바로 써먹는 LLM-as-a-judge 가이드
LLM-as-a-judge를 주제로 주요 개념과 방법론을 정리해요. 2023–26년 ACL, EMNLP, ICLR, CVPR, ICCV 등에 게재된 주요 논문을 근거로 해요.
LLM 평가가 왜 필요할까
시스템을 평가할 때는 다양한 평가 지표를 활용해요. 대부분의 경우 데이터에 기록된 정답을 바탕으로 명확한 평가가 가능해요. 하지만 개방형 질문에 대한 LLM 답변은 하나의 완벽한 정답이 존재하지 않아요. 대표적인 예가 의료 상담이에요. 여러 평가 기준으로 의료 챗봇의 답변이 적절한지 판단할 수 있지만, 단 하나의 정답이 있다고 보기는 어려워요. 이런 상황에서는 사람의 평가에 의존해 왔어요. 그런데 사람의 평가에는 한계가 있어요. 데이터 전체를 검수하는 데 비용이 많이 들고, 평가 기준이 주어지더라도 사람마다 결과가 달라질 수 있어요. 일관성을 확보하려면 복잡한 장치가 필요해요. 삼성서울병원의 연구를 보면, 평가 신뢰도를 높이기 위해 전문가 간 토론을 진행하고 1주 후 재평가를 수행했다고 해요. 이처럼 일관된 평가를 얻기는 매우 어려워요.
이 문제를 해결하기 위해 자연어처리 분야에서는 BLEU, ROUGE, BERTScore 등 정량적 평가 지표를 정의해 왔어요. 하지만 이런 지표는 실제 인간 선호도와 차이가 있고, 문장이 가진 복합적인 뉘앙스를 포착하는 데 한계가 있어요. 최근에는 LLM을 활용해 문장을 평가하는 LLM-as-a-judge 방법론이 주목받고 있어요.
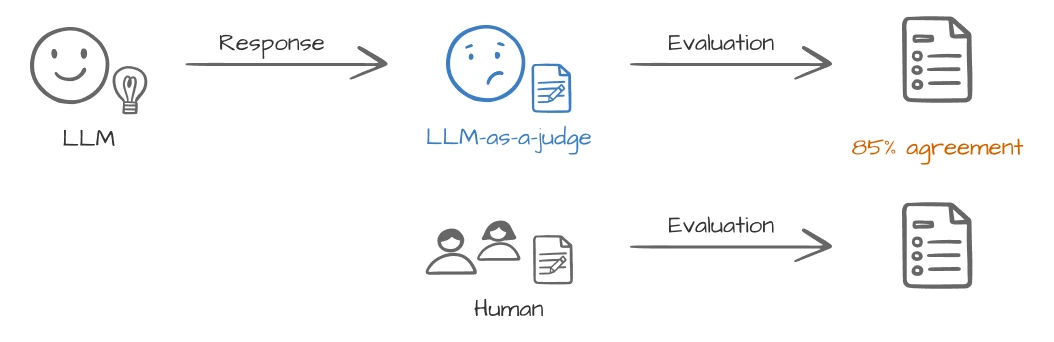
LLM을 활용하면 복잡한 맥락을 이해할 수 있을 뿐만 아니라 많은 양의 데이터를 일관되게 평가할 수 있어요. LLM이 사람과 비슷한 수준의 평가를 할 수 있을지 의문이 들 수 있는데, 결론부터 말하면 가능해요. GPT-4를 이용한 평가는 인간 전문가 평가와 85% 일치한다고 해요. 이는 사람 간 평가 일치도인 81%보다 높은 수준이에요. 즉, LLM이 생각보다 정확하고 일관된 평가를 할 수 있어요. 물론 모든 LLM이 정확한 건 아니에요. 적절한 모델과 방법으로 LLM-as-a-judge를 구축하는 것이 중요해요.
LLM 모델은 뭘 써야 할까
LLM-as-a-judge는 인간 선호도를 잘 반영한 모델이 좋은 성능을 보여요. 주요 논문에서는 GPT-4를 사용해요. GPT는 ChatGPT 서비스를 통해 RLHF(Reinforcement Learning from Human Feedback)로 학습되었어요. 즉, 인간 선호도에 맞게 튜닝된 모델이에요. 그래서 LLM-as-a-judge로 사용하기 적합하다고 설명해요. 최근에는 Gemini 2.5 Pro나 Claude 4.5 등의 모델도 시도되고 있지만, 아직 사례가 많지 않아요.
