SAM에서 Efficient Track Anything까지
- Segment Anything, ICCV 2023.
- SAM 2: Segment Anything in Images and Videos, ICLR 2025.
- EfficientViT-SAM: Accelerated Segment Anything Model Without Accuracy Loss, CVPR 2024.
- Efficient Track Anything, ICCV 2025.

이 글에서는 Segment Anything Model(SAM)의 구조를 먼저 살펴보고, SAM 2가 비디오로 확장되면서 추가된 메모리 메커니즘을 정리한 뒤, EfficientTAM이 어떻게 SAM 2의 효율 병목을 해결했는지 설명해요.
SAM은 무엇을 해결하려 했을까
Segment Anything, ICCV 2023.
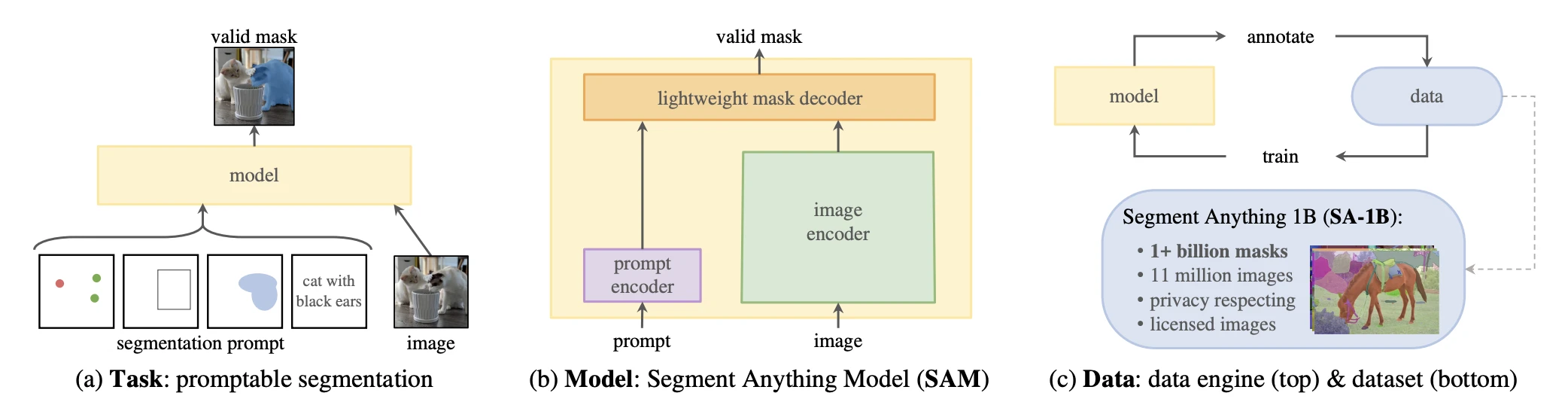
NLP에서 GPT가 프롬프트 하나로 다양한 태스크를 수행하듯, image segmentation에도 같은 패러다임을 적용할 수 있을까요? SAM은 이 질문에서 출발해요. 점, 박스, 마스크, 텍스트 같은 프롬프트를 주면 해당 객체의 segmentation mask를 반환하는 promptable segmentation이라는 태스크를 정의했어요.
SAM의 구조는 세 가지 모듈로 구성돼요.
