue가 1보다 작으면 신호가 지수적으로 사라지고(vanishing), 1보다 크면 폭발해요(exploding). 그래서 먼 과거의 정보가 state에 남기 어려웠어요.
S4(Structured State Space)는 이걸 초기화로 풀었어요. $A$를 아무렇게나 두지 않고 HiPPO 행렬로 시작해요. HiPPO는 과거 입력을 직교 다항식(Legendre 기저) 위로 projection해서 압축하도록 설계된 행렬이라, 먼 과거를 안정적으로 기억하면서도 eigenvalue가 폭주하지 않게 잡아 줘요. 즉 “과거를 어떻게 압축할지”에 대한 좋은 출발점을 수학적으로 깔아 둔 셈이에요. 덕분에 SSM은 audio·vision처럼 연속적이고 긴 신호에서 강했어요.
그런데 왜 언어에서는 약했을까
S4 계열의 $A, B, C, \Delta$는 입력과 무관한 상수였어요. 모든 token을 똑같은 규칙으로 받아들인다는 뜻이에요. 연속 신호에서는 괜찮지만, 언어는 달라요. “the”나 “은/는” 같은 token은 흘려보내도 되고, 고유명사나 숫자는 또렷이 기억해야 해요. 입력 내용에 따라 “기억할지 잊을지”를 바꾸는 content-based selection이 필요한데, 상수 파라미터로는 그게 안 됐어요. Mamba 저자들은 이걸 SSM이 언어 같은 정보 밀집 modality에서 attention에 밀리는 핵심 원인으로 짚었어요.
Mamba의 selectivity는 무엇을 바꿨을까
Mamba의 해법은 단순해요. 상수였던 $B, C, \Delta$를 현재 입력 $x_t$의 함수로 만들어요.
\[B_t = s_B(x_t),\quad C_t = s_C(x_t),\quad \Delta_t = \mathrm{softplus}\big(s_\Delta(x_t)\big)\]직관은 $\Delta_t$에 담겨 있어요. $\Delta$는 원래 “얼마나 긴 시간 간격을 한 step으로 볼지”를 정하는 timescale이에요. $\Delta_t$가 커지면 현재 입력을 state에 강하게 새기고 과거의 비중은 줄어들어요. 작아지면 현재 입력을 거의 무시하고 과거 state를 유지해요. 결국 token 내용에 따라 state가 선택적으로 전파하거나 잊게 되는 거예요. 이게 selective state space이고, S4와 갈리는 지점이에요.
대가는 있어요. 파라미터가 입력에 의존하면 시간 불변(LTI) 성질이 깨져서, S4가 쓰던 convolution 펼치기를 못 해요. 매 step의 $\bar{A}_ t, \bar{B}_ t$가 달라지니 하나의 고정 kernel로 묶을 수 없거든요. Mamba는 대신 parallel scan으로 이 문제를 우회해요. Recurrence $h_t = \bar{A}_ t h_ {t-1} + \bar{B}_ t x_ t$ 는 결합법칙이 성립하는 연산이라, 순차적으로 한 step씩 가지 않고 binary tree처럼 묶어 $O(\log T)$ 깊이로 병렬 계산할 수 있어요. 게다가 hardware-aware로 구현해서, state를 GPU의 빠른 SRAM 안에서만 갱신하고 큰 중간 행렬을 느린 HBM에 쓰지 않아요.
결과적으로 Mamba는 sequence 길이에 선형으로 scale하면서 같은 크기 Transformer를 능가하고, 두 배 크기 Transformer에 맞먹었어요. Inference throughput은 약 5배 빨랐어요. 여기까지 보면 SSM은 “과거를 압축한 latent state $h_t$”를 굴리는 모델이에요. 다음 논문은 이 state를 전혀 다른 이름으로 불러요.
Linear attention은 왜 fast weight일까
FWP의 저자는 linearised attention이 1990년대 Schmidhuber의 Fast Weight Programmers(FWP)와 형식적으로 동등하다고 보였어요. 먼저 fast weight라는 개념부터요. 보통의 신경망은 학습이 끝나면 weight가 고정되고, 입력에 따라 바뀌는 건 activation뿐이에요. Fast weight는 여기에 “입력에 따라 즉석에서 변하는 두 번째 weight 집합”을 더하는 발상이에요. 학습으로 고정된 slow net이 token을 보며, 또 다른 net의 fast weight를 그때그때 프로그래밍해요. 그 프로그래밍 명령이 바로 key와 value의 outer product예요.
