THINK-ON-GRAPH, 그래프를 활용한 정보 탐색
Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Generation, ICLR 2025, arXiv.
복잡한 질문에 답하려면 흩어진 단서를 모으고, 단서끼리의 관계를 따라가야 해요. 사람은 이 과정을 자연스럽게 하지만, RAG는 여기서 자주 막혀요. Think-on-Graph 2.0(ToG-2)은 Knowledge Graph와 텍스트 문서를 번갈아 탐색하며 이 문제를 풀어요.
기존 RAG는 왜 복잡한 추론에서 막힐까
먼저 세 가지 RAG 방식의 한계를 정리할게요.

Text-based RAG는 질문과 문서를 vector로 임베딩해 유사도로 검색해요. 의미가 비슷한 문서는 잘 찾지만, 서로 다른 문서에 흩어진 entity 사이의 관계는 놓쳐요. 예를 들어 “기생충”과 “Parasite”가 같은 작품을 가리킨다는 사실은 표면적 유사도만으로 연결하기 어려워요. 그래서 multi-step 추론이나 단서 간의 논리적 연결에는 약해요.
KG-based RAG는 entity와 relation을 triple로 저장해 구조적 관계를 다뤄요. 고수준 개념을 연결하는 데 강하지만, KG 자체가 불완전해요. Ontology 밖의 세부 정보는 담기 어려워서, 어떤 영화의 구체적인 흥행 수익 같은 디테일은 제공하지 못해요.
Hybrid RAG는 둘을 합쳐요. 다만 대부분은 KG와 텍스트에서 각각 검색한 결과를 그냥 모아서(loose-coupling) LLM에 넣어요. 한 쪽의 검색 결과가 다른 쪽의 검색을 개선하지 못해요. 깊은 검색이 필요한 복잡한 질문에서는 여전히 부족해요.
KG로 문서를, 문서로 KG를 검색하자
ToG-2의 핵심은 두 가지예요. (1) KG가 entity를 통해 문서를 연결해서, 의미 공간에서 멀어 보이는 단서까지 깊게 따라가는 context retrieval을 가능하게 해요. (2) 반대로 문서를 entity의 context로 사용해서, 어떤 entity가 질문과 관련 있는지 정확하게 판단하는 graph retrieval을 가능하게 해요. 이 두 과정을 한 번에 끝내지 않고 반복해요. Graph search로 후보 entity를 넓히고, context retrieval로 다시 추리고, 충분한지 판단하고, 부족하면 더 깊게 파요. 사람이 기존 지식 틀 위에서 단서를 살피며 관련 entity를 떠올리고 답을 찾을 때까지 파고드는 과정과 닮았어요.
추가 학습이 필요 없어서 training-free이고, 다양한 LLM에 그대로 붙일 수 있는 plug-and-play 구조예요.
Multi-hop Reasoning 살펴보기
예시 질문으로 흐름을 그려볼게요. “기생충을 감독한 사람이 그다음으로 만든 장편 영화의 주연 배우는 누구인가요?”

이 질문은 한 번에 답이 안 나와요. 단서를 여러 번 건너뛰어야(multi-hop) 해요.
- 출발점: 질문에서 “기생충”을 topic entity로 잡아요.
- Graph search 1:
기생충 —(감독)→ 봉준호triple로 감독을 찾아요. “배급사” 같은 무관한 relation은 prune돼요. - Graph search 2:
봉준호 —(감독작)→ {기생충, 미키 17, …}으로 작품 후보를 넓혀요. - Context retrieval: “그다음으로 만든”이라는 시간 순서는 triple만으로 알기 어려워요. 봉준호와 각 작품 문서의 context에서 개봉 순서를 확인해 다음 작품 entity를 골라요. 나머지 후보는 prune돼요.
- 마지막 hop: 고른 작품 entity의
—(주연)→관계와 문서 context로 배우를 확정하고 답해요.
핵심은 graph가 “감독 → 작품 → 배우”라는 뼈대를 놓고, 문서 context가 “그다음”처럼 triple에 없는 디테일을 채운다는 점이에요. 이게 graph search와 context retrieval을 번갈아 반복하는 이유예요. 아래에서 각 단계를 수식과 함께 자세히 볼게요.