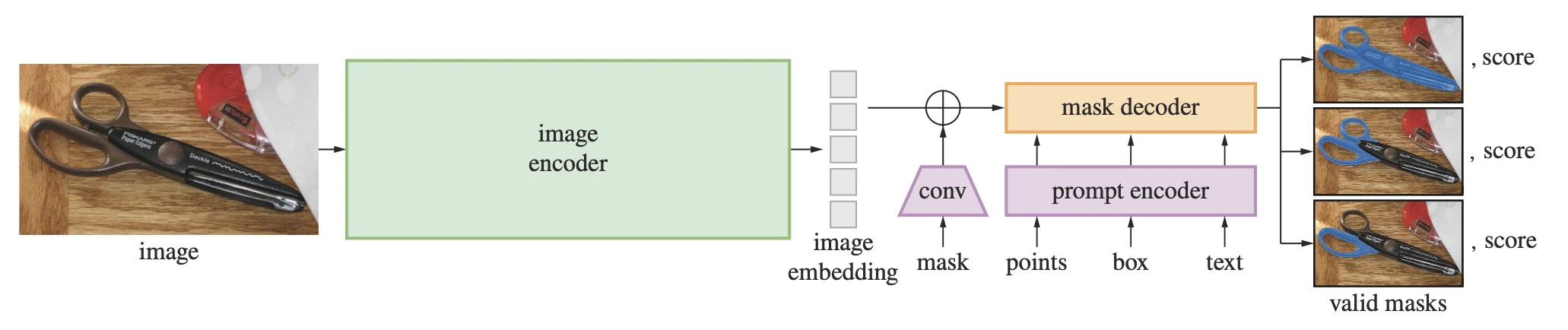
Image encoder는 MAE로 사전학습된 ViT-H/16이에요. 1024×1024 이미지를 받아 64×64×256 크기의 image embedding을 출력해요. 이 인코더는 이미지당 한 번만 실행되고, 이후 여러 프롬프트에 대해 임베딩을 재사용해요. 무거운 연산을 한 번으로 amortize하는 구조예요.
Prompt encoder는 sparse 프롬프트(점, 박스, 텍스트)와 dense 프롬프트(마스크)를 처리해요. 점과 박스는 positional encoding에 학습된 type embedding을 더해 표현하고, 마스크는 convolution으로 다운샘플한 뒤 image embedding에 element-wise로 더해요.
Mask decoder는 가벼운 transformer 디코더예요. Prompt token과 image embedding을 양방향(two-way) cross-attention으로 업데이트하는 블록 2개를 쌓았어요. 하나의 프롬프트가 여러 객체를 가리킬 수 있으므로(예: 셔츠 위의 점이 셔츠를 가리키는지 사람 전체를 가리키는지), 3개의 mask와 각 mask의 IoU score를 동시에 예측해요. 학습 시에는 ground truth와 가장 가까운 mask에 대해서만 loss를 backprop해요. Focal loss와 dice loss를 20:1로 조합한 것이 학습 손실이에요.