이 관점이 linear attention에서 어떻게 드러나는지 단계를 밟아 볼게요. 출발점은 앞서 본 attention이에요. $t$번째 출력은 과거 모든 token의 value를, query-key 유사도로 가중평균한 값이에요. $q_t, k_t, v_t$는 그대로 $i$번째 token의 query, key, value고요.
\[o_t = \frac{\sum_{i=1}^{t} \mathrm{sim}(q_t, k_i)\, v_i}{\sum_{i=1}^{t} \mathrm{sim}(q_t, k_i)}\]Softmax attention은 유사도가 $\mathrm{sim}(q_t, k_i) = \exp(q_t^\top k_i)$ 예요. 문제는 이 $\exp$가 $q_t$와 $k_i$를 한 덩어리로 묶어 버려서, $k_i$와 $v_i$만 미리 정리해 둘 수 없다는 점이에요. 매 token마다 과거 전체를 다시 훑어야 하는 이유예요.
Linear attention은 이 유사도를 feature map $\phi$의 내적으로 바꿔요. 즉 $\mathrm{sim}(q_t, k_i) = \phi(q_t)^\top \phi(k_i)$ 로 두는 거예요. 그러면 분자가 이렇게 풀려요.
\[\sum_{i=1}^{t} \big(\phi(q_t)^\top \phi(k_i)\big)\, v_i = \Big( \sum_{i=1}^{t} v_i\, \phi(k_i)^\top \Big)\phi(q_t)\]핵심은 $\phi(q_t)$를 합 밖으로 빼낼 수 있다는 점이에요. $q_t$와 무관한 부분, 곧 $\sum_i v_i \phi(k_i)^\top$ 를 따로 모아 둘 수 있게 됐어요. 이 누적합을 $S_t$라 부르면, token이 하나 들어올 때마다 $v_t \phi(k_t)^\top$ 한 장을 더하는 recurrence가 돼요. (분모도 같은 방식으로 정리되는데, 보통 normalization으로 처리하니 분자만 따라가도 흐름은 같아요.)
\[S_t = S_{t-1} + v_t\,\phi(k_t)^\top,\qquad y_t = S_t\,\phi(q_t)\]$S_t$는 outer product $v_t \phi(k_t)^\top$ 를 계속 더한 행렬이에요. 새 token이 올 때마다 “이 key에는 이 value”라는 연관을 한 장씩 적어 두는 메모리이고, 크기가 token 수에 따라 커지지 않아요. 읽을 때는 query를 곱해 관련 value를 꺼내요. SSM의 $h_t$가 벡터 상태였다면, 여기서는 행렬 상태라는 차이만 있을 뿐 역할이 같아요. 그래서 “linear attention = fast weight memory”라는 등식이 성립해요. 과거를 KV cache가 아니라 고정 크기 weight 행렬에 적어 둔 것이죠.
단순 누적은 왜 빨리 포화될까
순수 누적 방식에는 약점이 있어요. 비슷한 key가 계속 들어오면 그 outer product들이 같은 방향으로 쌓여 서로 간섭해요. 나중에 query로 읽으면 어느 value가 진짜인지 흐려져요. 메모리 용량이 한정돼 있으니 금세 포화되는 거예요. 저자들은 이걸 capacity 한계로 진단하고, 단순 누적을 delta rule로 바꿔요.
Delta rule의 발상은 “통째로 더하지 말고, 차이만 고치자”예요. 새 token이 오면 먼저 그 key로 지금 저장된 value를 읽어요. 그다음 새 value와의 차이만큼만 갱신해요.
\[\bar{v}_t = S_{t-1}\,\phi(k_t),\qquad S_t = S_{t-1} + \beta_t\,\big(v_t - \bar{v}_t\big)\,\phi(k_t)^\top\]$\bar{v}_t$는 현재 메모리가 이 key에 대해 내놓는 값이고, $v_t - \bar{v}_t$ 는 오차예요. $\beta_t$는 그 오차를 얼마나 반영할지 정하는 동적 쓰기 강도, 곧 학습되는 learning rate예요. 이렇게 하면 같은 key의 value를 새 값으로 덮어쓸 수 있어서, 같은 메모리를 훨씬 효율적으로 써요. 논문은 여기에 simplicity와 effectiveness를 절충한 새 kernel($\phi$)도 함께 제안했어요.
