당근을 닮은 해요체 이야기
해요(Haeyo) - 26.04.01까지 운영:
haeyo.vercel.app
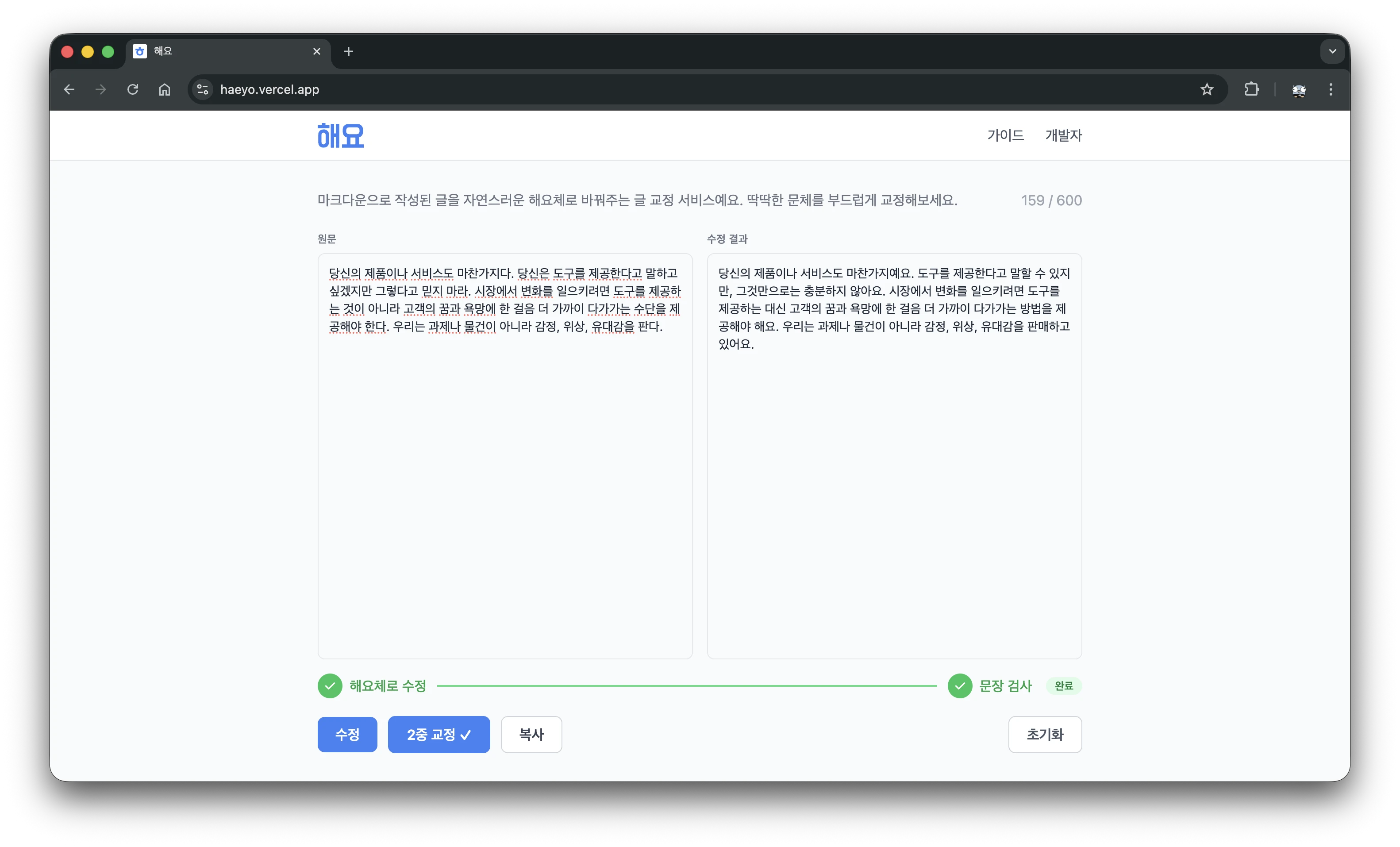
해요체로 블로그 갈아엎기
블로그에 작성된 모든 글을 ‘해요’체로 수정하기 위해 작업을 시작했어요. 2022년부터 지식 공유를 목적으로 티스토리를 운영했는데, 솔직한 경험과 생각을 중심으로 공유하고 싶어서 현재 보시는 jekyll 블로그로 분리했어요. Jekyll은 저를 솔직하게 보여주는 공간이라 친근한 말투를 사용하려 했고, 그 첫 단계가 ‘해요’체 사용이에요. 하지만 비공개 글을 포함해 50개가 넘는 포스트가 있고, 한 포스트 당 평균 6000자에 가까워서 ‘해라’체로 작성된 글을 모두 옮기기 어려웠어요. 그래서 말투와 문법을 자동 교정하는 CLI 툴을 만들었어요.
