그룹을 이용한 개인화된 추천 학습
- Self-Attentive Sequential Recommendation, ICDM 2018, arXiv.
- Efficient and Effective Adaptation of Multimodal Foundation Models in Sequential Recommendation, TKDE 2025, arXiv.
- Personalized Parameter-Efficient Fine-Tuning ofFoundation Models for Multimodal Recommendation, WWW 2026, arXiv.
추천 시스템은 유저가 다음에 무엇을 살지 맞히는 일을 해요. 그런데 같은 상품이라도 보는 사람마다 끌리는 지점이 달라요. 아래 이미지를 보고, 골프를 좋아하는 사람은 ‘골프채’을 보고, 캠핑을 좋아하는 사람은 ‘잔디’를 봐요.

이 글에서 다룰 PerPEFT는 이 차이를 모델에 직접 반영해요. 거기까지 가기 위해 sequential recommendation의 기본인 SASRec, foundation model을 싸게 학습하는 PEFT와 IISAN-Versa를 먼저 정리하고, 마지막에 PerPEFT를 설명할게요.
구매 이력을 따라가며
추천에는 여러 형태가 있어요. 그중 sequential recommendation은 유저의 구매 이력을 시간 순서로 본 다음, 바로 다음에 살 아이템을 예측해요. 유저 $u_t$의 이력이 아이템 시퀀스 $[i_{t,1}, i_{t,2}, \cdots, i_{t,n}]$로 주어지면, 모델은 $i_{t,n}$ 다음에 올 아이템을 맞히도록 학습해요.
이 문제를 푸는 고전적인 두 갈래가 있었어요. Markov Chain은 바로 직전 몇 개의 행동만 보고 다음을 예측해요. 데이터가 희소(sparse)할 때 모델이 단순해서 강해요. RNN은 이력 전체를 순차적으로 읽어 장기 패턴을 잡아요. 데이터가 충분히 많을 때 강하지만, 순차 처리라 느리고 먼 과거를 흘려보내기 쉬워요. 둘은 장단점이 반대였어요.
SASRec은 어떻게 다음 아이템을 맞출까
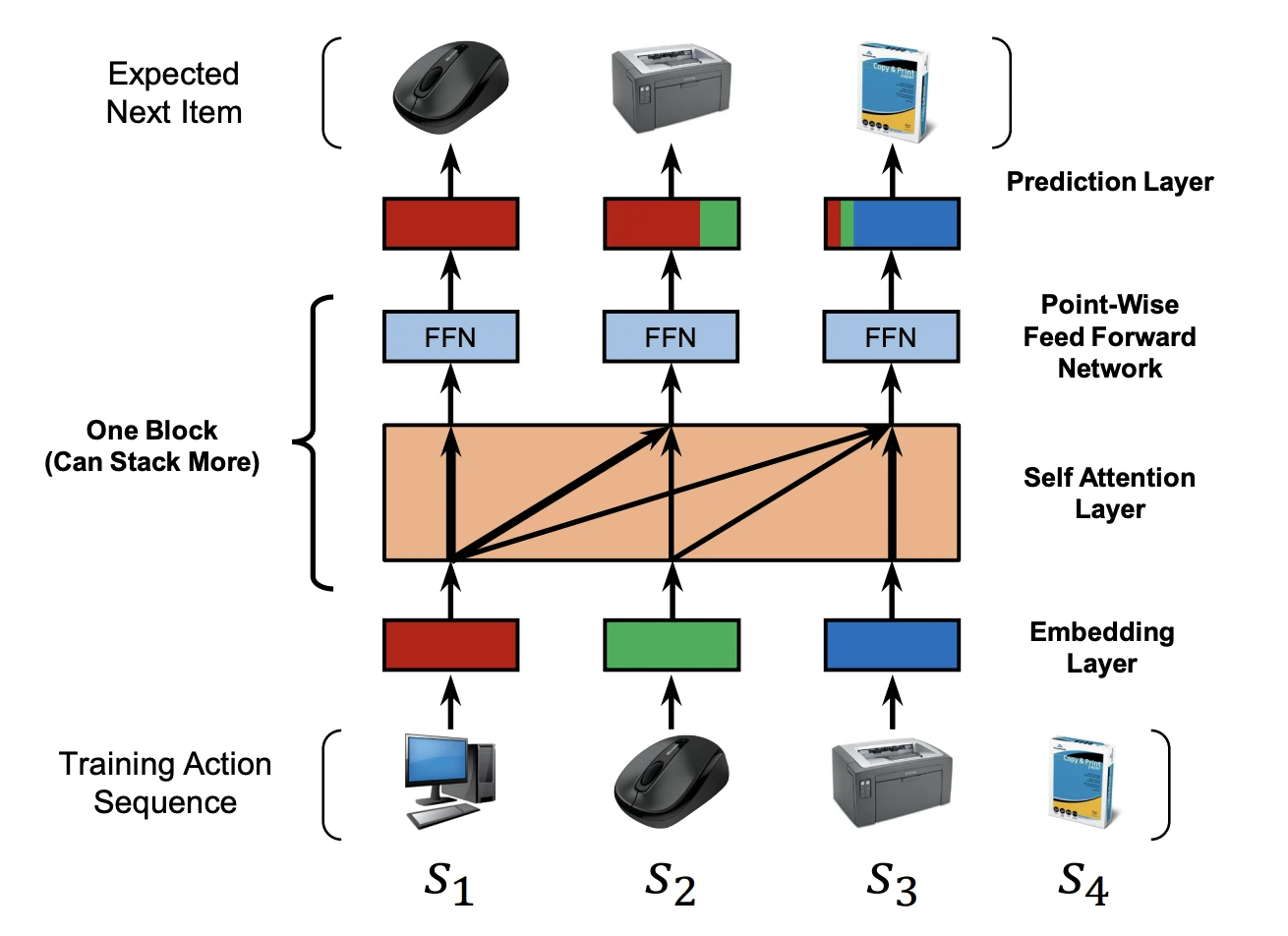
SASRec(Self-Attentive Sequential Recommendation)은 self-attention으로 이 둘의 장점을 합쳐요. RNN처럼 장기 의존성을 보면서, Markov Chain처럼 예측에 필요한 소수의 아이템에만 집중해요. GAT에서 노드가 이웃 중 중요한 것에 가중치를 두던 것과 같은 발상을 시퀀스 위에서 하는 거예요.