정리하면 FWP는 두 가지 관점을 줬어요. 첫째, 고정 크기 state는 사실 outer product로 갱신되는 fast weight memory예요. 둘째, 그 memory에 잘 쓰려면 단순 누적보다 delta rule 같은 local update가 낫다는 거예요. 실제로 Mamba2와 Gated Delta Network는 이 둘을 합친 형태로 state를 갱신해요.
\[S_t = \alpha_t\,S_{t-1} + \beta_t\,v_t k_t^\top\]$\alpha_t$는 과거를 얼마나 잊을지 정하는 forget gate, $\beta_t$는 새 입력을 얼마나 쓸지 정하는 input gate이고 둘 다 입력에서 계산돼요. Mamba의 selectivity와 FWP의 outer-product write가 한 식에서 만나요. 세 번째 논문은 바로 이 $S_t$를 다뤄요.
용량이 충분한데 왜 추론이 실패할까
Do Language Models Need Sleep? 의 출발점은 SSM-attention hybrid model이에요. 최근 frontier model은 attention block과 SSM block을 번갈아 쌓아요. Attention은 최근 token을 정밀하게 읽고, SSM의 fast weight는 context window 밖으로 밀려난 정보를 압축해 들고 있어요. 두 메모리가 역할을 나눠 갖는 구조예요.
저자들이 던지는 질문은 이거예요. “이 hybrid가 정말로 이미 사라진 context를 깊게 추론할 수 있을까”. 이를 보려고 통제된 실험을 설계해요. Rule 110이라는 1차원 binary cellular automaton을 써요.

길이 24짜리 binary string 네 개를 입력하고, 각 state를 $t$번 전개한 뒤 첫 bit를 맞히게 해요. Rule 110은 $t$단계 예측이 일반적으로 P-complete라 지름길이 없는, 순차 계산을 강제하는 문제예요. 여기서 $t$가 reasoning depth를 조절해요. $t = 0$이면 단순 검색이고, $t$가 커질수록 더 깊은 시뮬레이션이 필요해요.
여기에 24 token마다 KV cache를 완전히 비우는 hard-eviction 제약을 걸어요. 그러면 한 sequence가 두 단계로 쪼개져요. 과거를 fast weight $S_t$에 적어 넣는 consolidation phase와, 그 weight만으로 답하는 prediction phase예요. 그리고 prediction은 looping이나 chain-of-thought 없이 single forward pass로만 하게 해요. 답에 필요한 모든 정보가 prediction 전에 이미 fast weight로 옮겨져 있어야 한다는 뜻이에요.
이 설정에서 평범한 Transformer는 cache가 지워졌으니 무작위 추측밖에 못 해요. SSM hybrid는 과거를 fast weight에 담을 수 있어 더 잘해요. 그런데 sequence 길이 $T$를 고정한 채 $t$만 키우자, 4-layer GDN-attention hybrid의 정확도가 빠르게 무너졌어요. 저장할 정보량은 그대로인데도요.
핵심 진단은 이거예요. 병목은 메모리 capacity가 아니라, evicted context를 쓸 만한 internal state로 바꾸는 데 필요한 computation이에요. Fast weight 자리는 충분한데, 고정 깊이 모델은 한 번의 forward pass로 $t$단계 시뮬레이션을 끝낼 수 없어요. 저장 공간과 계산량은 별개의 문제라는 거예요. 참고로 여기서 “실패”는 고정된 학습 token 예산 안에서의 이야기예요. 무한한 데이터와 시간이 있으면 배울 수도 있지만, 추론 데이터가 희소한 현실에서는 이 예산 제약이 중요해요.
Sleep은 evicted context를 어떻게 weight로 옮길까
해법은 동물의 수면에서 빌려 와요. 동물은 잠자는 동안 hippocampus의 단기 기억을 반복 재생(replay)하며 cortex의 synaptic weight로 옮겨요. 외부 자극에 반응하지 못하는 비용을 치르면서까지 잠을 잔다는 건, 그 consolidation이 그만한 값어치를 한다는 뜻이에요. 저자들은 같은 구조를 모델에 넣어요.