물론 GPT-4가 항상 정답은 아니에요. 코딩이나 수학처럼 추론(reasoning)이 필요한 문제를 평가할 때는 o3처럼 추론에 특화된 모델이 더 적합할 수 있어요. GPT-5가 출시된 지 얼마 되지 않아 관련 실험이 많지 않지만, 앞으로 GPT-5 추론 기반의 judge도 논의되지 않을까 싶어요.
사용 모델 외에, 평가를 위해 fine-tune한 모델도 존재해요. 대표적으로 Prometheus가 있어요. Prometheus-7B는 Mistral-7B를 학습시켜 GPT-3.5를 뛰어넘는 사람과의 일치도를 보였어요. GPT-4나 Claude-3 Opus보다는 낮은 점수지만, LLM-as-a-judge를 어떻게 학습해야 하는지에 대한 방향을 제시했다는 데 의의가 있어요. 작은 모델로 LLM-as-a-judge를 구축하고 싶다면 고려해 볼 만해요.
관련 라이브러리로는 DeepEval과 Prometheus-Eval이 있어요. 에이전트 구현이 가능하다면 Langchain으로 직접 구현하거나 Langchain OpenEval을 활용하는 방법도 있어요.
실제 프롬프트 알아보기
점수 매기기
Point-wise라고 불리는 방식은 답변에 점수를 매겨 평가하는 방식이에요. 아래는 프롬프트 예시에요.
1
2
3
4
5
6
7
8
9
## Role: You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria...
## Evaluation Standard
### [평가기준] (1-5 points)
[설명]...
## Instruction: You should evaluate the assistant's response based on the provided criteria and assign a score.
## Response to evaluate:
{답변}
일반적으로 많이 사용하는 방식이에요. 답변 형식을 강제하는 등 다양한 장치를 추가해 활용할 수 있어요.
A/B 중 선택하기
Pair-wise라고 불리는 방식은 여러 답변 중 가장 뛰어난 답변 하나를 선택하는 방식이에요. 아래는 프롬프트 예시에요.
1
2
3
4
5
6
7
8
9
10
## Role: You are a fair judge assistant assigned to be deliver insightful feedback that compares individual performances...
## Evaluation Standard
### [평가기준]: [설명]...
## Instruction: You should choose the assistant that follows the user's instructions and answers the user's question better.
## Response A:
{답변 A}
## Response B:
{답변 B}
공정한 평가를 위해 모델을 A/B로 익명화해서 사용해요. 이 방식은 A/B 중 하나를 선택하도록 강제해요. 동점(tie)을 출력하도록 프롬프트를 구성할 수도 있지만, 여러 문제가 있어 공정한 평가가 어려워요. 자세한 내용은 아래에서 설명할게요.
LLM도 편견을 가지고 평가하더라
Point-wise와 Pair-wise 방식을 살펴봤어요. 이번 챕터에서는 이 방식을 적용할 때 주의해야 할 점을 알아봐요. 아래는 LLM이 공통적으로 가지는 문제점이에요.
- Length bias: LLM은 긴 답변을 선호해요. 평가 기준에 따라 비슷한 평가를 받은 답변이라면 비교적 길고 권위 있어 보이는 문장을 선택할 가능성이 있어요.
- Position bias: LLM은 특정 위치를 선호해요. A/B로 익명화한 답변을 제공했을 때, 내용보다 A/B 위치를 보고 선택할 가능성이 있어요.
- Egocentric bias: LLM은 자신이 생성한 답변을 높게 평가해요. 예를 들어, GPT-4로 생성한 답변을 GPT-4가 평가하면 비교적 높게 평가할 가능성이 있어요.
- Preference leakage: LLM은 자신과 비슷한 모델을 높게 평가하는 경향이 있어요. 예를 들어, GPT-4로 합성 데이터를 생성하고 student 모델을 학습시킨다면, 해당 모델의 답변을 높게 평가해요.
- Scoring bias: LLM은 특정 점수를 선호하는 경향이 있어요. 예를 들어, 1-5점 척도로 평가를 지시했을 때 무난하게 4점을 출력하는 문제가 있어요.