구조는 Transformer의 디코더와 닮았어요. 먼저 각 아이템을 임베딩으로 바꾸고, 순서 정보를 담은 positional embedding을 더해요. 그다음 self-attention block을 쌓아요. Attention 연산은 다음과 같아요.
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V\]핵심은 causal mask예요. 위치 $t$의 출력은 위치 $1$부터 $t$까지만 참고할 수 있어요. 미래 아이템을 보고 답을 맞히는 건 반칙이니까요. 이렇게 하면 각 위치가 “지금까지의 이력 중 어떤 아이템이 다음 예측에 중요한지”를 attention weight로 스스로 정해요. RNN과 달리 모든 위치를 병렬로 계산하니 빠르고, Markov Chain과 달리 먼 과거도 필요하면 가져와요.
마지막 층의 출력으로 추천 점수를 매겨요. 위치 $t$의 출력 임베딩과 후보 아이템 임베딩의 내적이 그 아이템의 점수예요. 학습은 정답인 다음 아이템의 점수는 높이고, 무작위로 뽑은 negative 아이템의 점수는 낮추는 binary cross-entropy로 해요. PerPEFT도 이 SASRec을 backbone recommender로 그대로 써요.
멀티모달 정보는 왜 필요할까
지금까지는 아이템을 그저 ID로만 봤어요. ID 기반 모델은 각 아이템에 학습 가능한 임베딩 $\mathbf{h}_k$를 하나씩 주고, 상호작용 데이터로 그 값을 채워요. 문제는 상호작용이 적은 아이템(cold-start)이에요. 데이터가 없으면 임베딩이 비어 있어요.
그래서 아이템의 multimodal metadata를 쓰는 흐름이 커졌어요. 상품의 제목·설명 같은 text와 상품 image에는 ID가 모르는 정보가 담겨 있어요. 멀티모달 추천 연구는 크게 두 갈래로 나뉘어요. 하나는 user-item 그래프 위에서 GCN으로 모달리티 신호를 전파하는 graph 기반 방법이에요. 다른 하나는 multimodal foundation model로 아이템의 text와 image를 임베딩으로 바꿔 쓰는 방법이고, 오늘 소개할 PerPEFT는 후자에요.
대표 foundation model이 CLIP이에요. CLIP은 이미지-텍스트 쌍 $(x_k^{(img)}, y_k^{(txt)})$을 받아 각각의 임베딩 $\mathbf{x}_k$와 $\mathbf{y}_k$를 내놔요. 이렇게 얻은 표현은 cold-start 아이템에도 의미 있는 값을 줘요. 사람이 보고 판단할 단서를 모델도 보는 셈이에요.