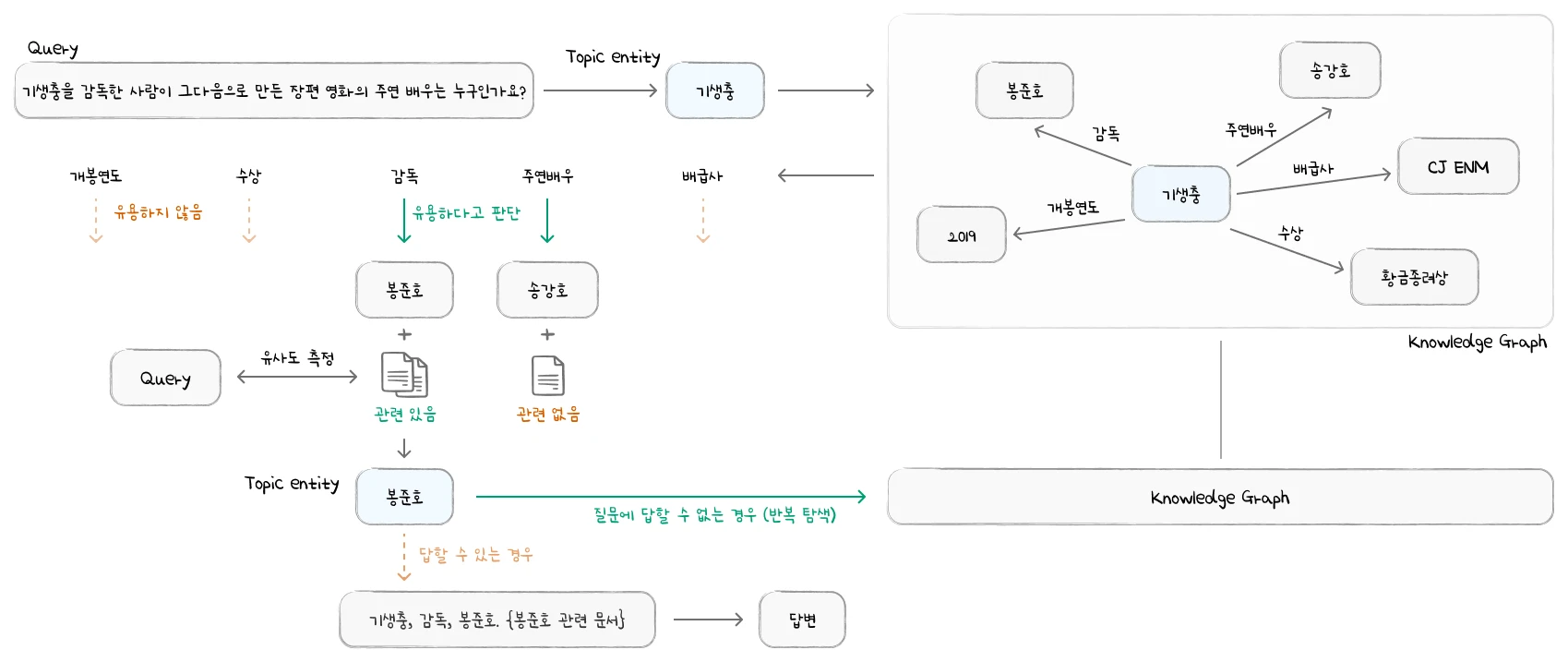
시작점은 어떻게 정할까
질문 $q$가 주어지면 ToG-2는 먼저 질문 속 entity를 찾아 KG의 entity에 연결해요(entity linking). 이때 LLM을 쓰거나 전용 entity linking 도구를 써요.
그다음 Topic Prune(TP) 단계에서 LLM이 질문과 entity들을 보고, 그래프 탐색의 출발점으로 적절한 entity만 골라요. 선택된 집합을 $E^0_{topic} = {e_1, e_2, \dots, e_N}$로 표기하고, 개수 $N$은 LLM이 정해요. 너무 넓은 entity(예: “영화” 같은 일반 개념)는 출발점에서 빠져요.
첫 graph retrieval 전에, dense retrieval model(DRM)로 초기 topic entity의 문서에서 top-k chunk를 먼저 뽑아요. 그리고 LLM이 자신의 지식과 이 정보만으로 답할 수 있는지 판단해요. 충분하면 여기서 멈춰요. 굳이 그래프를 탐색하지 않아요.