이 디코더는 image embedding이 이미 계산된 상태에서 약 50ms(CPU, 웹 브라우저)에 동작해요. 프롬프트를 바꿔가며 실시간으로 마스크를 확인할 수 있는 interactive segmentation이 가능한 이유예요.
SAM 2는 비디오로 어떻게 확장했을까
SAM 2: Segment Anything in Images and Videos, 2024.
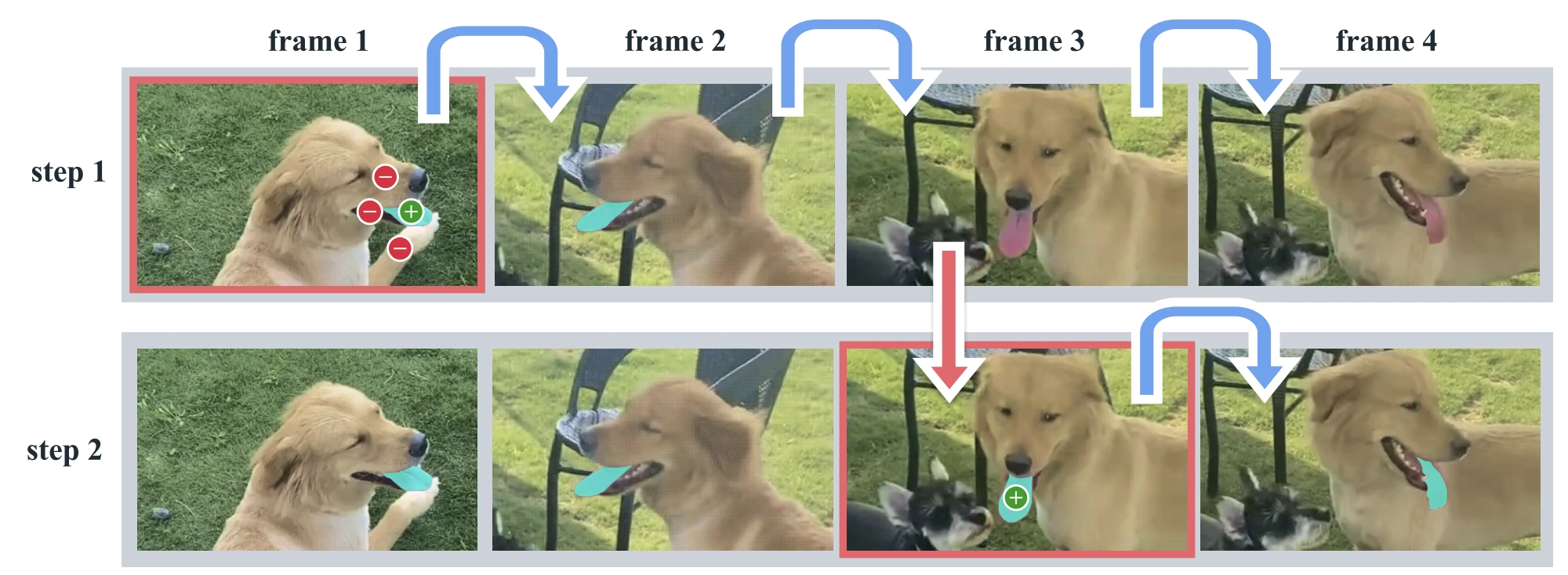
이미지는 현실 세계의 정지 스냅샷일 뿐이에요. 객체는 움직이고, 가려지고, 다시 나타나요. SAM 2는 이미지와 비디오를 하나의 모델로 처리하는 Promptable Visual Segmentation(PVS) 태스크를 정의했어요. 비디오의 아무 프레임에나 프롬프트를 주면, 전체 비디오에 걸쳐 해당 객체의 시공간 마스크(masklet)를 예측해요.
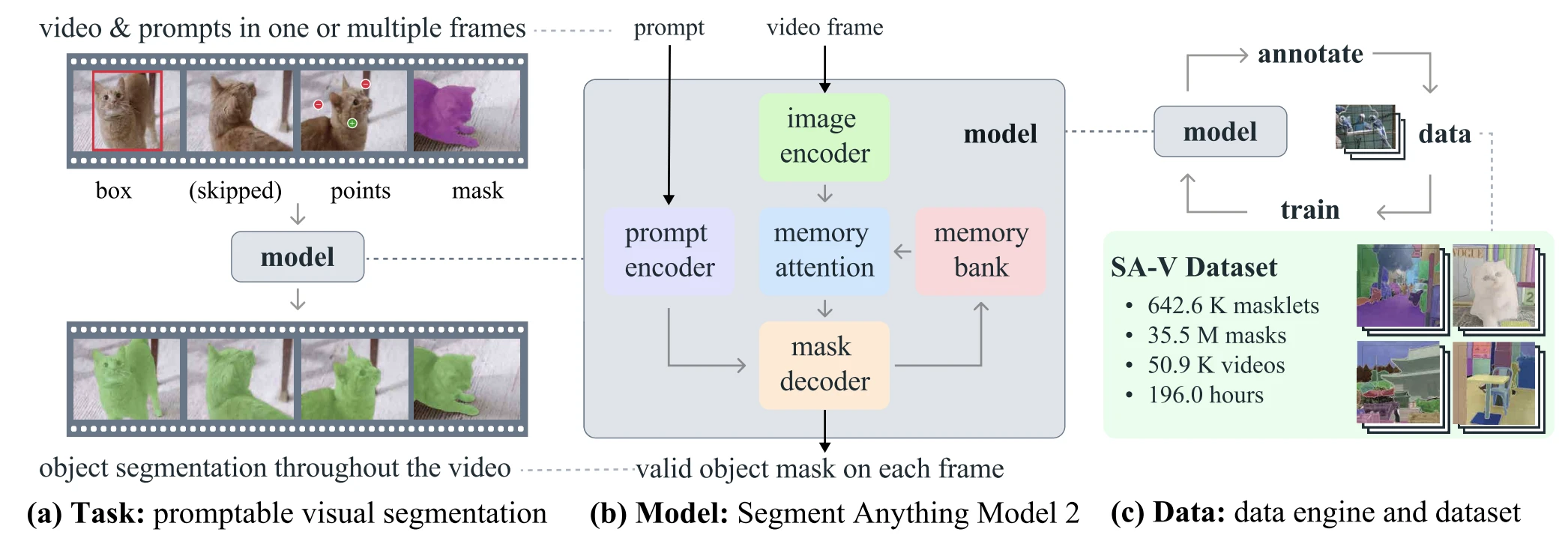
SAM 2의 핵심은 streaming memory예요. 이미지에 적용할 때는 메모리가 비어 있어 SAM처럼 동작하고, 비디오에서는 과거 프레임의 정보를 기억해 현재 프레임의 예측에 활용해요.