Foundation Model을 통째로 학습하면 비싸요
CLIP은 추천이 아니라 일반적인 이미지-텍스트 정렬로 사전학습됐어요. 그래서 그대로 쓰면 “이 상품의 어떤 면이 구매로 이어지는가” 같은 추천 특화 정보는 약해요. Fine-tuning이 성능을 올리는 이유예요.
하지만 CLIP 전체를 학습하는 full fine-tuning은 비싸요. 파라미터가 수억 개라 GPU 메모리와 시간이 크게 들어요. 여기서 PEFT(Parameter-Efficient Fine-Tuning)가 등장해요. PEFT는 사전학습 파라미터 대부분을 얼리고, 작은 모듈만 새로 학습해요.
대표적으로 LoRA는 가중치 갱신 $\Delta W$를 두 개의 저차원 행렬 곱으로 근사해요.
\[W' = W + \Delta W, \qquad \Delta W = BA, \quad B \in \mathbb{R}^{d \times r},\ A \in \mathbb{R}^{r \times k},\ r \ll \min(d, k)\]원래 $W$는 얼린 채로 작은 $A$, $B$만 학습해요. $(\text{IA})^3$는 더 가벼워요. 중간 활성값을 차원별로 다시 스케일하는 학습 가능한 게이트 벡터를 둬서, 정보가 많은 차원을 골라 강조해요.
Decoupled PEFT는 메모리까지 아껴요
PEFT가 학습 파라미터 수를 줄이는 건 맞아요. 그런데 IISAN 연구진은 한 가지 오해를 지적해요. “파라미터 효율 = 전체 효율”이 아니라는 거예요. LoRA나 Adapter처럼 모듈이 backbone 안에 들어있으면, 역전파(backpropagation)가 frozen backbone을 그대로 통과해야 해요. 학습할 파라미터는 적어도 계산 그래프가 무거워서 GPU 메모리와 학습 시간은 크게 줄지 않아요.