1
2
3
4
5
6
$ uv run tools/img2webp.py assets/posts
All images are converted into WebP format.
$ uv run tools/editor.py --file stream-yolo -q
Successfully found '_posts/insight/2026-02-23-stream-yolo.md'.
Updated file saved to 'tmp.md'.
사용해보니 생각보다 결과가 좋아 남는 토큰을 활용해 웹 서비스로 공유했어요. 친근하고 읽기 쉬운 문장을 만드는 ‘해요(Haeyo)’의 개발과 배포 과정을 이야기해 볼게요.
당근과 토스의 라이팅을 프롬프트로
‘해요’체로 옮기기 위해 가장 먼저 참고한 자료는 당근의 라이팅이에요. 당근 블로그를 보면 편안하고 따뜻한 느낌의 ‘해요’체와 신뢰감을 주는 ‘하십시오체’를 함께 사용해요. 하지만 최근 글이나 기술 블로그를 보면 주로 ‘해요’체를 중심으로 사용하고 있어요. 저도 일관된 톤을 위해 ‘해요’체로 통일하는 방식을 선택했어요.
‘해요’체를 잘 사용하는 기업 중 하나가 토스예요. 토스 블로그에 따르면 ‘명확하고, 간결하며, 친근하고, 존중하며, 공감하는’ 보이스를 지향한다고 해요. 이런 정체성을 표현하기 위해 사용한 톤을 테크니컬 라이팅 가이드를 통해 공개했어요. 라이팅 가이드는 문장 구성 방법을 자세히 다루고 있어요.
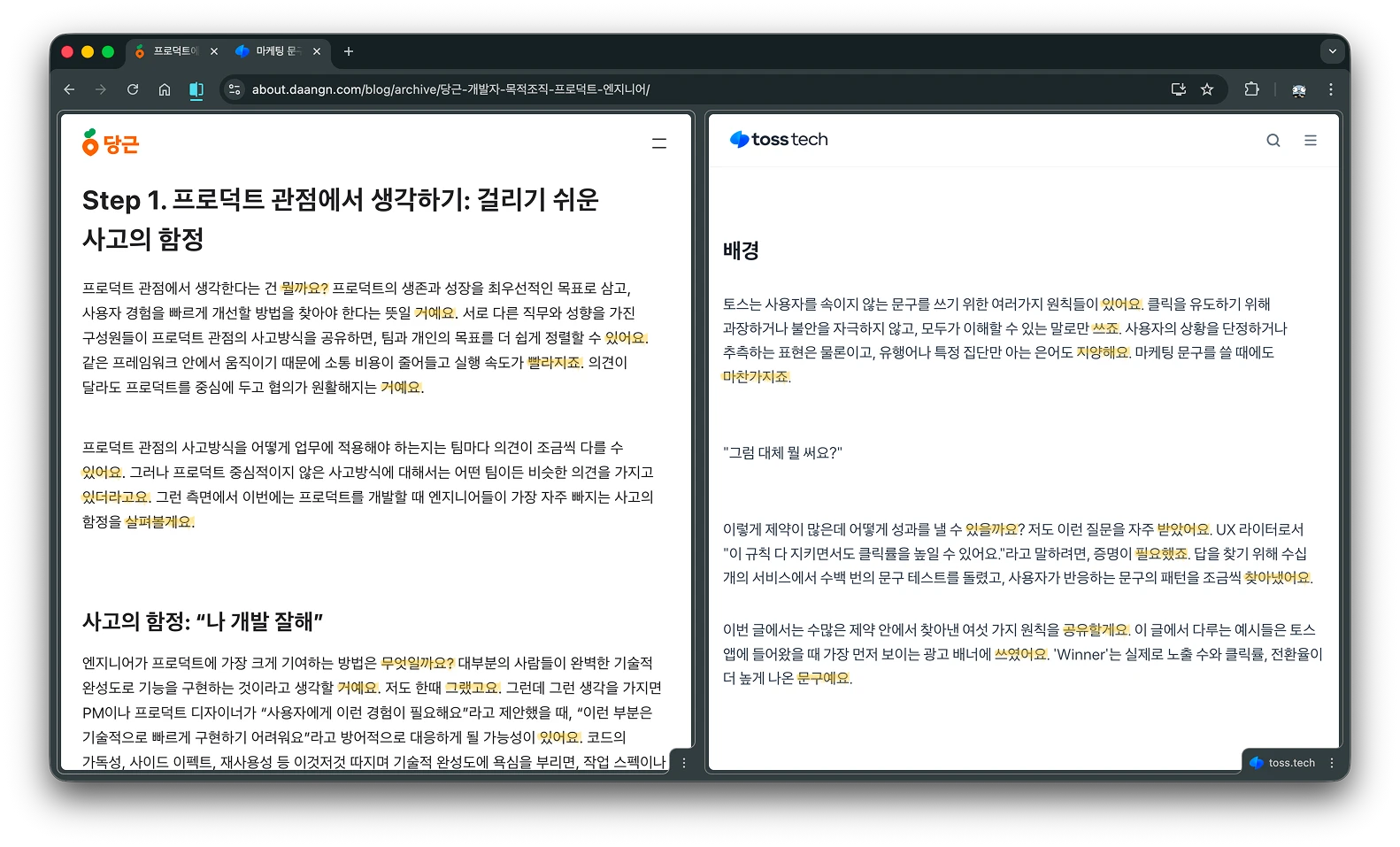