그래프를 따라 후보 entity를 넓힌다
여기서부터 반복 과정이에요. $i$번째 iteration의 topic entity를 $E^i_{topic} = {e^i_1, e^i_2, \dots, e^i_j}$로, 여기까지 쌓인 triple path를 $P^{i-1}$로 둘게요. $W$는 exploration width로, 각 iteration에서 유지할 topic entity의 최대 개수예요.
Relation Discovery. 각 topic entity $e^i_j$에 대해 연결된 relation을 모아요.
\[Edge(e^i_j) = \{(r^i_{j,m}, h_m) \mid h \in \{\text{True}, \text{False}\}\}\]$h$는 relation의 방향이 topic entity를 향하는지 나타내요. KG의 edge는 양방향 모두 탐색해요.
Relation Prune(RP). 모인 relation 중에서 LLM이 질문에 도움이 될 만한 것을 골라 점수를 매겨요. Prompt 방식은 두 가지예요. 하나는 topic entity마다 LLM을 따로 호출하는 방식이에요. 작업이 단순해지지만 호출이 많아 느려요. 다른 하나는 모든 topic entity의 relation을 한 번에 처리하는 combination 방식이에요. API 호출이 줄어 빠르고, 여러 추론 경로의 연결성을 함께 고려할 수 있어요. 다만 relation이 너무 많이 모이면 약한 LLM은 긴 입력을 처리하기 버거워요.
이때 낮은 점수의 relation은 제거돼요. 예를 들어 봉준호의 차기작을 찾는 질문에서 “출생지” 같은 relation은 답과 무관할 가능성이 높아 잘려요. 논문의 주요 실험은 효율을 위해 combination 방식을 기본으로 써요.
Entity Discovery. 살아남은 relation을 따라 연결된 entity를 찾아요.
\[Tail(e^i_j, (r^i_{j,m}, h_m)) = c^i_{j,m}\]이렇게 얻은 ${c^i_{j,m}}$이 이번 iteration의 후보 entity예요. 아직 추리지 않은 상태로, 다음 단계에서 문서를 근거로 걸러요.
문서로 entity를 다시 추린다
이번에는 KG가 안내한 후보 entity의 문서를 파고들어요. 각 후보 entity $c^i_{j,m}$의 관련 문서를 모아 context pool을 만들어요.
Entity-guided Context Retrieval. 문서 chunk의 관련도를 DRM으로 계산해요. 이때 chunk와 질문만 비교하지 않아요. 그러면 chunk가 어떤 entity에서 왔는지가 무시되거든요. 그래서 후보 entity로 이어지는 triple $(e^i_j, r^i_{j,m})$을 짧은 문장으로 바꿔 chunk 앞에 붙인 뒤 점수를 계산해요.
\[s^i_{j,m,z} = \text{DRM}(q, [\text{triple_sentence}(Pc^i_{j,m}),\ \text{chunk}^i_{j,m,z}])\]Triple 정보를 함께 넣어서, 같은 chunk라도 어떤 관계를 거쳐 도달했는지가 점수에 반영돼요. 상위 $K$개 chunk를 $Ctx^i$로 골라 추론 근거로 써요.
Context-based Entity Prune. 후보 entity의 점수는 그 entity가 가진 chunk들의 점수로 정해요. 여기서 chunk 점수는 새로 계산하지 않고, 앞 단계에서 DRM이 매긴 관련도 점수 $s$를 그대로 재사용해요. 모든 후보의 chunk를 한데 모아 점수순으로 정렬한 뒤, 상위 $K$개를 보고 순위가 낮을수록 가중치를 지수적으로 줄여 합산해요.
\[score(c^i_{j,m}) = \sum_{k=1}^{K} s_k \cdot w_k \cdot \mathbb{I}(\text{$k$-th chunk from } c^i_{j,m}), \quad w_k = e^{-\alpha k}\]$s_k$는 전역 순위로 $k$번째인 chunk의 DRM 점수, $\mathbb{I}$는 해당 chunk가 그 entity의 것이면 1인 지시 함수, $\alpha$는 감쇠 정도를 정하는 hyperparameter예요. 즉 entity 점수는 자기 chunk가 받은 점수만 골라 decay 가중합한 값이에요. 점수가 높은 상위 $W$개 entity가 다음 iteration의 topic entity $E^{i+1}_{topic}$이 돼요. 문서 근거가 약한 후보는 여기서 잘려요.