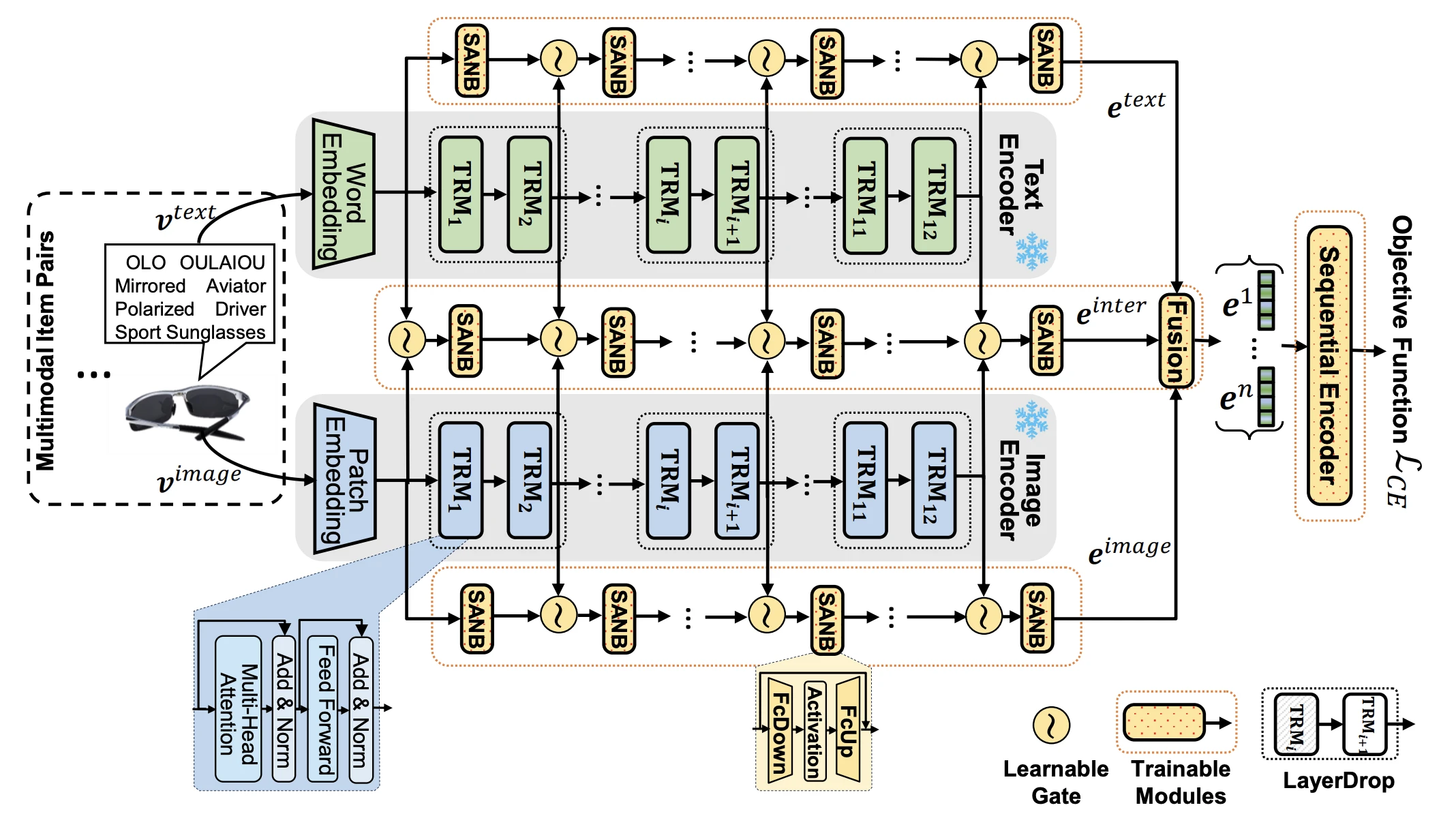
IISAN은 Decoupled PEFT로 이 문제를 풀어요. 학습 모듈을 backbone 밖에 따로 둔 side network로 분리해요. Backbone은 forward만 하고, gradient는 옆에 붙은 side network로만 흘러요. Backbone을 통과하는 역전파가 사라지니 메모리와 속도가 크게 좋아져요. 논문 기준 GPU 메모리는 47GB에서 3GB로, epoch당 학습 시간은 443초에서 22초로 줄었어요. Backbone의 중간 hidden state는 학습 중 변하지 않으니 한 번 계산해 caching해 두고 재사용하는 것도 가능해요.
이름의 의미도 구조와 연결돼요. Intra-modal adaptation은 text·image 각 모달리티 안에서, Inter-modal adaptation은 두 모달리티 사이에서 표현을 조정해요.
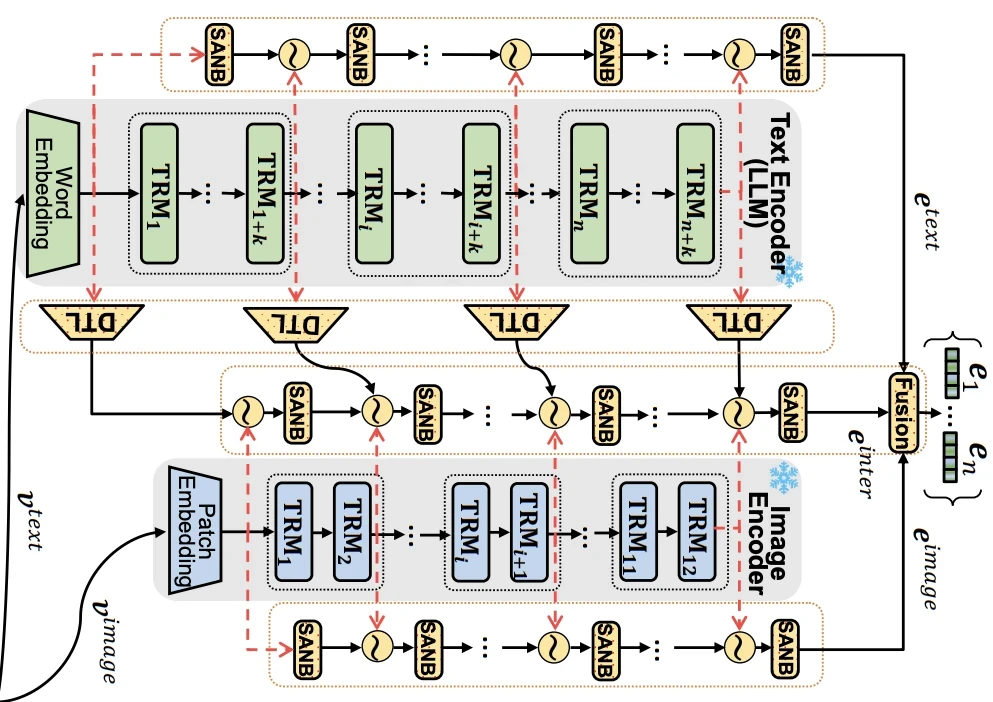
IISAN-Versa는 이 IISAN을 확장한 후속 연구예요. 원래 IISAN은 text와 image encoder의 크기·구조가 같은 symmetrical 모델만 다뤘어요. IISAN이 두 encoder의 hidden state를 층끼리 짝지어 섞는 구조라, 층 수와 차원이 같아야 했기 때문이에요. 하지만 요즘은 큰 LLM을 text encoder로, 작은 ViT를 image encoder로 쓰는 asymmetrical 조합이 흔해요. 보통 text encoder가 vision encoder보다 훨씬 크고, 큰 모델일수록 표현이 좋다는 scaling effect 덕분에 큰 text encoder를 쓰고 싶지만, 기존 IISAN으로는 이 비대칭을 다룰 수 없었어요.