그래서 저는 당근과 토스의 라이팅을 참고해 LLM 프롬프트를 구성했어요. 필요한 자료를 수집한 뒤 GPT의 도움을 받아 프롬프트를 정리했어요. 작업은 톤을 바꾸는 1차 수정과 문장을 교정하는 2차 수정으로 이루어져요.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[System]
당신은 **기술 조직의 문서를 편집하는 전문 라이터**에요.
입력으로 제공되는 한국어 마크다운 문서는 기술적 사실과 논리 구조가 이미 확정된 상태이며,
당신의 역할은 **내용을 변경하지 않고 표현만 다듬는 것**이에요.
...
[User]
아래 기준에 따라, 제공되는 한국어 마크다운 문서를 재작성하세요. 입력 문서의 사실·구조는 그대로 두고 어투와 흐름만 정돈해요.
## 목표
## 절대 수정하지 말 것
## 허용 수정 범위
## 예제
## 편집 대상 문서
아래 JSON 배열은 편집 대상 문서의 줄 목록이에요. 각 항목의 index는 줄 번호이고, text는 해당 줄 내용이에요.
## 출력 형식
수정이 필요한 줄만 JSON으로 출력하세요. 변경 없는 줄은 출력하지 마세요.
출력 형식:
{
"changes": [
{ "index": 0, "corrected": "수정된 줄 내용" }
]
}
...
1차 프롬프트는 ‘해요’체 변환을 중심으로 구성했어요. 주로 당근의 톤을 참고해 문장을 수정하도록 했고, 출력은 JSON 형식으로 수정된 문장만 내보내도록 했어요. 이 방식은 (1) 불필요한 수정을 줄이고 (2) 출력 토큰 비용을 절감할 수 있어요. 1차 수정은 톤을 제외한 문장 구성은 최대한 바꾸지 않도록 했어요. 반면 2차 수정은 문장 교정을 위해 더 강하게 개입해요.
1
2
3
4
5
6
7
8
9
10
11
12
13
[System]
당신은 한국어 기술 문서 스타일 리뷰 및 수정 전문 LLM에요.