SAM 2의 이미지 인코더가 바뀌었다
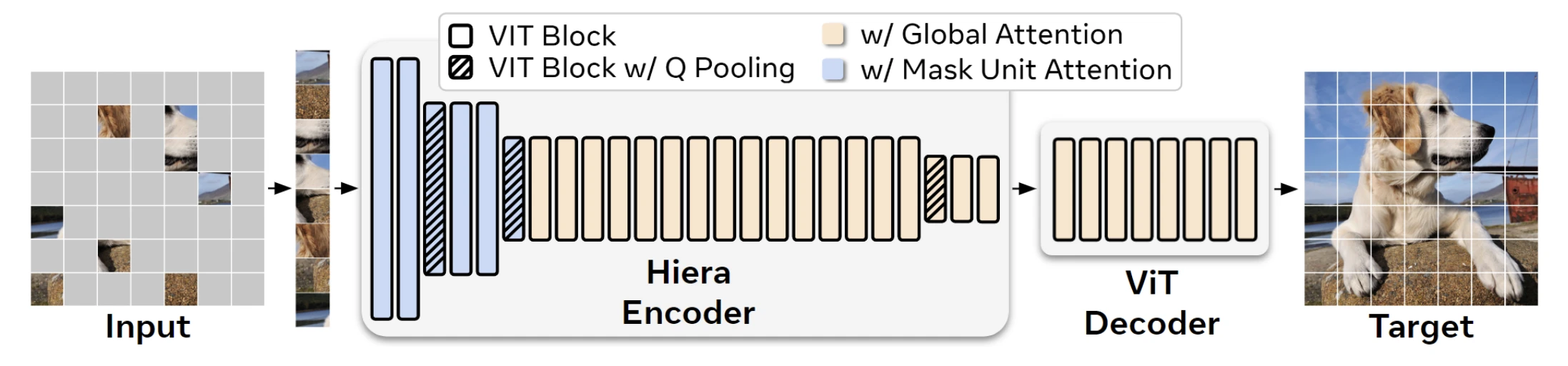
SAM이 plain ViT-H를 사용한 것과 달리, SAM 2는 Hiera라는 hierarchical vision transformer를 이미지 인코더로 채택했어요. Hiera는 MAE로 사전학습되며, 4개 stage에서 stride 4, 8, 16, 32의 multiscale feature를 출력해요.
이 중 stride 16과 32 feature(Stage 3, 4)가 FPN으로 결합되어 memory attention 모듈에 들어가요. Stride 4와 8 feature(Stage 1, 2)는 메모리 모듈을 거치지 않고 mask decoder의 업샘플링 레이어에 skip connection으로 직접 전달돼요. 고해상도 디테일을 살리기 위한 설계예요.
Memory는 네 가지 요소로 구성된다
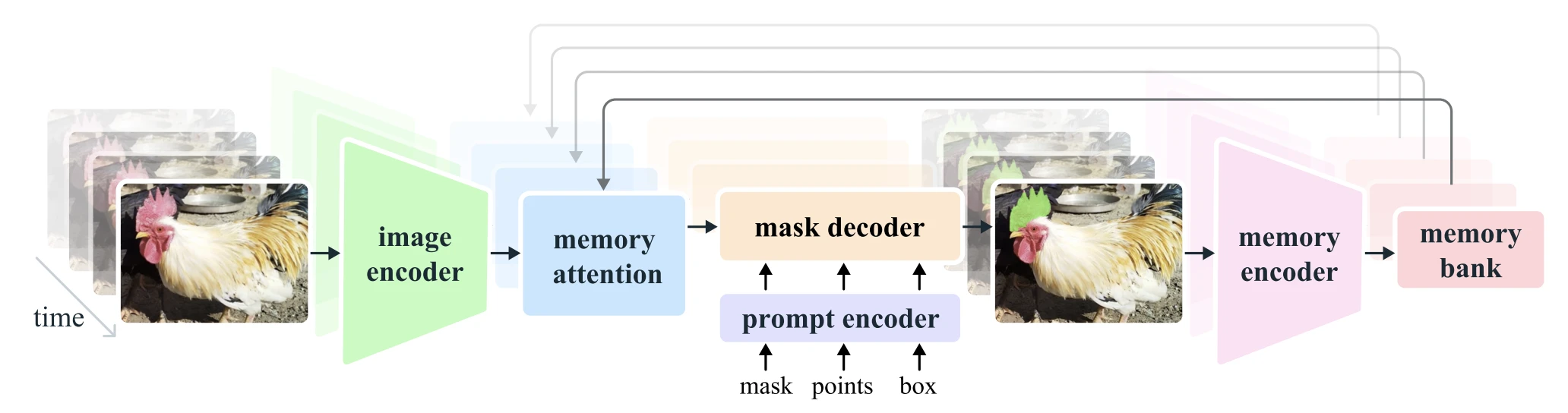
SAM 2의 memory 시스템은 memory encoder, memory bank, memory attention, 그리고 object pointer로 이루어져요.