비대칭은 두 가지 구체적인 문제로 갈라져요. 하나는 차원 불일치예요. LLM의 hidden dimension은 수천 차원인데 ViT는 그보다 작아서, 두 모달리티의 hidden state를 그대로 더하거나 섞을 수 없어요. 다른 하나는 층 수 불균형이에요. LLM이 수십 층인 데 비해 ViT는 그보다 적어서, 층끼리 일대일로 짝지을 수 없어요.
IISAN-Versa는 각 문제에 하나씩 해법을 둬요. 차원 불일치는 Dimension Transformation Layer(DTL)로 풀어요. DTL은 큰 LLM의 hidden state $\mathbf{x} \in \mathbb{R}^{d_{in}}$을 작은 vision 쪽 차원 $d_{out}$으로 선형 변환하는 층이에요.
\[\mathbf{z} = \mathbf{W}\mathbf{x} + \mathbf{b}, \qquad \mathbf{W} \in \mathbb{R}^{d_{out} \times d_{in}},\ \mathbf{b} \in \mathbb{R}^{d_{out}},\ d_{in} > d_{out}\]이렇게 LLM의 표현을 vision encoder의 차원에 맞춘 뒤 inter-modal side network에서 두 모달리티를 섞어요. 층 수 불균형은 group LayerDrop으로 풀어요. LLM의 여러 층을 균등한 간격으로 묶어 일부만 골라 쓰고, 나머지는 버려서 vision encoder와 층 수를 맞춰요. 예를 들어 vision encoder가 6개 층을 side network에 넘기면, LLM 쪽도 전체 층에서 6개를 고르게 뽑아 6대 6으로 맞춰요. 깊은 LLM에는 중복된 층이 많아서, 이렇게 솎아내도 성능이 거의 떨어지지 않고 오히려 학습이 가벼워져요. 두 장치 덕분에 층 수와 차원이 다른 encoder 조합에도 side network를 붙일 수 있어요. 그 결과 큰 text encoder일수록 성능이 좋아지는 scaling effect를 확인했고, Microlens 벤치마크에서 state-of-the-art를 기록했어요.
여기까지가 PerPEFT를 이해하기 위한 배경지식이에요. SASRec이라는 backbone, CLIP이라는 foundation model, 그리고 학습을 돕는 PEFT까지 살펴봤어요.
같은 아이템도 유저마다 다르게 봐야 해요
이제 PerPEFT 논문이 던지는 질문이에요. PEFT를 잘 붙여서 CLIP을 추천에 맞게 학습했다고 해 봐요. 그래도 한 가지가 남아요. 학습된 CLIP이 아이템 하나를 받으면 언제나 같은 임베딩을 내놔요. 누가 보든 똑같아요. 논문은 이를 user-blind라고 불러요.
그런데 서두의 예시처럼, 관심사가 다른 유저는 같은 아이템의 다른 면을 봐요. 피규어 수집가는 색감·디자인 같은 외형을 보고, 게이머는 장르를 봐요. 아이템 임베딩이 모두에게 하나뿐이면, 이 차이를 표현에 담을 수 없어요. PerPEFT의 목표는 foundation model이 유저의 관심사에 따라 아이템의 다른 면에 집중하게 만드는 거예요.