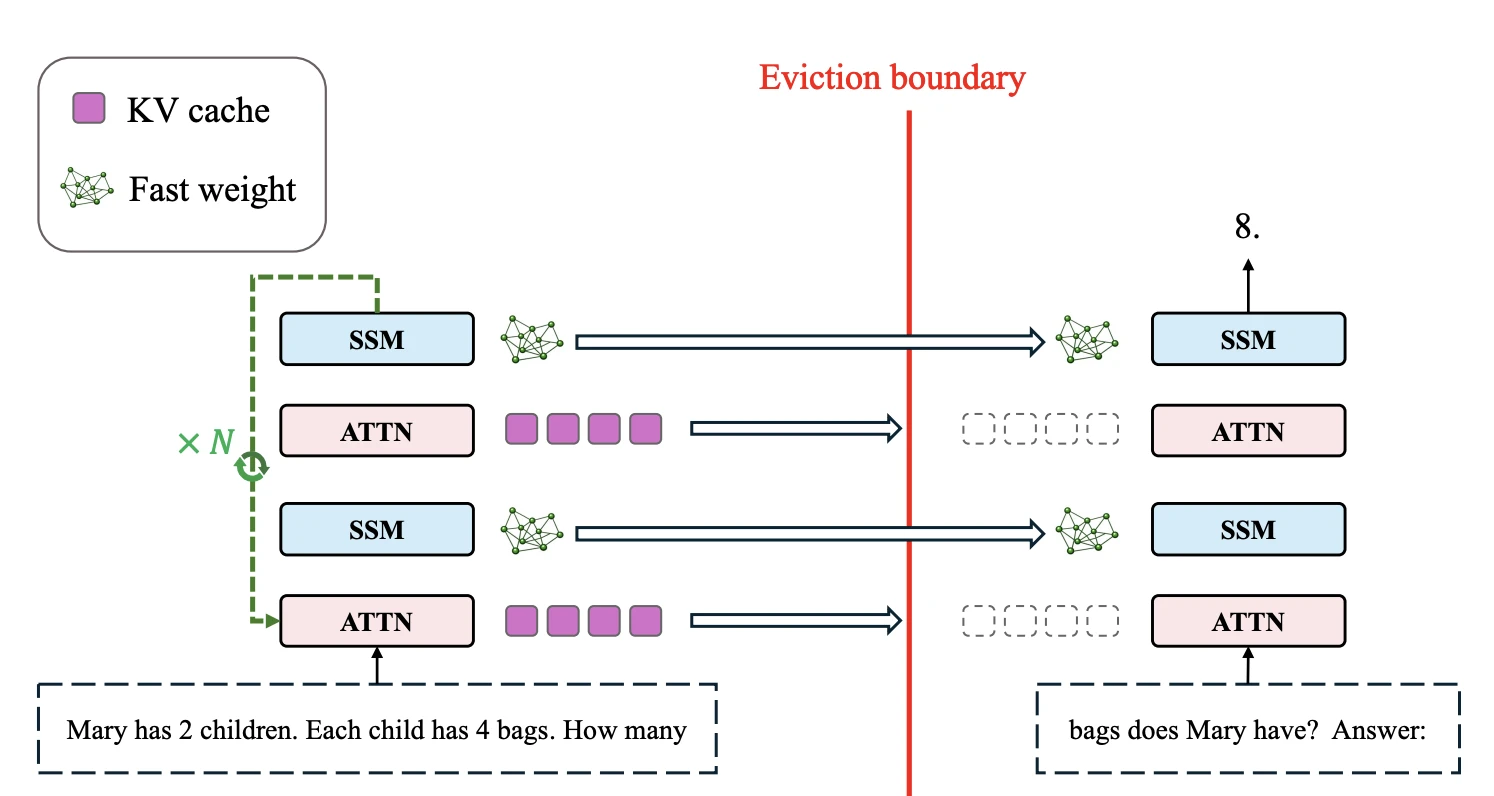
Context window가 가득 차 KV cache를 비우기 직전에, 모델이 누적된 context 위로 $N$번 recurrent pass를 돌며 SSM block의 fast weight를 반복 갱신해요. 이 구간이 sleep이에요. 동물의 잠처럼, 이 동안 모델은 새 입력 token을 받지 않아요.
\[\mathrm{Embed} \rightarrow \Big( B^{\text{attn}}_0 \rightarrow B^{\text{ssm}}_1 \rightarrow \cdots \rightarrow B^{\text{attn}}_{D-1} \Big)^{\times N} \rightarrow \mathrm{OutProj}\]$N = 1$이면 평범한 hybrid model로 돌아와요. $N > 1$이면 같은 block을 여러 번 통과시키며 $S_t$를 다듬어요. Sleep이 끝나면 cache를 비우고 다음 token으로 넘어가요. 답을 낼 때는 다듬어 둔 weight와 현재 context만으로 single forward pass를 해요.