그 외에도 모델을 익명화하는 문자(예: A/B, 1/2, ⅰ/ⅱ)나 스케일 방향(예: 5점이 좋은 쪽, 1점이 좋은 쪽)에 따라 편향이 발생하기도 해요. 필자도 llama3-8B를 사용하면서 비슷한 문제를 관찰했어요. 이런 편향은 크고 성능 좋은 base model일수록 줄어드는 모습을 보여요.
LLM 평가를 위한 잡기술
LLM 답변 성능을 높이기 위한 few-shot, RAG 등의 기법을 동일하게 적용할 수 있어요. LLM-as-a-judge도 결국 LLM 성능에 의존하기 때문이에요. 아래에서는 성능 개선을 위해 구체적으로 어떤 설계가 가능한지 알아봐요.
말하기 전에 생각했나요
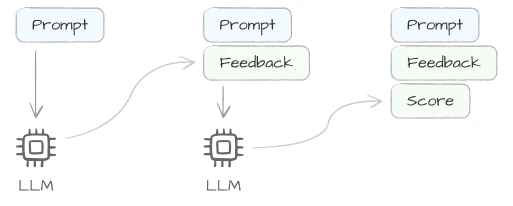
점수를 출력할 때 평가 근거를 함께 출력하면 모델의 판단을 확인할 수 있어요. 이는 CoT(Chain-of-Thought)를 활용하는 전략으로, 평가 과정을 투명하게 관찰할 수 있을 뿐만 아니라 실제 평가 성능도 높아지는 효과가 있어요. 프롬프트 예시는 다음과 같아요.
1
2
3
4
5
6
## Evaluation Step:
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: “Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)”
4. Please do not generate any other opening, closing, and explanations.
...
대충 말하지 마세요
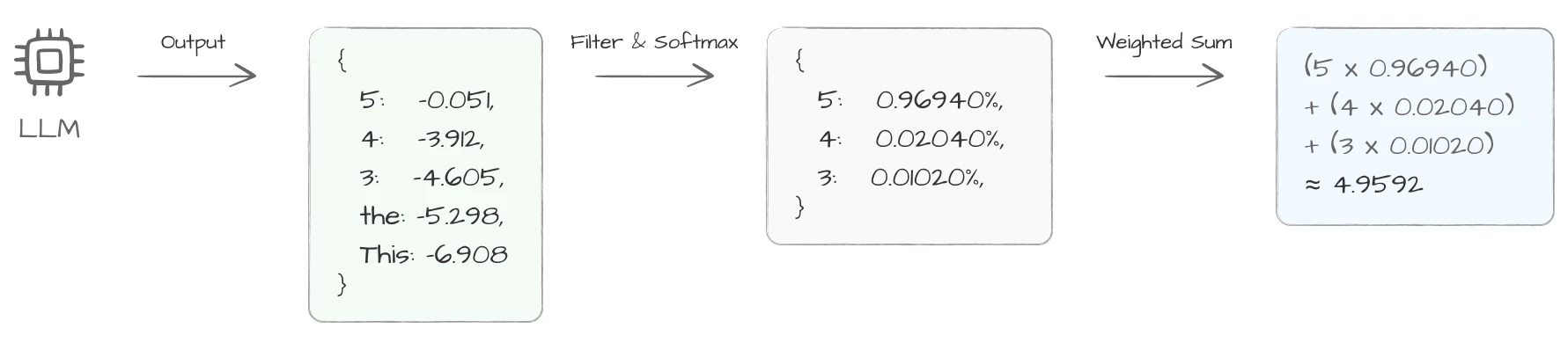
LLM은 1-10점 척도보다 1-5점 척도가 인간 평가와 더 높은 유사도를 보인다고 해요. 하지만 그냥 평가를 시키면 애매한 경우 4점을 출력해 버리는 문제가 생기기도 해요. 이를 보완하기 위해 각 점수에 대한 출력 확률을 보고 가중합을 계산하는 방법이 있어요.
1
2
3
4
5
6
7
8
9
10
11
12
13
prompt = """\
...
Assign a score on a scale of 1 to 5, where 1 is the lowest and 5 is the highest based on the Evaluation Criteria.