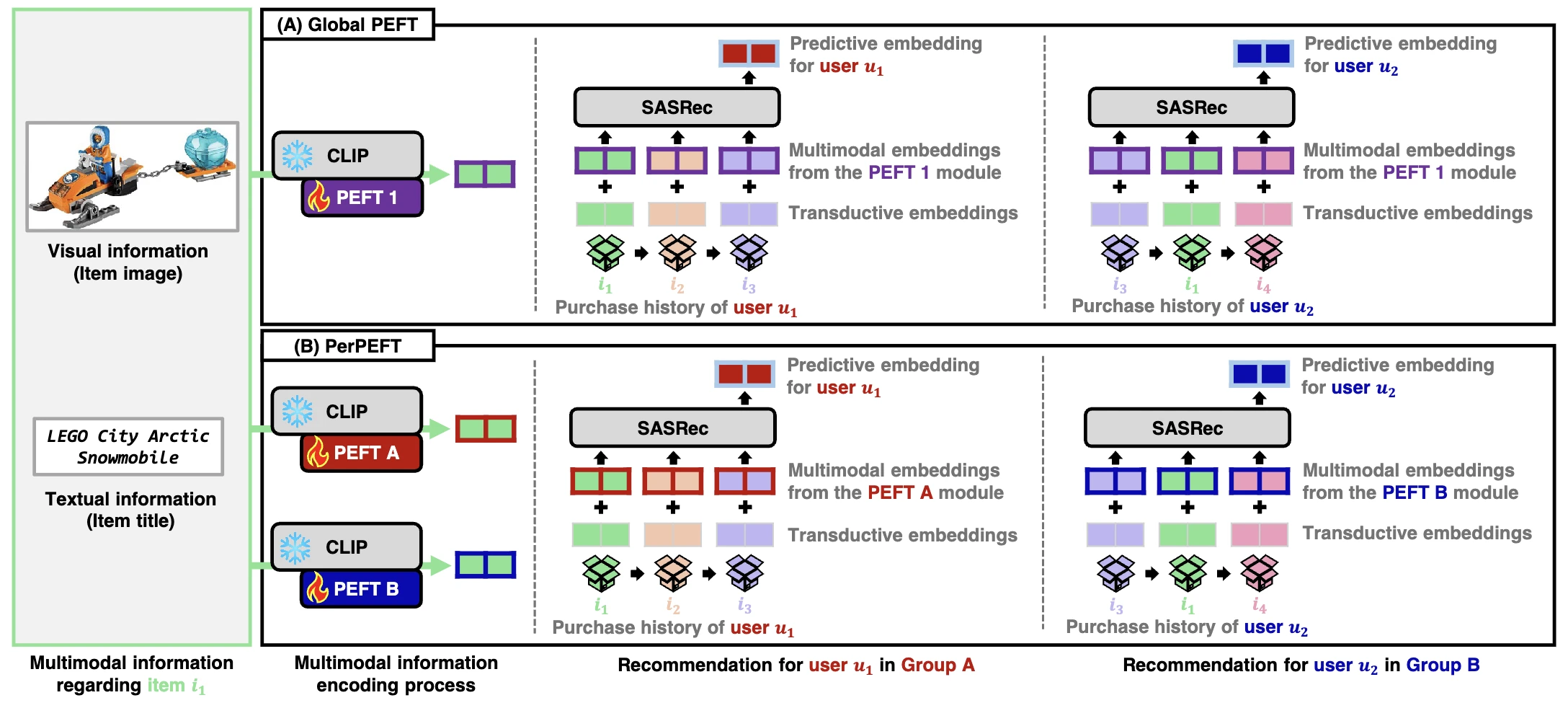
PerPEFT은 유저 그룹마다 PEFT를 따로 둬요
핵심 아이디어는 단순해요. 비슷한 관심사를 가진 유저끼리 묶고, 그룹마다 별도의 PEFT 모듈을 배정해요. 각 모듈은 자기 그룹의 유저로만 학습하니, 그 그룹이 중요하게 여기는 아이템의 면을 골라 배워요. 같은 아이템이라도 어떤 그룹의 모듈로 인코딩하느냐에 따라 다른 임베딩이 나와요. 중요한 점은 PerPEFT가 PEFT-agnostic이라는 거예요. LoRA든 $(\text{IA})^3$든 IISAN이든, foundation model에 붙는 PEFT라면 무엇과도 결합돼요.
Global PEFT로 출발점을 만들어요
비교 기준이자 출발점이 되는 baseline이 Global PEFT예요. 모든 유저가 PEFT 모듈 하나를 공유하는 평범한 방식이에요. 아이템 $i_k$의 임베딩은 이렇게 만들어요. 먼저 PEFT가 붙은 CLIP $f_\theta$로 시각·텍스트 임베딩을 얻어요.
\[f_\theta\!\left(x_k^{(img)}, y_k^{(txt)}\right) = (\mathbf{x}_k, \mathbf{y}_k)\]두 임베딩을 이어 붙여 MLP projector로 멀티모달 임베딩 $\mathbf{m}_k$를 만들어요.
\[\mathbf{m}_k = \text{MLP}\!\left([\mathbf{x}_k \,\|\, \mathbf{y}_k]\right)\]여기에 아이템의 ID 기반 transductive embedding $\mathbf{h}_k$를 더해 최종 아이템 임베딩 $\mathbf{z}_k$를 얻어요.
\[\mathbf{z}_k = \mathbf{m}_k + \mathbf{h}_k\]이 $\mathbf{z}_ k$들을 유저의 구매 순서대로 SASRec에 넣어요. SASRec은 각 위치의 predictive embedding $\mathbf{z}’_ {t,p}$를 내놓고, 정답 다음 아이템과의 내적은 높이고 negative와의 내적은 낮추도록 학습해요. SASRec 스타일의 손실은 다음과 같아요.