이 단계가 tight-coupling의 핵심이에요. KG가 후보를 넓히면, 문서가 그 후보의 관련도를 평가해 다음 graph 탐색의 출발점을 정해요. 그래프와 텍스트가 서로의 검색을 직접 이끌어요.
충분하면 답하고, 아니면 다시 검색
Iteration이 끝나면 LLM에게 지금까지 모은 지식을 모두 줘요. 직전 iteration의 단서 $Clues^{i-1}$, triple path, 상위 entity, 그리고 해당 context chunk를 함께 넣어요. $Clues^{i-1}$은 이전 검색의 피드백으로, 유용한 지식을 다음 단계로 이어가는 역할을 해요.
\[\text{PROMPT}_{rs}(q, P^i, Ctx^i, Clues^{i-1}) = \begin{cases} \text{Ans.}, & \text{if knowledge is sufficient} \\ Clues^i, & \text{otherwise} \end{cases}\]지식이 충분하면 바로 답을 내요. 부족하면 LLM이 지금까지의 지식에서 도움이 될 단서 $Clues^i$를 요약하고, 정확한 정보를 바탕으로 query를 다시 다듬어요. 그리고 다음 iteration으로 넘어가요. 이 반복은 최대 깊이 $D$에 도달할 때까지 이어져요.
실험 결과
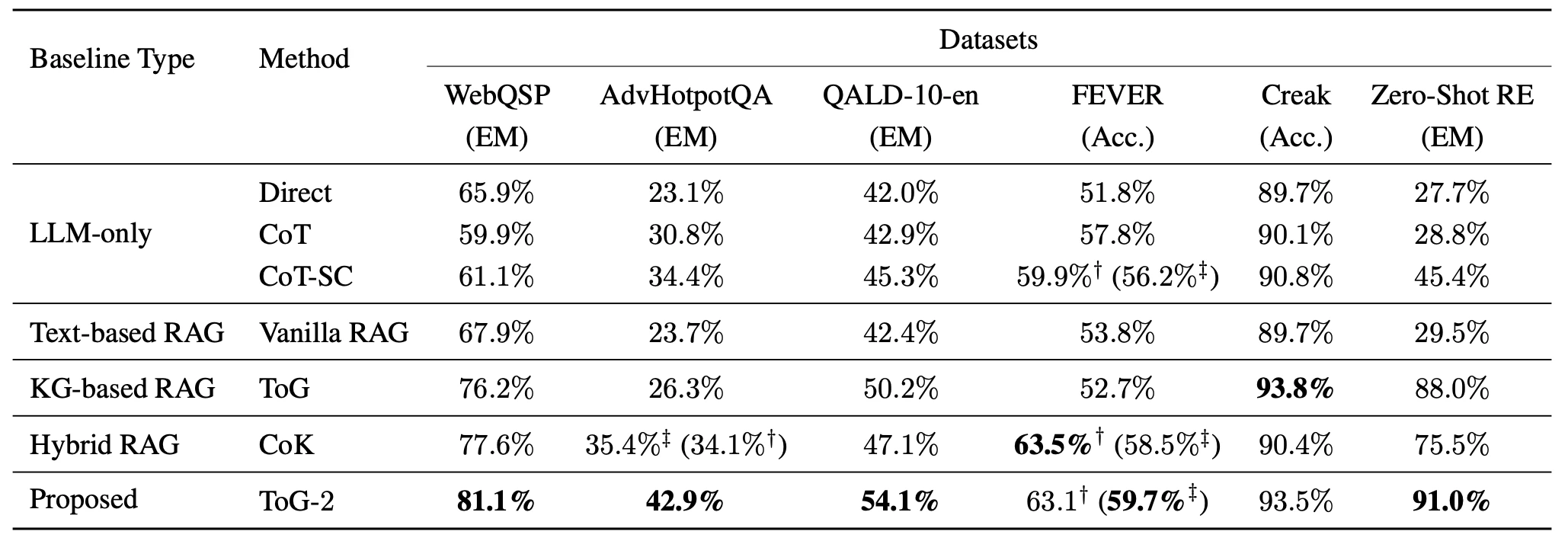
ToG-2는 GPT-3.5 기준으로 7개 knowledge-intensive 데이터셋 중 6개에서 SOTA를 기록해요. 특히 multi-hop 추론 데이터셋인 AdvHotpotQA에서 기존 ToG 대비 16.6%p 올랐어요. 반면 단일 hop 관계만 다루는 FEVER나 Creak에서는 깊은 검색의 이점이 작아 차이가 크지 않아요. 깊은 검색이 필요한 질문에서 강하다는 뜻이에요.