Evaluation (score ONLY):"""
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}],
logprobs=True, # 토큰별 로그 확률 요청
top_logprobs=5, # 상위 5개 토큰 확률 확인
temperature=0
)
상위 5개 토큰의 확률을 검사해요. 이 중 1-5 사이 숫자가 있다면 해당 숫자의 log 확률을 추출해요. 숫자가 아닌 토큰이 섞여 있을 수 있으므로 합이 1이 되도록 정규화한 뒤 가중합을 계산해요. 그러면 4.96과 같이 정밀한 점수로 평가할 수 있어요. 모델의 출력 확률을 활용해 점수를 재구성하는 방법이에요.
스스로 평가하고 수정하면 안 될까
모델이 스스로 답변을 평가하고 피드백을 바탕으로 출력을 수정하는 과정을 self-correction, self-refinement 또는 self-critique라고 불러요. 이 방법은 LLM-as-a-judge를 사용하는 것 대비 명확한 장점이 없어 보여요. 스스로 피드백하는 경우 성능 향상이 없거나 오히려 떨어졌다는 연구도 있어요. 앞서 언급했듯 스스로에 대해 좋게 평가하는 경향이 있어 객관적인 판단이 어려운 것으로 보여요.
하지만 자가 피드백이 도움이 되는 상황도 있어요. (1) 문제를 여러 단계로 나눌 수 있을 때, 즉 생성보다 평가가 쉬운 문제에서는 스스로 피드백하는 단계가 도움이 돼요. 예를 들어, “부산 출신 배우 이름 몇 명을 출력해”라고 하면 여러 답변이 동시에 생성돼요. 비판 단계에서는 답변 쪼개어 하나하나를 검사하며 오류를 찾아낼 수 있어요. (2) 또 다른 상황은 피드백 단계에서 새로운 정보를 활용할 수 있을 때에요. 예를 들어, “…하는 python 코드를 생성해”라는 명령이 주어졌다면, 피드백 단계에서 실제 python interpreter나 linter로 코드를 검증할 수 있어요. 다만 피드백 단계에서 웹 검색 등으로 새로운 정보를 주입할 계획이라면, 생성 단계에서 정보를 모두 제공하고 한 번에 제대로 생성하는 방향을 먼저 고려하는 게 좋아요.
멀티턴 대화 평가는 뭐가 다를까
멀티턴 대화는 단일 문장 평가보다 많은 정보를 담고 있어 평가 난이도가 높아요. 아직 명확한 정답이 없는 분야로, 다양한 접근법이 시도되고 있어요. 확실한 건 문장을 하나씩 평가하는 것보다 전체 대화를 입력하는 쪽이 정확한 평가에 도움이 된다는 점이에요. 문장을 끊어서 넣으면 대화 맥락을 파악할 수 없기 때문이에요. 최근 Gemini 2.5 Pro 급의 대형 모델이 12턴 정도의 대화 맥락을 다룰 수 있다는 연구가 있었어요. Context window 크기가 커진 덕분에 대화 전체를 입력해도 어느 정도 처리가 가능해요.
그렇다면 대화가 더 길어지면 어떨까요? 이와 관련해 아직 연구된 논문이 많지 않아요. 대안으로는 DeepEval의 sliding window 전략을 참고할 수 있어요. DeepEval은 연구 논문이 아닌 LLM-as-a-judge 구현을 돕는 오픈소스 개발 프레임워크에요. DeepEval은 전체 대화를 3-5턴 단위로 나눈 뒤 각 청크를 평가하는 방식을 제안해요. 이처럼 sliding window로 대화를 나누면 context 길이를 제한하면서도 대화 맥락을 파악할 수 있어요.
앞서 살펴본 전략을 결합하는 방법도 생각해 볼 수 있어요. 대화 전체를 통해 큰 단위의 특징을 평가하고, 작은 대화 청크를 통해 세부적인 특징을 평가하는 방식이에요. 예를 들어, 대화 전체를 입력해 주제 일관성을 평가하고, sliding window 방식으로 문장 적절성을 평가할 수 있어요.
아직 단일 해결책이 없는 문제인 만큼, 해당 도메인의 대화 특성을 파악하는 것도 중요해요. 예를 들어, 심리 상담 대화라면 상담 세션별로 대화를 나눠 평가하는 것이 단순히 sliding window로 자르는 것보다 맥락 파악에 유리할 수 있어요.