\[\mathcal{L}^{(glob)}_t = \sum_{p=1}^{n-1} \log \sigma\!\left(\mathbf{z}_{a_p}^\top \mathbf{z}'_{t,p}\right) - \sum_{p=1}^{n-1} \log \sigma\!\left(\mathbf{z}_{t,(p+1)}^\top \mathbf{z}'_{t,p}\right)\]식을 하나씩 뜯어볼게요. $\mathbf{z}’_ {t,p}$는 1번부터 $p$번 아이템까지 봤을 때 “다음에 올 아이템은 무엇일까”를 담은 예측 벡터예요. $\mathbf{z}_ {t,(p+1)}$는 정답 다음 아이템의 임베딩이에요. 위치 $p$의 진짜 다음은 $p+1$번이니까요. 이게 positive sample이고, $\mathbf{z}_ {a_p}$는 위치마다 무작위로 뽑은 negative sample $i_ {a_p}$의 임베딩, $\sigma$는 sigmoid예요. 한 아이템이 “다음 아이템”일 점수는 예측 $\mathbf{z}’_ {t,p}$와 후보 아이템 임베딩의 내적으로 정의돼요. 내적이 크면 모델이 그 아이템을 다음으로 강하게 민다는 뜻이에요.
원칙대로라면 전체 아이템 집합 $\mathcal{I}$에 softmax를 씌워 정답이 1위가 되게 학습하는 게 자연스러워요. 하지만 $\mathcal{I}$가 수만 개면 위치마다 모든 아이템과 내적을 계산해야 해서 너무 비싸요. Negative sampling은 정답 하나와 무작위 오답 하나만 비교해 이 비용을 줄이면서도 비슷한 효과를 내요. 이 손실로 PEFT 모듈 $\theta$, transductive embedding $\mathbf{h}$, MLP projector, backbone SASRec을 함께 업데이트해요. 뒤에서 다룰 PerPEFT의 hard negative sampling이 바로 이 식의 negative 항, 즉 $\mathbf{z}_{a_p}$를 무엇으로 채우느냐를 바꾸는 기법이에요.
유저를 관심사로 묶어요
그룹을 나누려면 유저의 관심사를 벡터로 표현해야 해요. PerPEFT는 방금 학습한 Global PEFT를 그대로 활용해요. SASRec이 유저 $u_t$의 전체 이력을 읽고 내놓는 마지막 predictive embedding $\mathbf{u}_t$를 그 유저의 interest representation으로 써요. 이 벡터는 “다음에 살 아이템”을 맞히도록 최적화됐으니, 유저의 취향을 잘 압축하고 있어요.
이 $\mathbf{u}_t$들에 K-Means clustering을 적용해 $C$개의 그룹으로 나눠요. 각 그룹은 서로 겹치지 않아요.
\[\mathcal{U} = \bigcup_{c=1}^{C} \mathcal{U}^{(c)}\]군집화 알고리즘이 K-Means여야 하는 건 아니에요. 다른 방법으로도 비슷한 성능이 나와요. 그룹을 나눈 뒤에는 그룹마다 별도의 PEFT 모듈 $\theta^{(c)}$를 두고, 각 모듈을 자기 그룹 $\mathcal{U}^{(c)}$의 유저로만 학습해요. 그룹별로 학습 데이터가 분리되니, 각 모듈이 자기 그룹에 특화돼요.
그룹에 맞는 Hard Negative로 전문성을 키워요
그룹을 나누고 모듈을 따로 두는 것만으로는 부족할 수 있어요. 모듈이 그룹의 색을 충분히 띠지 않으면, 결국 Global PEFT와 비슷해져요. PerPEFT는 이를 위해 group-specific hard negative sampling을 도입해요.