Memory encoder는 현재 프레임의 예측 마스크를 convolution으로 다운샘플하고, 같은 프레임의 image embedding(메모리 attention을 거치기 전의 것)과 element-wise로 더한 뒤, 가벼운 conv 레이어로 fuse해서 하나의 memory feature map을 만들어요.
Memory bank는 두 개의 FIFO 큐를 운영해요. 하나는 최근 $N$개(기본 6개) unprompted 프레임의 memory이고, 다른 하나는 최근 $M$개 prompted 프레임의 memory예요. 두 큐 모두 spatial feature map 형태로 저장돼요.
Object pointer는 mask decoder의 출력 토큰에서 추출한 가벼운 벡터예요. 객체의 고수준 의미 정보를 담고 있어요. 256차원 벡터를 64차원 4개로 쪼개서 memory bank에 함께 저장해요.
Memory attention은 $L=4$개의 transformer 블록이에요. 각 블록은 self-attention → cross-attention → MLP 순서로 구성돼요. Cross-attention에서 query는 현재 프레임의 image embedding이고, key/value는 memory bank에 저장된 spatial feature map과 object pointer예요. 최근 unprompted 프레임에는 temporal positional embedding을 부여해 단기 동작을 모델링하고, prompted 프레임에는 부여하지 않아요.
SAM에는 없던 occlusion prediction head도 추가됐어요. 현재 프레임에 해당 객체가 존재하는지 예측하는 헤드예요. 비디오에서는 객체가 가려져서 아예 보이지 않는 프레임이 있을 수 있으니까요.
SAM 2는 이미지와 비디오를 함께 학습한다
SAM 2의 학습은 두 단계로 나뉘어요. 먼저 SA-1B 이미지로 pretraining한 뒤, 비디오 데이터를 포함한 full training을 진행해요.
Pretraining은 SAM과 유사해요. SA-1B에서 메모리 컴포넌트 없이 이미지 segmentation만 약 90K step 학습해요. 이미지 인코더는 MAE로 사전학습된 Hiera 가중치로 초기화해요. 손실은 SAM과 동일한 focal + dice 조합이지만, IoU 예측에는 MSE 대신 $\ell_1$ loss를 사용하고 sigmoid activation을 적용해 출력을 0~1로 제한해요.
Full training에서는 이미지와 비디오를 번갈아가며 학습해요. 매 iteration마다 이미지 배치 또는 비디오 배치를 데이터 크기에 비례하는 확률로 샘플링해요. 비디오는 8프레임 시퀀스를 뽑고, 최대 2프레임을 프롬프트 대상으로 지정해요. 첫 프롬프트는 50% 확률로 ground-truth 마스크, 25%로 positive 클릭, 25%로 bounding box를 사용해요. 이후 에러 영역에서 corrective 클릭을 샘플링하는 interactive simulation을 7라운드 반복해요.
손실은 네 가지를 선형 조합해요.
\[\mathcal{L} = 20 \cdot \mathcal{L}_{\text{focal}} + \mathcal{L}_{\text{dice}} + \mathcal{L}_{\text{IoU}} + \mathcal{L}_{\text{occ}}\]마스크 예측에 focal + dice(20:1), IoU 예측에 MAE loss, occlusion 예측에 cross-entropy loss를 각각 적용해요. Ground truth에 마스크가 없는 프레임(객체가 가려진 경우)에서는 마스크 loss를 계산하지 않고 occlusion 예측만 학습해요.