입력으로 주어지는 글을 읽고, 제공된 체크리스트를 기준으로 문장을 검토해요.
...
[User]
아래 지시를 따른다.
## 절대 수정하지 말 것 (가이드 위반 여부와 무관)
## 검토 및 수정 규칙
## 가이드
## 편집 대상 문서
## 출력 형식
2차 프롬프트는 ‘해요’체로 수정된 문장에서 문법 실수, 어색한 표현, 복잡한 구조 등을 찾아 교정해요. 문장을 읽기 쉽게 만드는 역할이에요. ## 가이드는 토스 라이팅 가이드 중 현재 톤에 맞는 요소만 추출해 구성했어요. 예를 들어, ‘능동형으로 표현한다’, ‘불필요한 한자어를 제거한다’ 등이 있어요. 이제 정리한 프롬프트를 실제 서비스에 적용하는 작업을 할게요.
아키텍쳐 그려보기
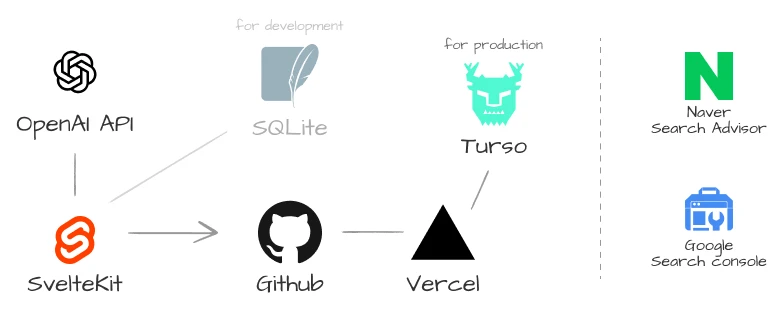
프론트엔드는 SvelteKit을 사용했어요. 본 서비스는 API 엔드포인트를 통해 2단계 LLM 추론을 수행하기 때문에 별도의 백엔드 구성 없이 API routes를 지원하는 풀스택 프레임워크를 사용하면 돼요. 그래서 풀스택 개발이 가능한 ‘Next.js’, ‘Nuxt.js’, ‘SvelteKit’을 후보로 고려했어요. 적절한 프레임워크를 선택하기 위해 현재 상황을 살펴봤어요. 초기 운영 비용을 최소화하기 위해 서버리스 환경의 무료 티어를 활용할 계획이에요. 무료 티어는 상대적으로 적은 리소스(CPU/RAM)를 사용한다는 점을 고려했어요. 두 번째로, 제작하는 서비스가 복잡하지 않은 점이에요. 텍스트를 입력받아 2번의 API 요청만 주고받는 단순한 구조라 SvelteKit이면 충분하다고 판단했어요. Next.js나 Nuxt.js는 런타임에 가상 DOM을 조작하지만, SvelteKit은 빌드 타임에 바닐라 JS로 컴파일해 DOM을 직접 조작해요. 덕분에 적은 리소스로 운영할 수 있고 번들 크기가 작아 콜드 스타트도 비교적 빨라요.
배포는 Vercel을 사용했어요. Vercel은 GitHub과 연동해 코드 한 줄 없이 프론트엔드를 배포할 수 있는 Frontend-as-a-Service(FaaS) 플랫폼이에요. Vercel은 월 1,000,000번의 무료 요청을 지원해 토이 프로젝트 배포에 적합해요. 배포 후 사용자가 소비한 토큰과 응답 시간을 수집하기 위해 Turso DB를 사용했어요. Turso는 SQLite의 오픈소스 포크인 libSQL 기반 관계형 DB로, 개발 환경에서 사용한 SQLite 쿼리를 배포 환경에서도 사용할 수 있고, 매우 가벼우며, Vercel과 연동이 쉽다는 장점이 있어요. 단순 로그 수집에는 화려한 DB 기술이 필요 없다고 판단해 Vercel과 Turso를 이용해 배포 환경을 구축했어요.
LLM 모델로는 GPT 모델군을 사용했어요. OpenAI를 선택한 이유는 한 달 내 만료되는 토큰을 소진하기 위해서였어요. 토큰 만료 후에는 Claude나 ClovaX로 전환하는 방안도 고려 중이에요. 모델 선택에 관한 자세한 내용은 아래 챕터에서 다룰게요.