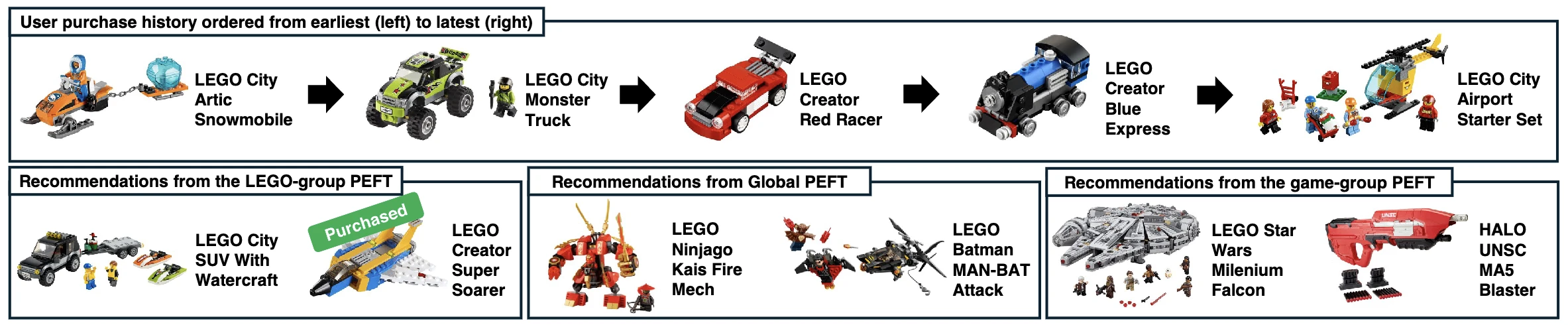
Negative sampling에서 무작위 아이템을 negative로 쓰면, 정답과 너무 동떨어져 있어 모델이 쉽게 구별해요. 학습 신호가 약한 거예요. Hard negative는 정답과 헷갈리기 쉬운, 즉 점수가 비슷하게 높은 아이템을 골라 negative로 써요. PerPEFT는 negative를 뽑는 풀(pool) 자체를 바꿔요. Global PEFT는 식 $\mathcal{L}^{(glob)}_ t$의 negative $i_ {a_p}$를 전체 아이템 집합 $\mathcal{I}$에서 무작위로 뽑았어요. PerPEFT는 그룹 $c$의 모듈을 학습할 때, $\mathcal{I}$ 전체가 아니라 그 그룹 유저들의 구매 이력에 등장한 아이템들 중에서만 negative를 뽑아요. 골프 그룹을 학습한다면, 골프 그룹 유저들이 실제로 산 아이템들이 negative 후보가 되는 거예요.
왜 이게 hard negative가 되는지 짚어볼게요. 같은 그룹 유저들이 산 아이템끼리는 관심사가 비슷해서 서로 닮아 있어요. 골프 그룹 안에서는 골프 장갑, 골프 티, 골프 가방이 다 같이 등장해요. 정답이 골프 가방일 때, 무작위로 뽑은 주방용품은 너무 쉬운 negative지만, 같은 그룹에서 뽑은 골프 티는 정답과 비슷해서 헷갈리는 hard negative예요. 모델은 이 둘을 가르려고, “둘 다 골프 용품이지만 이 유저가 다음에 살 건 가방이다”를 구별하는 단서, 즉 Golf라는 공통점 너머의 미세한 차이를 배워야 해요. 그 차이가 바로 그 그룹이 구매에서 중요하게 여기는 아이템의 면이에요.
식으로 보면 달라지는 곳은 한 군데예요. negative $i_{a_p}$를 뽑는 집합이 $\mathcal{I}$에서 그룹 $c$의 구매 이력 아이템 집합으로 바뀌어요. 손실의 뼈대도, positive 항도 그대로예요. 이렇게 negative 풀만 그룹에 맞추는 것으로 user-group conditioning이 강해지면서, 모듈마다 구매로 이어지는 고유한 단서를 배워요. 논문의 case study를 보면, 골프 가방을 골프 그룹의 모듈로 인코딩하면 Golf 토큰에 attention이 가장 높게 쏠리고, 캠핑 그룹의 모듈로는 Travel과 Bag에 더 높게 쏠려요. user-blind 문제가 실제로 풀린 거예요.
개인화의 비용은 얼마일까
그룹마다 모듈을 따로 두면 파라미터가 그룹 수만큼 늘 것 같아요. 하지만 PEFT 모듈 자체가 워낙 작아서, 여러 개를 합쳐도 부담이 작아요. 논문 기준 모든 PEFT 모듈을 합쳐도 foundation model 파라미터의 1.3%에 불과해요. 개인화를 얻으면서도 여전히 lightweight예요.

성능은 분명해요. 네 개의 e-commerce 데이터셋과 일곱 개의 baseline에서, PerPEFT는 48개 설정 중 44개에서 기존 개인화 기법을 앞섰어요. 가장 강한 baseline 대비 NDCG@20 기준 최대 15.3% 향상을 얻었어요. LoRA, $(\text{IA})^3$, IISAN 등 어떤 PEFT와 결합해도 일관되게 좋아졌고, 이는 PerPEFT가 특정 PEFT가 아니라 “그룹별로 모듈을 나눈다”는 전략 자체의 효과임을 보여줘요.