학습 데이터는 SA-V Manual + SA-1B의 10% 서브셋 + DAVIS, MOSE, YouTubeVOS 등 공개 VOS 데이터셋을 혼합해요. 비디오 augmentation으로 horizontal flip, affine transform, color jitter, grayscale, 그리고 같은 비디오를 2×2 그리드로 타일링하는 mosaic transform(10% 확률)을 사용해요. Mosaic은 비슷하게 생긴 복수 객체를 구별하는 능력과 작은 객체 segmentation 능력을 동시에 강화해요.
Full training 후에는 16프레임 시퀀스로 추가 fine-tuning을 진행해요. 어노테이터가 가장 많이 수정한 상위 50% masklet만 사용해, 모델이 어려운 케이스에 집중하도록 해요. 이 단계에서는 이미지 인코더를 freeze하고 50K iteration만 돌려요.
SAM 2의 효율 병목은 두 곳에 있다
SAM 2는 이미지에서 SAM보다 6배 빠르고, 비디오에서 기존 방법 대비 3배 적은 인터랙션으로 더 높은 정확도를 달성해요. 그런데 모바일 디바이스에 배포하기에는 두 가지 병목이 있어요.
첫째, Hiera 이미지 인코더가 무거워요. 기본 HieraB+가 약 80M 파라미터예요. Tiny 변형을 써도 hierarchical 구조 때문에 FPS가 거의 줄지 않아요. SAM 2 Tiny는 43.8 FPS, 기본 SAM 2는 47.2 FPS로 차이가 거의 없어요.
둘째, memory cross-attention의 토큰 수가 너무 많아요. Spatial memory token과 object pointer를 합치면 약 30K 토큰이에요. 매 프레임마다 이 긴 시퀀스에 대해 cross-attention을 수행해야 하니, 모바일에서는 이것이 진짜 병목이에요.
EfficientTAM은 인코더를 교체했다
Efficient Track Anything, ICCV 2025.
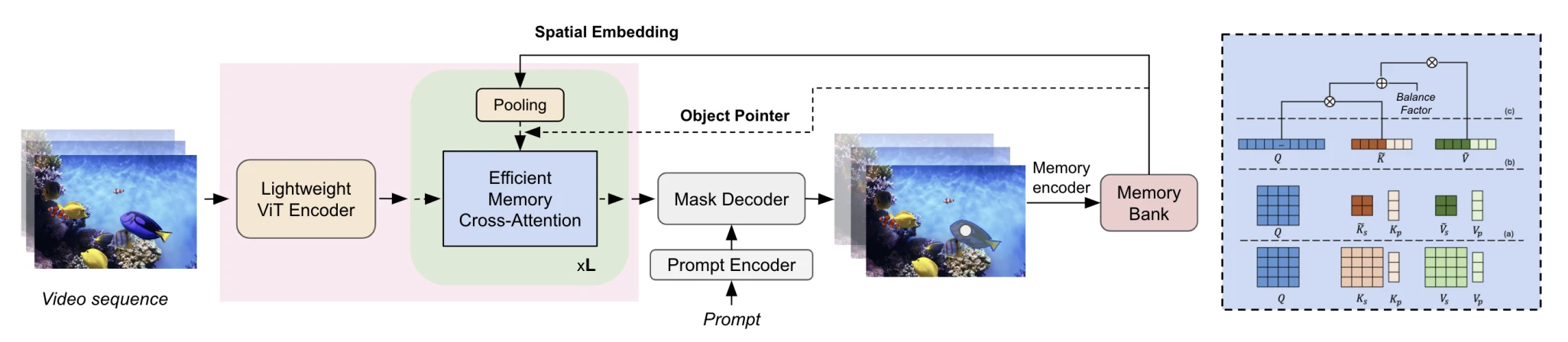
EfficientTAM은 SAM 2의 두 병목을 직접 공략해요. 첫 번째 해법은 Hiera를 plain ViT-Tiny 또는 ViT-Small로 교체하는 것이에요. Hierarchical 구조를 버리고 non-hierarchical 단일 스케일 인코더를 사용해요.