학습은 이 전체 과정을 end-to-end로 backprop해서, sleep 이후의 prediction error를 줄이도록 최적화해요. 한 가지 미묘한 차이가 있어요. 기존 depth-recurrent model은 반복적으로 다듬어진 feature vector를 따라 gradient가 흘렀어요. 반면 여기서는 sleep이 끝나면 feature는 버리고 fast weight만 남기므로, gradient가 다듬어진 weight를 따라 흘러요. 무엇을 다음 단계로 넘기느냐가 다른 거예요.
핵심 통찰은 recurrence를 prediction이 아니라 memory consolidation에 쓴다는 점이에요. Context를 쓸 만한 weight로 바꾸는 일 자체가 비자명한 computation이고, 한 번의 pass로 끝낼 이유가 없어요. Gradient descent가 반복으로 좋아지듯, sleep을 길게 하면 모델이 context를 변환할 단계를 더 많이 얻어요. 이게 기존 looped model과 갈리는 지점이에요. 보통의 looped model은 답할 때마다 loop를 돌아 prediction이 느려지는데, sleep은 그 계산을 미리 weight 형성에 써 두므로 prediction은 여전히 single-pass라 inference latency를 지켜요. 추가 비용을 추론 시점에서 수면 시점으로 옮긴 셈이에요.
실험은 무엇을 보여줬을까
저자들은 난이도를 올려 가며 검증해요. 모든 결과의 메시지는 같아요. Sleep을 길게 할수록(즉 $N$이 클수록) 깊은 추론에서 이득이 커져요.
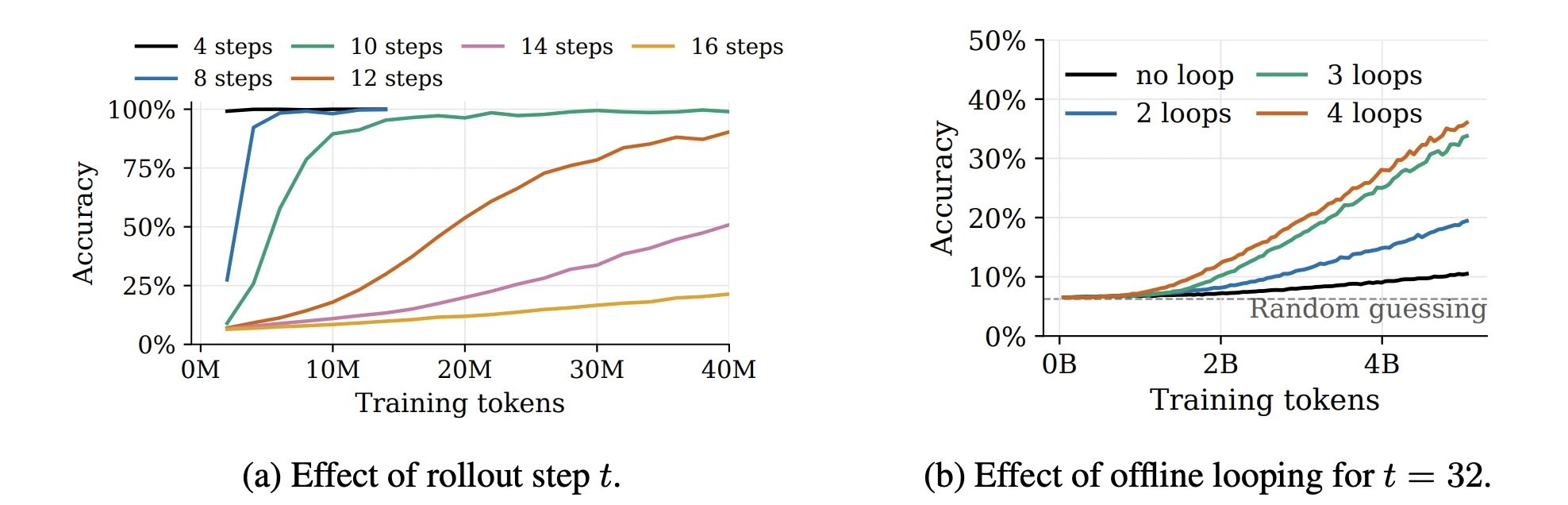
Rule 110 cellular automaton에서, $t = 32$로 어렵게 두면 no-loop 모델은 5B token을 봐도 무작위 수준인 10% 부근에 머물렀어요. Loop 두 번은 약 20%, 세·네 번은 30%를 넘겼어요. Context 길이와 eviction 규칙이 고정됐으니, 향상은 오롯이 sleep 동안의 추가 computation에서 나와요.