작은 모델을 끌어올리는 효과도 있어요. Llama-3-8B나 Qwen2-7B에 ToG-2를 붙이면, GPT-3.5의 direct reasoning 수준까지 성능이 올라가요. 지식과 이해의 병목을 검색으로 메워주기 때문이에요.
Domain-specific 평가를 위해 만든 ToG-FinQA에서도 의미가 컸어요. LLM이 사전학습 때 보지 못한 2023년 중국 재무제표를 다루는데, vanilla RAG와 CoT는 0%에 그쳤어요. Loose-coupling인 GraphRAG도 6.2%에 머물렀고, ToG-2는 34%를 기록했어요. 단순 결합으로는 KG의 안내를 받는 multi-hop 검색을 못 한다는 점을 보여줘요.
Triple를 따라 문서를 가져온다
ToG-2가 KG와 텍스트를 정말 함께 활용하는지 확인하려고, 논문은 AdvHotpotQA 추론 결과 50건을 무작위로 뽑아 사람이 직접 분석했어요. 각 정답이 triple link 추론과 entity의 문서 context 중 무엇에서 단서를 얻었는지 네 유형으로 나눴어요.
가장 많은 유형은 entity의 문서 context가 단서가 된 doc-enhanced로 약 42%였어요. Triple link와 문서 context가 함께 기여한 both-enhanced가 약 32%로 뒤를 이었어요. 추가 정보 없이 LLM이 바로 답한 direct는 약 16%, triple link만으로 답한 triple-enhanced는 가장 적었어요.
여기서 두 가지를 읽을 수 있어요. 첫째, 복잡한 QA에서는 문서 context가 가장 중요한 단서예요. Triple만으로는 디테일이 부족해서 깊은 통찰을 주기 어렵고, 그 역할은 거시적인 길잡이에 가까워요. 둘째, both-enhanced 비중이 큰 만큼, triple link 추론과 entity 문서를 결합하는 패턴이 효과적이에요. Direct가 16%에 그친다는 점은, 복잡한 질문에서 LLM이 스스로 답할 수 있는 경우가 적고 검색 파이프라인에 크게 기대고 있음을 보여줘요.
논문은 두 사례로 이를 구체화하는데, 같은 영화 질문으로 옮겨볼게요. Both-enhanced에서는 triple link로 기생충 →(감독)→ 봉준호 →(감독작)→ 차기작까지 뼈대를 세우고(triple 기여), 차기작 문서의 context에서 주연 배우를 확정해요(문서 기여). Triple이 길을 열고 문서가 답을 채우는 구조예요. Doc-enhanced에서는 triple link를 봉준호의 작품으로 가는 길잡이로만 쓰고, “그다음 작품”의 개봉 순서와 주연 같은 최종 정보는 전적으로 문서 context에서 찾아요.
ToG-2와 CoT의 출력을 비교한 분석도 있어요. ToG-2는 깊은 검색을 거치므로 CoT보다 hallucination이 줄어요. 또 지식이 부족하면 답을 단정하지 않고 거부하는 경향이 강해요. 다만 EM으로 채점할 때 false negative가 꽤 나와요. 답은 맞는데 표기 차이나 모호한 라벨 때문에 오답으로 처리되는 경우예요. 평가 지표가 성능을 과소평가할 여지가 있다는 뜻이고, 방법 자체에는 아직 끌어올릴 여지가 남아 있어요.
정리
ToG-2는 KG와 텍스트를 단순히 합치는 대신, 서로의 검색을 직접 돕도록 묶었어요. KG는 entity로 문서를 연결해 깊은 context retrieval을 안내하고, 문서는 entity의 context가 되어 정확한 graph retrieval을 가능하게 해요. 두 과정을 충분한 답이 나올 때까지 반복하면서, 학습 없이도 복잡한 추론 성능을 끌어올려요. RAG에서 “무엇을 검색하느냐”만큼 “두 지식원을 어떻게 엮느냐”가 중요하다는 점을 잘 보여주는 연구예요.