이미지도 평가할 수 있을까
멀티모달 이해 능력으로 이미지를 평가하는 모델을 MLLM(Multimodal LLM)-as-a-judge라고 해요. MLLM-as-a-judge에서도 GPT-4V가 전반적으로 좋은 성능을 보여요. 다만 텍스트 기반의 LLM-as-a-judge에 비하면 평가 능력이 아직 부족한 편이에요. 평가 방식은 두 가지로 나뉘어요. (a) 이미지와 텍스트 프롬프트를 함께 사용하는 방법과 (b) 이미지에 대한 상세한 자연어 설명과 프롬프트를 함께 사용하는 방법인데, 후자가 더 정확한 판단을 내리는 것으로 알려져 있어요. MLLM-as-a-judge의 가장 큰 문제는 모델 자체의 멀티모달 이해 능력에 있어요. 시각적 추론을 제대로 수행하지 못하는 데서 비롯된 문제예요. 이 때문에 LLaVA 같은 오픈소스 모델을 인간 선호도에 맞게 학습하는 방법론이 논의되고 있어요.
LLM-as-a-judge에서 활용하던 기법들도 MLLM-as-a-judge에서는 잘 통하지 않아요. CoT를 적용하면 모델이 지시를 따르지 못해 평가 점수가 오히려 떨어져요. 이 역시 모델의 추론 능력 부족 때문이에요. LLM에서는 CoT가 context를 풍부하게 만들어 주지만, MLLM은 늘어난 context를 충분히 소화하지 못해요. Inference time scaling도 일관된 성능 향상을 보장하지 않아요. 구체적으로는, 하나의 문제에 대해 여러 답변을 독립적으로 생성한 뒤 다수결 투표로 최종 답변을 선택하는 방식인데, Qwen2-VL-72B를 포함한 여러 오픈소스 모델에서 성능 저하가 나타나요.
LLM-as-a-judge에서 관찰된 편향 문제도 동일하게 나타나요. 위치에 따른 positional bias, 자기 자신을 선호하는 egocentric bias 등이 대표적이에요.
참고문헌
- From Generation to Judgment: Opportunities and Challenges of LLM-as-a-judge, EMNLP, 2025.
- G-eval: NLG evaluation using gpt-4 with better human alignment, EMNLP, 2023.
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, NeurIPS, 2023.
- MT-Eval: A Multi-Turn Capabilities Evaluation Benchmark for Large Language Models, EMNLP, 2024.
- Prometheus: Inducing Fine-grained Evaluation Capability in Language Models, ICLR, 2023.
- Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, EMNLP, 2024.
- JudgeBench: A Benchmark for Evaluating LLM-Based Judges, ICLR, 2025.
- Evaluating Scoring Bias in LLM-as-a-Judge, arXiv, 2025.
- Grading Scale Impact on LLM-as-a-Judge: Human-LLM Alignment Is Highest on 0-5 Grading Scale, arXiv, 2026.
- Preference Leakage: A Contamination Problem in LLM-as-a-judge, ICLR, 2026.
- When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs, ACL, 2024.
- Branch-Solve-Merge Improves Large Language Model Evaluation and Generation, NAACL, 2024.
- Multichallenge: A realistic multi-turn conversation evaluation benchmark challenging to frontier llms, ACL, 2025.
- Multi-Turn LLM Evaluation in 2026: What You Need to Know, Confident AI, https://www.confident-ai.com/blog/multi-turn-llm-evaluation-in-2026.
- Agent-as-a-judge: Evaluating agents with agents, (openreview), 2025.
- CPsyCoun: A Report-based Multi-turn Dialogue Reconstruction and Evaluation Framework for Chinese Psychological Counseling, ACL, 2024.
- MedDialogRubrics: A Comprehensive Benchmark and Evaluation Framework for Multi-turn Medical Consultations in Large Language Models, arXiv, 2026.
- Evaluation framework of large language models in medical documentation, JMIR, 2024.
- MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark, ICML 2024.
- VL-RewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models, 2025, CVPR.
- LLaVA-Critic: Learning to Evaluate Multimodal Models, CVPR, 2025.
- GenAI Arena: An Open Evaluation Platform for Generative Models, NeurIPS, 2024.
- RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback, CVPR, 2024.