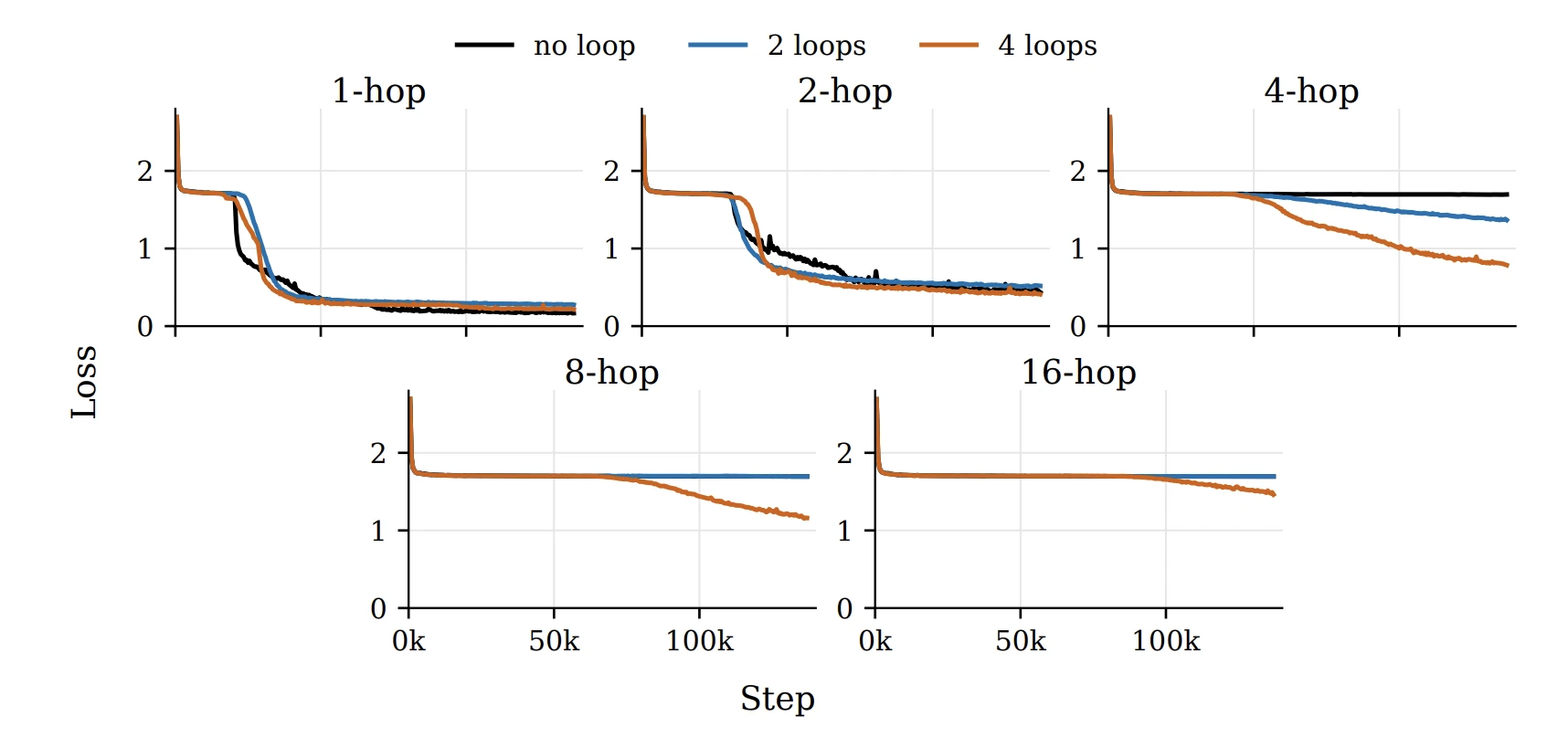
Depo는 섞인 directed cycle에서 $k$-hop 뒤 도착 노드를 묻는 multi-hop retrieval이에요. Cycle이 네 cache window에 쪼개져 들어가고, query가 올 때는 이미 evicted돼요. 게다가 시작 노드와 $k$가 매번 무작위라, 모델은 어떤 query가 올지 모른 채 그래프 전체를 query-무관한 형태로 정리해 둬야 해요. Cellular automaton보다 어려운 이유예요. Loop를 늘리면 4-hop 이상의 어려운 query에서 학습 속도가 빨라졌고, 학습 예산 안에서 16-hop은 4-loop 모델만 진전을 보였어요.