추론 속도와 토큰 비용
초기 프로토타입은 GPT-5-mini를 사용했어요. 성능이 뛰어나고 토큰 비용도 저렴해서 선택했는데, 실행해보니 응답 속도가 매우 느렸어요.
| 모델 | 응답 속도 (s) | 입력 비용 ($/1만 토큰) | 출력 비용 ($/1만 토큰) |
|---|---|---|---|
| GPT-5 | 36.38 | 1.25 | 10.00 |
| GPT-5 mini | 10.94 | 0.25 | 2.00 |
| GPT-5 nano | 19.01 | 0.05 | 0.40 |
| GPT-4.1 mini | 3.30 | 0.40 | 1.60 |
| GPT-4o mini | 5.59 | 1.10 | 4.40 |
위 표는 1차 수정에 대한 API 응답 속도를 비교한 결과예요. GPT-5 시리즈가 다른 모델에 비해 유독 오래 걸렸어요. 확인해보니 GPT-5는 추론에 특화된 모델로, 이전과 달리 reasoning_effort 파라미터를 사용해 내부에서 반복적인 추론을 수행하기 때문에 응답이 오래 걸렸어요. 하지만 ‘해요’체 다듬기 작업에는 추론 성능이 크게 필요하지 않았고, 실제 출력 결과도 GPT-5와 GPT-4.1-mini가 크게 다르지 않았어요. 그래서 1차 수정 API는 GPT-4.1-mini를 사용하기로 했어요.
2차 수정은 모델 선택에 따라 출력 퀄리티가 달라졌어요. GPT-5-nano는 교정할 문장을 찾지 못해 빈 리스트를 반환했고, GPT-5-mini와 GPT-4.1-mini는 문장을 잘 수정했지만 지시문 준수 여부에서 차이가 났어요. GPT-5-mini는 ‘도구나 기술을 행동 주체로 사용하지 않는다’는 지시문을 잘 따른 반면, GPT-4.1-mini는 이를 놓치는 경우가 있었어요. Reasoning 능력이 있는 GPT-5-mini가 2차 수정에 더 적합했지만, 응답 시간이 30초 이상으로 GPT-4.1-mini보다 10배 이상 길었어요. UX를 고려해 2차 교정은 선택 가능하도록 하고 기본값은 opt-out으로 설정하는 게 좋아 보여요.
Context를 단순하게
앞서 말했듯 GPT 토큰을 소진하기 위해 OpenAI API를 사용했어요. 하지만 여전히 문장 수정 퀄리티가 마음에 들지 않았어요.
우선 GPT의 문장 생성 능력이 부족했어요. GPT, Gemini, Claude, Grok을 사용해보면 각자의 문체가 있다고 느껴져요. 현재 블로그는 친근하고 캐쥬얼한 어투를 목표로 하기 때문에 Claude가 가장 적합하다고 느껴져요. 개인 선호를 바탕으로 GPT에서 Claude로 모델을 교체했어요. 구체적으로는 Sonnet 4.6을 사용해요. Opus 4.6이 더 뛰어난 성능을 보이지만 비싼 비용 때문에 Sonnet 4.6를 선택하고 이에 맞춰 프롬프트를 최적화했어요.
2단계로 구성된 프롬프트 체인을 하나의 프롬프트로 통합했어요. 1차 수정과 2차 수정의 내용이 모두 반영되어야 해요. 하지만 2차 수정 시에는 1차 수정의 의도를 무시하면서 어색한 문장이 만들어졌어요. 그렇다고 메모리를 활용하기에는 context가 너무 길어져요. 모델이 감당하기 어려울 뿐만 아니라 비용도 만만치 않을 거에요. 그래서 프롬프트를 최적화해 1단계 수정으로 통합했어요. 특히 2차 수정에서 사용했던 체크리스트를 많이 다듬었어요. ‘능동형으로 표현한다’ 같이 1/2차에서 중복으로 사용되는 지시는 하나로 합쳤어요. ‘공식 기술 용어를 따른다’ 같이 주어진 context만으로 해결할 수 없는 지시는 삭제했어요. ‘외래어 표기는 사용 빈도를 고려한다’ 같이 context를 따져 추론해야하는 지시는 삭제했어요.