ViT의 초기 가중치는 EfficientSAM에서 도입된 SAMI 사전학습을 활용해요. SAMI는 SAM의 ViT-H를 teacher로 사용한 MAE 스타일 증류 기법이에요. 이 가중치로 초기화된 ViT-T/S에 14×14 non-overlapping windowed attention과 4개의 균등 간격 global attention 블록을 적용해요. 1024×1024 입력을 64×64 단일 스케일 embedding으로 변환하는 구조예요. SAM 2처럼 디코더에 multiscale skip connection을 추가하지 않아요.
Memory token에는 강한 locality가 있다
두 번째 해법이 이 논문의 핵심이에요. Memory cross-attention의 연산량을 줄이기 위해, 저자들은 memory spatial token의 locality를 관찰했어요.
표준 cross-attention은 다음과 같아요.
\[C(Q, K, V) = \mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V\]여기서 memory token은 spatial 부분 $K_s \in \mathbb{R}^{n \times d}$와 object pointer 부분 $K_p \in \mathbb{R}^{P \times d}$로 나뉘어요. 저자들은 인접한 spatial token들의 값이 매우 비슷하다는 것을 발견했어요. 수식으로 표현하면, 연속된 두 토큰 사이의 거리가 $|k_i - k_{i+1}|_2^2 \leq c_K / n^2$으로 충분히 작다는 거예요.
이 locality를 이용하면 $l_w \times l_h$ 크기의 윈도우 내 토큰들을 하나의 평균 토큰으로 대체해도 정보 손실이 작아요. 논문에서는 2×2 average pooling을 기본으로 사용해요.
Efficient cross-attention의 수식
풀링된 coarse key와 value를 $\tilde{K}_s$, $\tilde{V}_s$라 하고, object pointer 토큰과 합쳐 $\tilde{K} = [\tilde{K}_s;\, K_p]$, $\tilde{V} = [\tilde{V}_s;\, V_p]$로 만들어요. 효율적 cross-attention은 다음과 같아요.
\[\bar{C}(Q, K, V) = \mathrm{softmax}(A)\,\tilde{V}\] \[A = \left[\frac{Q\tilde{K}_s^\top}{\sqrt{d}} + \ln(l_w \cdot l_h),\;\; \frac{QK_p^\top}{\sqrt{d}}\right]\]여기서 $\ln(l_w \cdot l_h)$라는 상수가 spatial key 쪽 logit에 더해져요. 이 상수가 왜 필요한지 직관적으로 설명하면 이래요.
풀링하기 전, 같은 윈도우 안의 $l_w \times l_h$개 토큰은 거의 동일한 logit 값을 가졌어요. Softmax 분모에서 이 토큰들이 각각 기여하던 것이, 풀링 후에는 하나의 토큰으로 합쳐지면서 spatial 쪽의 attention 비중이 줄어들어요. 대신 object pointer 쪽으로 attention이 쏠리게 되죠. $\ln(l_w \cdot l_h)$를 더하면 softmax 내부에서 $e^{\ln(l_w \cdot l_h)} = l_w \cdot l_h$배의 가중치가 복원되어, 원래 cross-attention의 분포를 정확히 재현해요. 이 등가성은 논문의 appendix에서 증명되어 있어요.
논문은 또 하나의 변형도 제시해요. 상수를 logit이 아니라 key 자체에 더하는 형태예요.
\[\tilde{K} = [\tilde{K}_s + \ln(l_w \cdot l_h),\;\; K_p]\]두 변형의 성능 차이는 SA-V test에서 74.0 vs 73.9 J&F로 거의 없어요.
EfficientTAM의 학습도 두 단계로 나뉜다
EfficientTAM의 학습 파이프라인은 SAM 2와 동일한 pretraining → full training 구조를 따르지만 세부 설정이 달라요.
Pretraining 단계에서는 메모리 컴포넌트 없이 SA-1B에서 이미지 segmentation을 90K step 학습해요. 이미지 인코더는 SAMI 사전학습 가중치(EfficientSAM에서 제공)로 초기화해요. 손실은 focal + dice를 20:1로 조합하고, AdamW optimizer를 사용해요. 초기 learning rate 4e-4에 reciprocal square root schedule을 적용하며, layer-wise decay 0.8을 줘요. 256개 A100에서 bfloat16으로 학습해요.