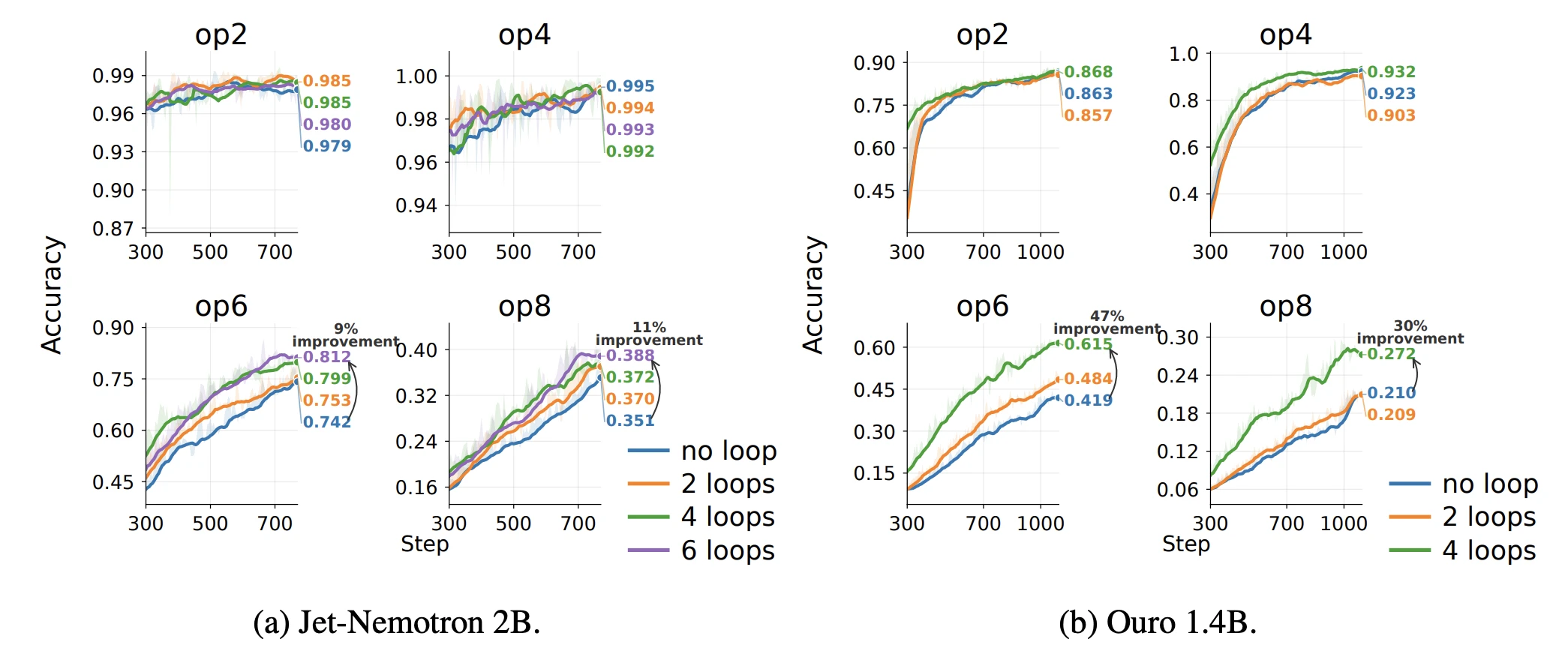
GSM-Infinite는 distractor token이 섞인 실제 math reasoning benchmark예요. 단순 retrieval로는 풀리지 않아서, 긴 context 처리와 multi-step 추론을 동시에 요구해요. 사전학습된 Jet-Nemotron 2B와 Ouro 1.4B를 fine-tune했어요. 두 가지 방식을 다 시험했는데, hybrid model에 sleep을 붙이거나(Jet-Nemotron), looped model에 SSM 메모리 층을 더하는(Ouro) 식이에요. 쉬운 2·4-operation 문제는 loop 수와 무관하게 포화에 가까웠지만, 어려운 6·8-operation에서 격차가 벌어졌어요. Ouro는 6-operation 정확도가 4-loop로 0.419에서 0.615로 올랐어요. Context window보다 sequence가 몇 배 긴 sliding-window 설정에서는 2-operation 조차 no-loop가 약했는데, loop가 0.596에서 0.905로 끌어올렸어요. 이때는 sleep이 추론뿐 아니라 관련 context를 추려 압축하는 데도 도움을 준 거예요.