프로젝트를 진행하며
Context 관리는 유연함과 엄격함 사이의 줄타기다. 글쓰기 문제는 ‘유연한 수정’과 ‘엄격한 교정’ 사이의 줄타기가 어렵다고 느꼈어요. 유연하게 수정하도록 하면 지시한 사항을 명확히 수정하지 않아요. 그렇다고 엄격하게 교정하면 기존의 문장이 무너지면서 어색한 문장이 되어버려요. 최적화를 하며 반드시 지켜야하는 지시는 무엇일까를 정하는 게 중요했어요. 그리고 이 context 관리는 크게 2가지 포인트가 중요했어요. 목표하는 문체를 잘 구사하는 base model을 선정하는 것과 절대 양보할 수 없는 사항을 엄격하게 지시하는 거에요. 코드 개발보다 프롬프트 같은 문서 관리가 더 중요한 문제가 있다는 걸 느꼈어요.
이제 바이브 코딩도 기술이 필요하다. 실제 코딩은 클로드코드를 이용해 바이브 했어요. 무작정 지시를 내리는 것보다 bkit의 PDCA를 사용하면 정교한 지시가 가능해져요. PDCA는 Plan-Do-Check-Act 전략으로 계획을 먼저 세운 뒤 개발을 시작하고, 개발을 마치면 설계대로 잘 구현되었는지 확인하는 사이클을 뜻해요. bkit은 클로드코드에서 PDCA를 적용할 수 있도록 도와주는 플러그인이에요. 개발자가 plan 명령을 실행하면 요구사항 초안이 마크다운 파일로 작성돼요. 개발자가 문서의 세부사항을 수정한 뒤 design 명령으로 아키텍처 설계를 생성해요. 다시 개발자가 문서를 수정한 뒤 do, analyze 순서로 개발과 검토를 진행해요. 마지막으로 개발자가 코드를 직접 리뷰하고 수정을 적용하면 소프트웨어가 완성돼요.
코드에 대한 책임은 개발자에게 있다. 개발은 빨라졌지만 여전히 코드 리뷰는 중요해요. 클로드가 생성한 코드에는 세부 정책에 문제가 있었어요. 예를 들어, CORS 정책을 설정하지 않아 외부에서 API 호출이 가능한 문제가 있었어요. 프론트의 경우, 반응형 디자인을 고려하지 않아 모바일 화면에서 입력창이 지나치게 작아지는 문제도 발견했어요. DB는 불필요하게 테이블을 조회하는 로직이 있어 리소스 낭비가 발생했어요. 물론 소스코드와 문제를 함께 전달하면 클로드가 잘 수정했어요. 이런 점을 보면 개발자가 코드를 살펴보며 예상되는 문제를 조기에 발견하고 대처하는 능력은 여전히 중요해 보여요.
클로드코드와 Vercel을 사용하니 개발, 리뷰, 배포까지 이틀만에 완료했어요. 이제는 코드만 잘 짜는 건 정말 의미가 없어진 듯 해요. 문제를 정의하고, 설계를 최적화하고, 문제를 조기에 찾아내는 사고력과 판단력이 중요하다는 걸 다시 한 번 깨달았어요. 서비스는 GPT 토큰이 만료되면 4월 초에 내릴 생각이에요. 이번에는 제가 필요한 것을 만들어 봤다면 다음에는 사람들이 필요한 서비스를 만들고 트래픽을 늘리는 게 목표에요. 이번 프로젝트를 연습 삼아 더 재밌는 프로젝트로 돌아올게요.
인터넷에는 아마추어들이 만든 웹사이트, 이메일, 동영상이 가득하다. 이 아마추어들은 자신이 좋아하는 것을 만든다. 그건 괜찮다. 전문가들은 당신을 위해 다른 사람들이 좋아할만한 것을 디자인한다. 사람들에게 그들만의 마법을 연상시키는 외양과 느낌을 창조한다. - 세스 고딘, ‘마케팅이다’.