Full training에서는 SA-V와 SA-1B 10% 서브셋을 사용해 300K step 학습해요. SAM 2와 달리 외부 데이터셋이나 내부 데이터를 사용하지 않아요. 이미지 인코더의 learning rate는 6e-5, 나머지 컴포넌트는 3e-4로 차등 적용해요. Cosine schedule과 15K iteration의 linear warmup을 사용해요. 비디오 augmentation은 SAM 2와 동일하게 horizontal flip, affine transform, color jitter, grayscale 등을 적용해요. 이미지당 최대 64개 마스크, 비디오 프레임당 최대 3개 마스크로 제한해요. 손실 함수는 SAM 2와 같은 focal + dice + IoU MAE + occlusion cross-entropy를 20:1:1:1 비율로 사용해요.
성능은 SAM 2에 근접하고 속도는 2배 빠르다
EfficientTAM-S는 SA-V test에서 74.5 J&F를 달성해요. SAM 2(HieraB+)의 74.7과 2점 이내의 차이예요. 5개 비디오 벤치마크 전반에서 이 패턴이 유지돼요. 파라미터는 34M으로 SAM 2(81M) 대비 약 2.4배 적어요.
| 모델 | 파라미터 | SA-V test J&F | A100 FPS | iPhone 15 Latency |
|---|---|---|---|---|
| SAM 2 (HieraB+) | 81M | 74.7 | 43.8 | - |
| EfficientTAM-S | 34M | 74.5 | 85.0 | 1010.8 ms |
| EfficientTAM-S/2 | 34M | 74.0 | 109.4 | 450 ms |
| EfficientTAM-Ti/2 | 18M | 70.8 | 109.4 | 261.4 ms |
EfficientTAM-S/2(efficient memory 적용)는 iPhone 15 Pro Max에서 약 10 FPS로 동작해요. 정확도 손실은 0.5 J&F뿐이지만 모바일 latency가 1010.8 ms에서 450 ms로 2배 이상 줄었어요. 이 차이가 memory cross-attention이 모바일 추론의 진짜 병목이었다는 것을 정량적으로 보여줘요.
이미지 segmentation에서도 EfficientTAM-S는 SA-23 벤치마크 1-click mIoU 60.7%로, SAM(ViT-H)의 59.1%를 넘으면서 A100에서 약 20배 빠르고 파라미터도 약 20배 적어요.
Ablation이 알려주는 것
논문의 ablation 실험에서 몇 가지 중요한 결론이 나와요.
Object pointer는 반드시 유지해야 해요. Cross-attention에서 object pointer를 제외하면 SA-V test J&F가 74.5에서 72.1로 2.4점 하락해요. 이 결과는 SAM 2의 ablation과도 일치해요.
풀링 대상을 구분해야 해요. Spatial token만 풀링하고 object pointer는 그대로 두어야 해요. 전체를 한꺼번에 풀링하면 2.3 J&F 하락이 발생해요.
윈도우 크기 2×2가 최적이에요. 4×4로 키우면 약 1 J&F 하락이 생기면서 속도 향상은 미미해요.
Linear attention은 이 문제에 적합하지 않아요. Performer나 EfficientViT 스타일의 linear attention을 memory cross-attention에 적용하면 SA-V test에서 10 J&F 이상 큰 폭의 하락이 발생해요. Token의 구조를 활용한 풀링이 단순 근사보다 훨씬 효과적이라는 것을 보여줘요.
세 모델의 비교
| SAM | SAM 2 | EfficientTAM | |
|---|---|---|---|
| 이미지 인코더 | ViT-H (plain) | Hiera (hierarchical) | ViT-T/S (plain) |
| 비디오 지원 | X | O (streaming memory) | O (streaming memory) |
| Memory cross-attention | - | 표준 (∼30K 토큰) | 2×2 pooling (∼7.5K 토큰) |
| SA-1B 학습 | O | O | O |
| SA-V 학습 | X | O | O |
| 모바일 배포 | 어려움 | 어려움 | 가능 (∼10 FPS) |
SAM이 promptable segmentation이라는 패러다임을 만들었고, SAM 2가 streaming memory로 비디오로 확장했으며, EfficientTAM은 plain ViT 인코더와 locality 기반 efficient cross-attention으로 이 파이프라인을 모바일에서 실행 가능하게 만들었어요. 정확도를 거의 유지하면서 모델을 2.4배 작게, 추론을 2배 빠르게 만든 것이 핵심 기여예요.