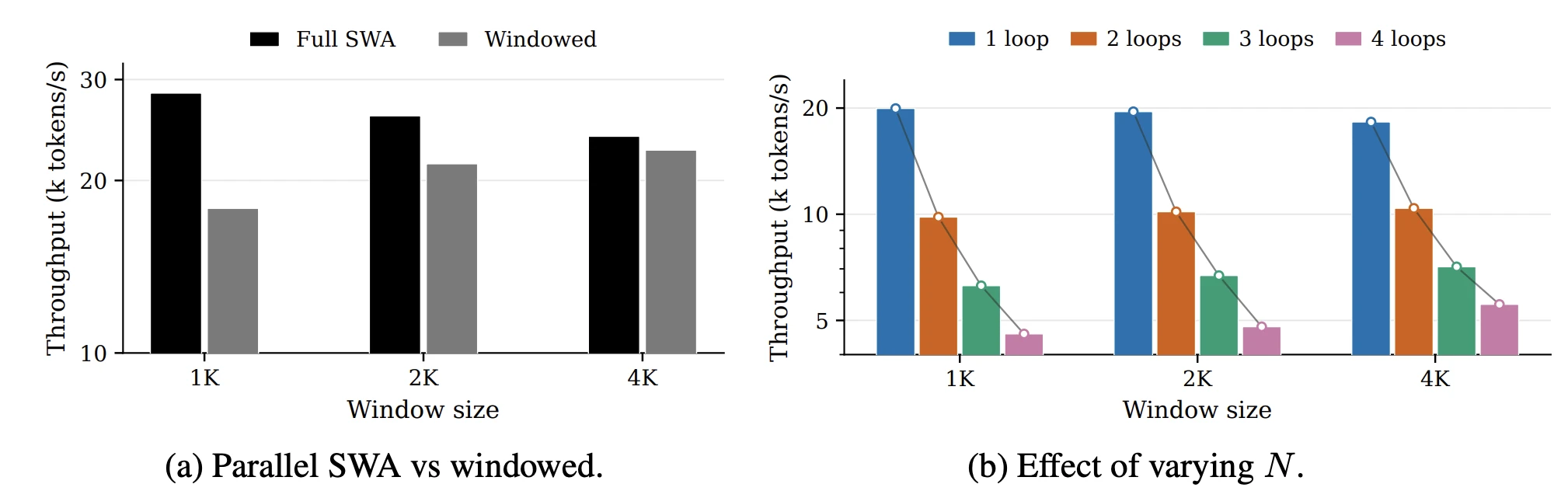
비용도 확인할 수 있어요. Window를 가로지르는 recurrence는 sequence 축 병렬화를 막아요. Window $j+1$을 처리하려면 $j$의 sleep을 끝내 fast weight를 넘겨받아야 하니까요. 다만 window $L$이 충분히 크면 한 번의 pass에서 처리할 token이 많아져 GPU가 어차피 포화되고, 그 상태에서는 sleep의 반복 비용이 전체 시간 대비 상대적으로 작아져요. 그래서 throughput 저하가 눈에 띄지 않는 범위가 생겨요. 대신 깊이 방향 비용은 $N$에 거의 선형으로 늘어요. 추론 지연을 sleep으로 옮긴 대가를 학습 시간에서 치르는 구조예요.
세 논문을 정리하면
세 논문은 고정 크기 weight memory를 다른 각도로 봐요.
Fast Weight Programmers는 렌즈를 줬어요. Linear attention의 state는 outer product로 갱신되는 fast weight이고, 단순 누적 대신 delta rule로 쓰면 덮어쓰기와 정정이 가능해요. Mamba는 그 memory를 실용적으로 만들었어요. $B, C, \Delta$를 입력 의존으로 바꾸는 selectivity로 고정 크기 state가 attention에 맞먹게 했고, parallel scan으로 선형 시간에 돌렸어요. 두 갈래는 Mamba2와 Gated Delta Network의 gated outer-product update에서 한 식으로 만나요.
Do Language Models Need Sleep? 는 이 흐름에 빠진 축을 채워요. Memory가 충분히 커도, context를 추론 가능한 state로 바꾸는 데는 computation이 필요해요. Capacity와 computation은 다른 문제예요. 그래서 답을 내기 전, 사라질 context 위로 weight를 반복해 다듬는 sleep을 둬요. Write를 무엇으로 할지(FWP)와 state를 어떻게 굴릴지(Mamba)에 이어, 얼마나 오래 써넣을지(Sleep)를 물은 셈이에요.